Credit Card Fraud Detection(信用卡诈欺侦测)Spark建模
背景
这个数据来自2013年9月欧洲信用卡交易数据,总共包括两天的交易数据。在284,807次交易中发现了492例诈骗。数据集极其不平衡,诈骗频率只占了交易频次的0.172%。
这个数据因为涉及敏感信息,用PCA处理过了,V1,V2,…V28是主成分,‘Time’和‘Amount’是没有经过PCA处理的。‘Time’是每次交易与第一次交易之间距离的时间,以秒计。‘Amount’代表消费金额,‘Class’代表响应变量,1代表欺诈,0代表正常。
数据格式

特征处理
读取数据
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
data = pd.read_csv("../input/creditcard.csv")
data.head()先查看下有没有缺失值,通过查看,没有缺失值。如果有缺失值,可以用中位数或者平均数代替。
df.isnull().sum()
查看下类别属性的相关信息
print ("Fraud")
print (df.Amount[df.Class == 1].describe())
print ()
print ("Normal")
print (df.Amount[df.Class == 0].describe())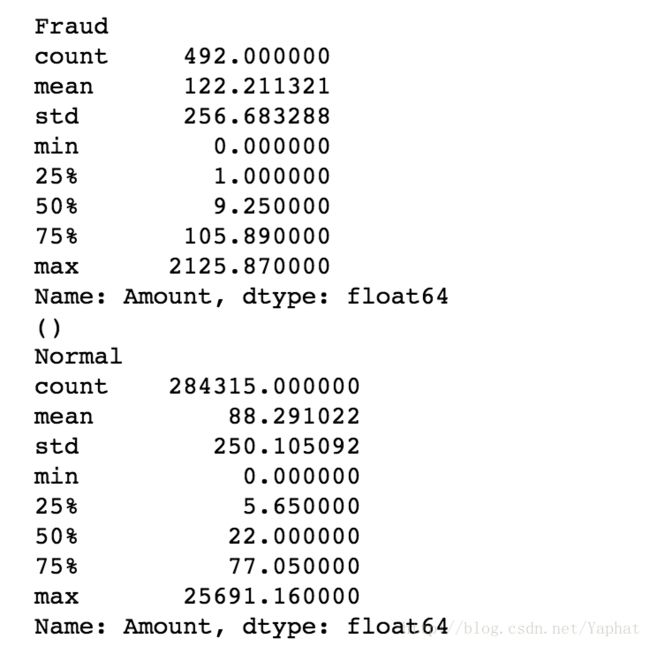
看下Amount特征和类别标签之间可能存在的关系
f, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(12,4))
bins = 30
ax1.hist(df.Amount[df.Class == 1], bins = bins)
ax1.set_title('Fraud')
ax2.hist(df.Amount[df.Class == 0], bins = bins)
ax2.set_title('Normal')
plt.xlabel('Amount ($)')
plt.ylabel('Number of Transactions')
plt.yscale('log')
plt.show()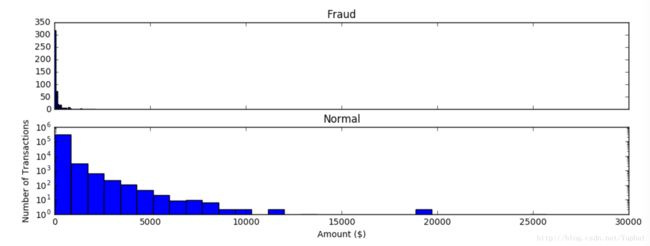
从上面的图片中可以看出欺诈行为都发生在较小金额交易时,金额越小,欺诈交易次数也就越高。发生欺诈行为最高Amount的2125.87。因此这儿可以设置一个新的特征’Amount_max_fraud’,让他在2125.87以下设置为0,以上设置为1,这样便于区分类别标签。
df['Amount_max_fraud'] = 1
df.loc[df.Amount <= 2125.87, 'Amount_max_fraud'] = 0
df.head()为了消除不同量纲之间的影响,将‘Amount’特征标准化形成新的特征‘normAmount’,时间特征在这明显是无用的,所以删除’Time’和‘Amount’两个特征。
from sklearn.preprocessing import StandardScaler
df['normAmount'] = StandardScaler().fit_transform(df['Amount'].reshape(-1, 1))
df = df.drop(['Time','Amount'],axis=1)
df.head()查看类别分布
count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")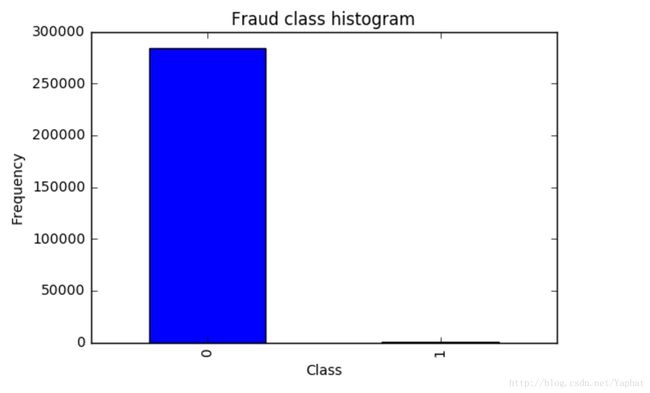
可以看到整个数据集极其不平衡,诈骗频率只占了交易频次的0.172%。如何去处理这个不平衡问题,可以从数据和算法两个层面入手。
1、数据层面:欠采样、过采样、欠采样和过采样结合
2、算法层面:集成学习、代价敏感、特征选择
这里从数据层面入手。使用SMOTE算法做数据过采样。对SMOTE算法的介绍可以看我的这篇博客。这里先将数据进行划分,70%用于训练。
from imblearn.over_sampling import SMOTE
from sklearn.cross_validation import train_test_split
def data_prepration(x):
x_features= x.ix[:,x.columns != "Class"]
x_labels=x.ix[:,x.columns=="Class"] x_features_train,x_features_test,x_labels_train,x_labels_test = train_test_split(x_features,x_labels,test_size=0.3)
print("length of training data")
print(len(x_features_train))
print("length of test data")
print(len(x_features_test))
return(x_features_train,x_features_test,x_labels_train,x_labels_test)
data_train_X,data_test_X,data_train_y,data_test_y=data_prepration(df)
print pd.value_counts(data_test_y['Class'])
