常用数学公式
-
- 古典概型
- 概率公式
- 条件概率
- 全概率公式
- 贝叶斯公式
- 分布
- 两点分布(0-1分布/伯努利分布)
- 二项分布
- 泊松分布
- 定义
- 概率分布函数为:
- 期望:
- 方差:
- 分布图形
- 指数分布
- 分布函数
- 无记忆性
- 均匀分布
- 正态分布
- 定理
- 定义
- 一维正态分布
- 标准正态分布
古典概型
- 定义:
(1) 试验中所有可能出现的基本事件只有有限个;
(2) 试验中每个基本事件出现的可能性相等。
具有以上两个特点的概率模型是大量存在的,这种概率模型称为古典概率模型,简称古典概型,也叫等可能概型。 - 概率公式:
P(A)=mn=A包含的基本事件的个数m基本事件的总数n P ( A ) = m n = A 包 含 的 基 本 事 件 的 个 数 m 基 本 事 件 的 总 数 n
概率公式
条件概率
全概率公式
贝叶斯公式
给定某系统的若干样本x,计算该系统的参数,即
P(θ) P ( θ ) :没有数据的支持下, θ θ 发生的概率:先验概率。例如:在没有任何信息的前提下,猜测某人姓氏:先猜测李王张刘……猜对的概率比较大
P(θ|x) P ( θ | x ) :在数据的支持下, θ θ 发生的概率:后验概率。若知道某人来自“刘家村”,则他姓刘的概率比较大
P(x|θ) P ( x | θ ) :给定某参数 θ θ 的概率分布:似然函数
分布
两点分布(0-1分布/伯努利分布)
已知随机变量X的分布律为:
则有:
二项分布
设随机变量 X X 服从参数为 n,p n , p 二项分布,
1. 设 Xi X i 为第 i i 次实验中事件 A A 发生的次数, i=1,2,...,n i = 1 , 2 , . . . , n
则
显然, Xi X i 相互独立均服从参数为 p p 的0-1分布,
所以, E(X)=∑ni=1E(Xi)=np E ( X ) = ∑ i = 1 n E ( X i ) = n p
D(X)=∑ni=1D(Xi)=np(1−p) D ( X ) = ∑ i = 1 n D ( X i ) = n p ( 1 − p )
2. X X 的分布律为
泊松分布
定义
泊松分布就是描述某段时间内,事件具体的发生概率。如:
1. 汽车站台的候车人数;
2. 自然灾害发生次数;
3. 机器出现故障的次数等
概率分布函数为:
λ>0 λ > 0 是常数,是区间事件发生率的均值。
其中P表示概率,N表示某种函数关系,t表示时间,n表示数量, λ λ 表示事件的频率。如已知平均每个小时出生3个新生儿,求下一个小时出生两个婴儿的概率:
期望:
方差:
所以, D(X)=E(X2)−[E(X)]2=λ2+λ−λ2=λ D ( X ) = E ( X 2 ) − [ E ( X ) ] 2 = λ 2 + λ − λ 2 = λ
即,泊松分布的期望和方差都为 λ λ
分布图形
泊松分布的大概图形: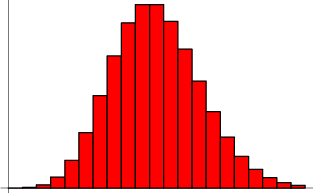
越在频率附近发生的概率越高
指数分布
指数分布是事件的时间间隔的概率。如:
1. 婴儿出生的时间间隔;
2. 来电的时间间隔;
3. 奶粉销售的时间间隔;
4. 网站访问的时间间隔
分布函数
指数分布的分布函数可以由泊松分布来推断。如果下一个婴儿出生要间隔时间t,就等同于在时间t内没有婴儿出生。由泊松分布公式可得:
反之,时间在时间t之内发生的概率,就是1减去上面的值。
无记忆性
指数函数的无记忆性是指,如果x是某电器元件的寿命,已知元件使用了s小时,则共使用至少 s+t s + t 小时的条件概率,与从未使用开始至少使用 t t 小时的概率相等。
均匀分布
设 X∼U(a,b) X ∼ U ( a , b ) ,其概率密度为
则有
正态分布
正态分布又叫高斯分布。正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟型,又经常称之为钟形曲线。
若随机变量 X X 服从一个数学期望为 μ μ 、方差为 σ2 σ 2 的正态分布,记为 N(μ,σ2) N ( μ , σ 2 ) 。其概率密度函数为正态分布的期望值 μ μ 决定了其位置,其标准差 σ σ 决定了分布的幅度。当 μ=0,σ=1 μ = 0 , σ = 1 时的正态分布是标准正态分布。
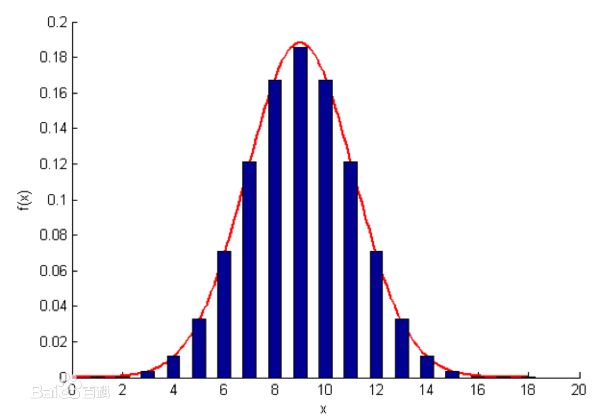
定理
为了便于描述和应用,常将正态变量做数据转换。将一般正态分布转化为标准正态分布。
若 X∼N(μ,σ2),Y=X−μσ∼N(0,1) X ∼ N ( μ , σ 2 ) , Y = X − μ σ ∼ N ( 0 , 1 )
服从标准正态分布,通过查标准正态分布表就可以直接计算出原正态分布的概率值。故该变换被称为标准化变换。
定义
一维正态分布
若随机变量X服从一个位置参数为 μ μ 、尺度参数为 σ σ 的概率分布,且其概率密度函数为
则这个随机变量就称为 正态随机变量,正态随机变量服从的分布就称为 正态分布,记作 X∼N(μ,σ2) X ∼ N ( μ , σ 2 ) ,读作X服从 N(μ,σ2) N ( μ , σ 2 ) ,或服从正态分布。
μ μ 维随机向量具有类似的概率规律时,称此随机向量遵从多维正态分布。
标准正态分布
当 μ=0,σ=1 μ = 0 , σ = 1 时,正态分布就称为标准正态分布