伯克利人工智能研究实验室(BAIR)博客近日介绍了一种使用神经网络动态的基于模型的强化学习方法,该方法能够非常高效地利用数据,能让强化学习智能体使用少量数据就学会轨迹跟踪。除了模拟实验,他们还在真实机器人上进行了评估,让一个机器人只用 17 分钟数据就学会了轨迹跟踪。机器之心对介绍这项研究的博客文章进行了编译介绍,相关论文和代码可在文末查阅。

图 1:一个学习后的神经网络动态模型能让六足机器人学习奔跑和遵照所需的轨迹运动,这个学习仅使用了 17 分钟的真实经验。
让机器人在真实世界自动行动是很困难的。真的非常非常困难。即使有昂贵的机器人和世界级的研究团队,机器人仍然还难以在复杂的非结构化环境中自动导航和交互。
为什么我们身边还没有自动机器人。要做出能够应付我们这个世界的复杂性的工程系统是非常艰难的。
从非线性的动态和局部可观测性到不可预测的地形和传感器故障,机器人尤其容易受到墨菲定律的影响,即任何可能出错的事情都会出错。我们没有通过编码我们的机器人可能遇到的每种场景来对抗墨菲定律,而是选择了拥抱这种失败的可能性并让我们的机器人可以从中学习。从经验中学习控制策略是很有好处的,因为和人工设计的控制器不同,通过学习得到的控制器可以适应更多数据并随之改善进步。因此,当机器人面对一个任何事都可能出错的场景时,尽管它仍会出错,但经过学习的控制器有望在下一次遇到相似场景时纠正这些错误。
为了应对真实世界中的任务的复杂性,当前的基于学习的方法通常会使用深度神经网络,这种方法很强大但在数据方面不是很高效:这些基于试错方法的学习器多半第二次、第三次还会出错,而且往往会出错数千到数百万次之多。现代深度强化学习方法的这种样本低效性是基于学习的方法在真实世界中应用的主要瓶颈之一。
我们研究了使用神经网络控制机器人的可以高效利用样本的基于学习的方法。对于复杂的并且会进行大量接触的仿真机器人和真实机器人(图 1)来说,我们的方法可以仅使用几分钟的数据就能学会跟踪轨迹的运动技能,而且这几分钟的数据是该机器人在该环境中随机行动而收集到的。在这篇博客中,我们将概述性地介绍我们的方法和结果。你可以在文末列出的研究论文中查看更多细节和代码。
样本高效性:无模型方法与基于模型的方法
根据经验学习机器人技能通常是在强化学习的领域内。强化学习算法一般可以分为两大类:无模型方法(学习一个策略或价值函数)和基于模型的方法(学习一个动态模型)。尽管无模型深度强化学习算法可以学习很多类型的机器人技能,但它们往往会有非常高的样本复杂度、通常需要数百万样本才能得到优良的表现并且通常一次只能学习一个任务。尽管之前已经有一些研究将这些无模型算法用在了真实的操作任务上,但这些算法的高样本复杂度和不灵活性妨碍了它们被用在真实世界中学习运动技能。
基于模型的强化学习算法通常被认为能更有效地利用样本。但为了实现优良的样本效率,从传统上看,这些基于模型的算法要么使用了相对简单的函数近似器(不能很好地泛化到复杂任务),要么就使用了高斯过程等概率动态模型(可以很好地泛化,但难以应对复杂和高维的领域,比如带有会导致不连续动态的摩擦接触的系统)。相反,我们使用了中等规模的神经网络来作为可以实现出色样本效率的函数近似器,同时仍然有足够的表现能力可以泛化和应用到各种复杂和高维的运动任务上。
基于模型的深度强化学习的神经网络动态
在我们的工作中,我们的目标是将深度神经网络模型在其它领域的成功扩展到基于模型的强化学习领域。最近几年将神经网络与基于模型的强化学习结合起来的工作没能实现与更简单的模型(比如高斯过程)相媲美的结果。比如,Gu et. al. 观察到甚至线性模型也能在合成经验生成(synthetic experience generation)上得到更好的表现,而 Heess et. al. 则发现将神经网络纳入无模型学习系统中只能得到相对较少的增益。我们的方法取决于几个关键决定。首先,我们在一个模型预测控制框架中使用了这个学习得到的神经网络模型,其中系统可以迭代式地重新规划和纠正自己的错误。其次,我们使用了一个相对较短的视野预测(horizon look-ahead),这样我们就不必依赖于模型去执行深入未来的非常精准的预测。这两种相对简单的设计决定让我们的方法可以执行范围广泛的运动任务,这些任务之前还没使用直接在原始状态观察上运行的通用的基于模型的强化学习方法完成过。
我们的基于模型的强化学习方法如图 2 所示。我们保持着一个迭代式地添加内容的轨迹数据集,我们使用这个数据集来训练我们的动态模型。该数据集使用了随机轨迹进行初始化。然后我们使用该数据集训练神经网络动态模型并使用我们学习到的动态模型收集额外的轨迹以聚合到该数据集上,我们通过交替这两个过程执行强化学习。我们将在下面讨论这两个组件。
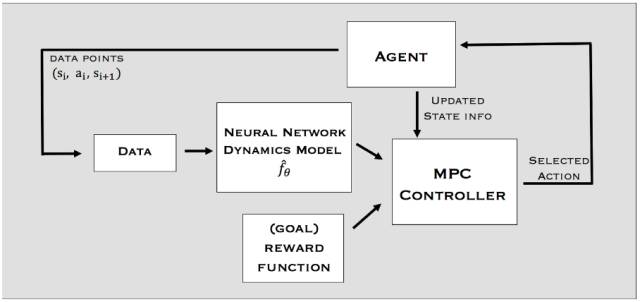
图 2:我们的基于模型的强化学习算法的概览。
动态模型
我们将我们学习到的动态函数参数化为了一个深度神经网络,这个参数化过程所用到的一些权重需要通过学习得到。我们的动态函数以当前状态 s_t 和动作 a_t 为输入,然后输出预测 。该动态模型本身可以在监督式学习设置中进行训练,其中收集到的训练数据以输入 (s_t,a_t) 和对应的输出标签 的方式成对出现。
注意我们上面所说的「状态」可能会随智能体而变化,而且它的元素可能包含质心位置、质心速度、关节位置和其它我们选择包含进来的可测量。
控制器
为了使用学习到的动态模型完成任务,我们需要定义一个编码该任务的奖励函数。比如,标准的 x_vel 奖励可以编码向前运动的任务。对于跟随轨迹的任务,我们构建了一个鼓励靠近轨迹同时沿轨迹向前运动的奖励函数。
使用这个学习到的动态模型和任务奖励函数,我们构建了一个基于模型的控制器。在每个时间步骤,该智能体都通过随机生成 K 个候选动作序列来规划未来的 H 个步骤,这个过程使用了学习到的动态模型来预测这些动作序列的结果,然后选择其中对应于最高累积奖励的序列(图 3)。然后我们仅执行该动作序列中的第一个动作,然后再在下一个时间步骤重复这个规划过程。这个重新规划过程使得该方法能稳健地应对这个学习到的动态模型中的不准确性。

