深度学习过拟合问题的优化措施
原文:http://www.sohu.com/a/162003640_465944
在上一篇文章“”中,我们已经了解如何在Docker上从头构建一个Keras的运行平台,搭建基础的深度学习环境。接着对我们要做的事情“IMDB影评预测”问题做了分析,对数据做了解释,并且初步使用LSTM网络,实现了一个比较好的深度学习模型。同时我们还提到虽然我们已经取得了比较好的结果,我们还要继续研究一些基础问题,比如过拟合问题怎么解决,以及我们永不满足的对模型性能的改进目标。这篇文章就上述问题,继续分析,以便让我们对Keras做深度学习有更好的了解。
我们意识到神经网络在具备强大的学习能力的同事,也非常容易出现过拟合overfitting问题,出现过拟合的时候,虽然loss训练误差在每个Epoch稳步下降,但是在测试集上val_loss没有下降,反而有上升的趋势,如果val_loss比loss高出很多,这说明模型已经严重过拟合了。下面我们就要考虑解决过拟合这个问题。
过拟合的问题是搞机器学习的人绕不开的话题,我们无法在取得较高精度的情况下,又能避免过拟合问题,所以需要在模型拟合测试集(及我们案例中的尽量减少loss,获得较高的acc)与模型的泛化能力(val_loss也比较小,与loss相差不大,说明泛化能力较好)之间做一个tradeoff。在深度学习领域,DropoutLayer可以作为减少过拟合风险的一种技术。我们看看在添加Dropout Layer之后的模型性能。
使用Dropout
# LSTM with Dropout
import numpy
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense
from keras.layers importLSTM
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
numpy.random.seed(7)
top_words =5000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words)
# truncate and pad
max_review_length =500
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length)
# create model
embedding_vector_length =32
model = Sequential()
model.add(Embedding(top_words,embedding_vector_length,input_length=max_review_length))
model.add(LSTM(100, dropout=0.3, recurrent_dropout=0.1))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])print(model.summary())
model.fit(X_train, y_train, validation_data=(X_test,y_test), epochs=5, batch_size=64)
scores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%"% (scores[1]*100))
输出结果如下:

我们从执行结果看,Accuracy与没有Dropout的时候第二个Epoch还要降低一些,但是由于减少了过拟合的风险,模型的结构风险会降低,迁移能力理论上会好一些。
加入Dropout层之后,调整Dropout参数,可以减少过拟合的风险,不过这个超参数的设置需要经验,或者说要多尝试几次。但是仍然无法避免过拟合现象。Keras提供了一个回调函数EarlyStopping(),可以针对Epoch出现val_acc降低的时候,提前停止训练,可以参考keras的官方文档:keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0, patience=0, verbose=0, mode='auto')(https://keras.io/callbacks/#earlystopping) 试试看。通常在工程实践中,我们可以认为如果模型在测试集上连续的5个epoch中的性能表现都没有提升,则认为可以提前停止了。
解决过拟合问题,目前有很多手段,比如调小学习速率,调小反向传播的训练样本数(batch_size)都可能减少过拟合的风险,但是这里面的小tricks有点说不清道不明,还可以试一试别的optimizer,哪个好选哪个,是不是感觉像碰运气。机器学习里面有很多经验性的东西是要多试试才能感受到。解决过拟合问题还有一个重要的手段是使用正则化技术。
from keras import regularizers
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01)))
在keras中,可用的正则化方法有如下三个:
keras.regularizers.l1(0.)
keras.regularizers.l2(0.)
keras.regularizers.l1_l2(0.)
使用正则化控制过拟合的实验代码如下:
model = Sequential()
model.add(Embedding(top_words,embedding_vector_length,input_length=max_review_length))
model.add(LSTM(100))
model.add(Dense(1, activation='sigmoid', kernel_regularizer=regularizers.l2(0.01),activity_regularizer=regularizers.l1(0.001)))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])print(model.summary())
model.fit(X_train, y_train, validation_data=(X_test,y_test), epochs=10, batch_size=64)
运行结果输出如下:
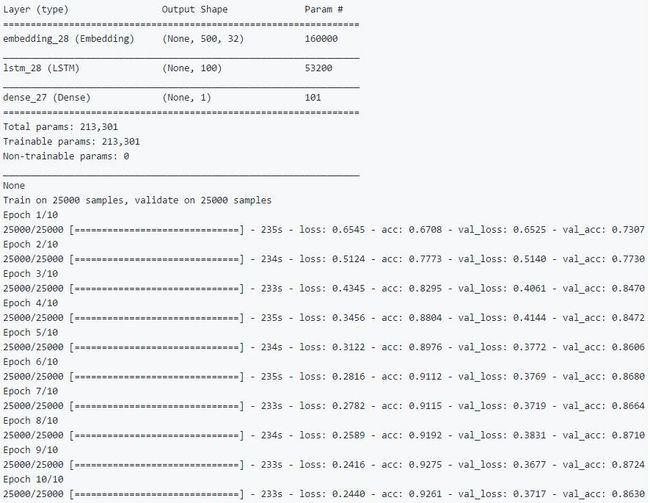
结合卷积神经网络优化序列分类的整体性能
卷积神经网络在图像识别和语音识别领域取得了非凡的成就,特别擅长于从输入数据中学习spatial structure,因此对于处理NLP问题很有帮助。如果利用CNN学习到的特征可以用于LSTM层的训练,对模型的性能理论上会有提升。我们使用keras可以很方便的在EmbeddingLayer添加一个 one-dimensional CNN and max pooling layers。以此作为LSTM层的特征输入。
怎么理解spatialstructure,我们可以从这个角度去想,如果一个输入变量与其相邻的输入变量之间的关系比它距离较远的输入变量之间的关系更密切,则可以认为这样的数据具有spatialstructure特征。例如图像处理里面,临近的像素点之间的相关性比间隔较远的像素之间相关性更大。在语言中也有这样的现象。所以可以借助CNN来优化特征。
代码示例如下:
# LSTM with Dropout and CNN classification
embedding_vector_length=32
model=Sequential()
model.add(Embedding(top_words,embedding_vector_length,input_length=max_review_length))
model.add(SpatialDropout1D(0.3))
model.add(Conv1D(activation="relu", padding="same", filters=64, kernel_size=5))
model.add(MaxPooling1D(pool_size=4))
model.add(LSTM(100,dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])print(model.summary())
model.fit(X_train,y_train,validation_data=(X_test,y_test), epochs=10,batch_size=64)
运行输出结果如下:

添加CNN layer之后,每一轮的训练时间大大减少了,大约降到了原来的1/3时间,精度也有所提升,整体上取得了更好的performance。
总结回顾
这篇文章我们介绍了如何用LSTM网络来解决文本分类问题。如何减少模型过拟合的风险,以及怎样结合CNN网络中学习到的spatialstructure来优化NLP问题的特征,从而提升整个网络的性能。对于一个文本分类问题,我们可以沿着这个思路设计我们的网络结构,基本上能应该能够解决常见的文本序列分类问题了。当然如果要在整个基础上继续小步提升,还需要对数据进行较多的预处理,对网络的参数进行经验性改进。