图 3:这个过程的图示:使用学习到的动态模型模拟多个候选动作序列、预测它们的结果、根据奖励函数选出其中最好的一个。
结果
我们首先在一些不同的 MuJoCo 智能体上对我们的方法进行了评估,包括游泳智能体、半猎豹智能体和蚂蚁智能体。图 4 表明:使用我们学习到的动态模型和 MPC 控制器,这些智能体可以沿由一组稀疏的路径点定义的路径运动。此外,我们的方法仅需要使用几分钟的随机数据来训练学习到的动态模型,这表明它能很有效地利用样本。
注意,我们使用这种方法只训练了该模型一次,但是简单地通过修改奖励函数,我们可以在运行时将该模型应用到各种不同的所需轨迹上,而无需再单独针对特定任务进行训练。

图 4:蚂蚁智能体、游泳智能体和半猎豹智能体的轨迹跟踪。每个智能体为跟随这些不同的轨迹所使用的动态模型都只训练了一次,并且都只使用了随机收集的训练数据。
我们的方法中的哪些方面对表现优良而言很重要呢?我们首先检查了改变 MPC 规划视野 H 所造成的影响。图 5 表明如果视野太短会给表现得到负面影响,这可能是因为存在无法恢复的贪婪行为(greedy behavior)。对于半猎豹智能体,如果视野太长也会带来负面影响,因为学习到的动态模型中存在不准确性。图 6 给出了我们学习到的动态模型单次 100 步预测,表明对特定状态元素的开环预测最终会偏离 ground truth。因此,为了在避免贪婪行为的同时最小化不准确模型的不利影响,使用适中的规划视野最好。
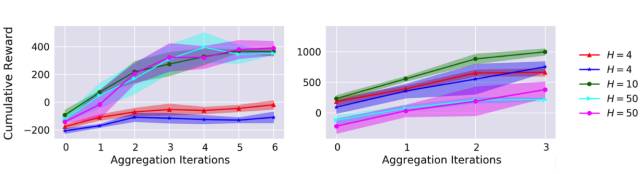
图 5:控制器为规划使用不同的视野值所得到的任务表现图。视野太低不好,太高也不好。
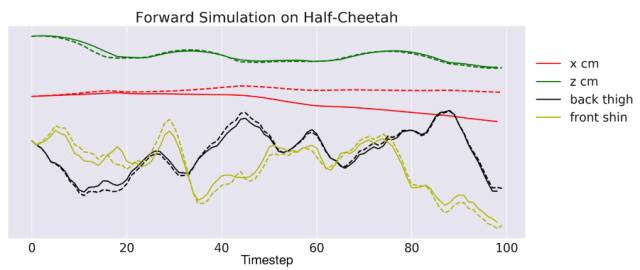
图 6:该动态模型的 100 步前向模拟(开环),表明为特定状态元素进行的开环预测最终会偏离 ground truth。
我们还改变了用于训练动态模型的初始随机轨迹的数量。图 7 表明:尽管更多的初始训练数据可以得到更好的初始表现,但数据聚合还是允许少数据的初始实验运行达到较高的最终表现水平。这显著突出了来自强化学习的在策略数据(on-policy data)可以如何提升样本效率。
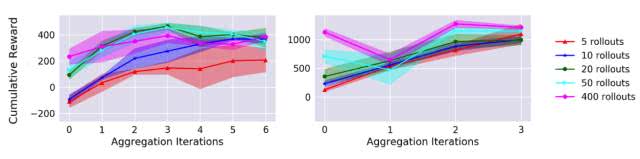
图 7:使用不同数量的初始随机数据训练的动态模型所实现的任务表现图。
需要指出,这种基于模型的控制器的最终表现仍然显著低于非常好的无模型学习器(此时无模型的学习器使用的数据要多数千倍)。这种次优的表现有时被称为「模型偏差(model bias)」,是基于模型的强化学习领域的一个已知问题。为了解决这个问题,我们也提出了一种将基于模型的和无模型的学习结合起来的混合方法,从而消除了收敛时的渐进偏差(asymptotic bias),但这需要额外的经验。这种混合方法及更多其它分析可在我们的论文中查看。
学习在真实世界中运行

图 8:VelociRoACH 长 10cm,重大约 30 克,每秒可移动长达 27 个机体长度,并且使用了 2 个电机来控制全部 6 条腿。
因为我们的基于模型的强化学习算法可以使用比无模型算法少几个数量级的经验来学习运动步态,所以我们可以直接在真实的机器人平台上对其进行评估。在另一项工作中,我们研究了这种方法可以如何完全从真实经验中学习,从而完全从头开始为一个毫米机器人(图 8)学习运动步态。
毫米机器人(millirobot)由于尺寸小和生产成本低,所以是很多应用的理想平台。但是,因为这些毫米机器人有欠驱动(underactuation)、功率限制和尺寸上的问题,所以控制它们是很困难的。尽管人工设计的控制器有时候可以控制这些毫米机器人,但它们往往难以应付动态的策略和复杂的地形。因此我们利用了前面提到的基于模型的学习技术来让 VelociRoACH 毫米机器人学习轨迹跟踪。图 9 表明我们的基于模型的控制器只使用 17 分钟的随机数据进行训练,就可以高速准确地跟踪轨迹。

图 9:使用我们的基于模型的学习方法,VelociRoACH 沿各种所需的轨迹运动。
为了分析该模型的泛化能力,我们收集了地毯(carpet)和聚苯乙烯泡沫塑料(styrofoam)地形的数据,然后我们评估了我们的方法,如表 1 所示。和预期的一样,当在与训练所用的地形相同的地形上执行时,基于模型的控制器的表现最优,说明该模型能够整合关于地形的知识。但是,当该模型在从这两种地形上收集到的数据上同时训练时,其表现会下降,这很可能表明为了开发算法来构建在多种不同任务设置上都有效的学习模型,还需要进行更多的研究。表 2 很有希望地表明当使用更多数据训练这种动态模型时,其表现会提升,这说明我们的方法会随时间持续改善(这和人工设计的解决方案不一样),这是个非常鼓舞人心的结果。
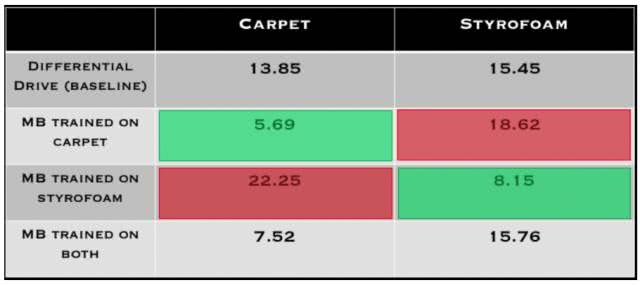
表 1:使用不同类型的数据训练模型以及让该模型在不同的表面上执行时所产生的轨迹跟踪成本。
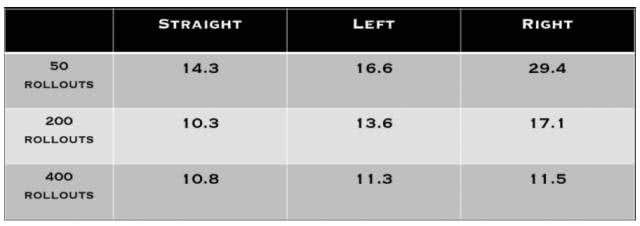
表 2:使用不同数量的数据和不同的腿训练得到的动态模型在应用期间所产生的轨迹跟踪成本。
我们希望这些结果能体现基于模型的方法在高效利用样本的机器人学习上的潜力并激励这一领域的未来研究。
原文地址:http://bair.berkeley.edu/blog/2017/11/30/model-based-rl/