#调用smote
os = SMOTE(random_state=0)
os_data_X,os_data_y=os.fit_sample(data_train_X.values,data_train_y.values.ravel())现在再来看下整体的数据分布。
from __future__ import division
columns = data_train_X.columns
os_data_X = pd.DataFrame(data=os_data_X,columns=columns )
print len(os_data_X)
os_data_y= pd.DataFrame(data=os_data_y,columns=["Class"])
# 现在检查下抽样后的数据
print("length of oversampled data is ",len(os_data_X))
print("Number of normal transcation",len(os_data_y[os_data_y["Class"]==0]))
print("Number of fraud transcation",len(os_data_y[os_data_y["Class"]==1]))
print("Proportion of Normal data in oversampled data is ",len(os_data_y[os_data_y["Class"]==0])/len(os_data_X))
print("Proportion of fraud data in oversampled data is ",len(os_data_y[os_data_y["Class"]==1])/len(os_data_X))
可以看到这个数据经过过采样后数据达到了整体的平衡。然后可以将过采样后的训练数据和没有采样的测试数据写入csv文件以方便在spark上处理。
newtraindata=pd.concat([os_data_X,os_data_y],axis=1)
newtestdata=pd.concat([data_test_X,data_test_y],axis=1)
newtraindata.to_csv('./creditcard/train.csv',sep=',')
newtestdata.to_csv('./creditcard/test.csv',sep=',')然后这儿得到了两个文件,下面就是将文件放到spark上去执行。
Spark建模
1、启动hadoop和spark。
2、上传两个文件到hdfs上。
hdfs dfs -put train.csv /user
hdfs dfs -put test.csv /user3、使用jupyter notebook去启动pyspark shell。
import os
execfile(os.path.join(os.environ["SPARK_HOME"], 'python/pyspark/shell.py'))出现如图所示代表连接成功。
4、读取hdfs上的两个文件
train= sc.textFile("hdfs:///user/train.csv")
test = sc.textFile("hdfs:///user/test.csv")
print train.count(),test.count()5、将csv文件格式转成LabeledPoint格式
from pyspark.mllib.regression import LabeledPoint
def parsePoint(line):
values = [float(x.strip()) for x in line.split(',')]
return LabeledPoint(values[-1],values[:30])
train_parsed = train.map(parsePoint)
test_parsed = test.map(parsePoint)6、建模,这里使用决策树模型
from pyspark.mllib.tree import DecisionTree, DecisionTreeModel
#Train a DecisionTree model.
#Empty categoricalFeaturesInfo indicates all features are continuous.
model = DecisionTree.trainClassifier(train_parsed, numClasses=2, categoricalFeaturesInfo={}, impurity='gini', maxDepth=5, maxBins=32)具体的参数调优过程不做详细介绍。建立模型之后可以打印这个模型信息看看。
print('Learned classification tree model:')
print(model.toDebugString())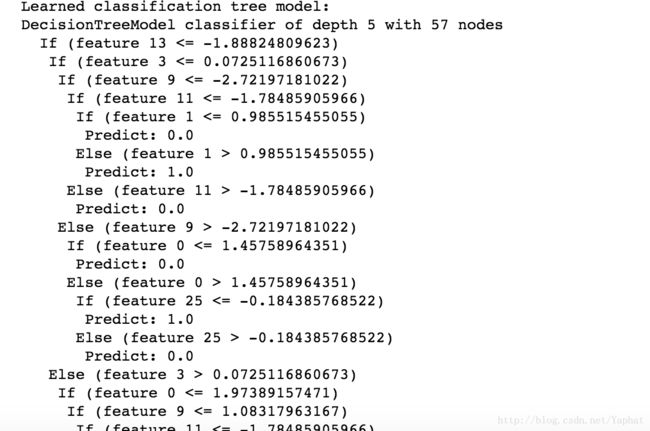
7、评估这个模型的效果
#计算这个模型在测试集上的误差
predictions = model.predict(test_parsed.map(lambda x: x.features))
PredictionsAndLabels = predictions.zip(test_parsed.map(lambda lp: lp.label))
testErr = PredictionsAndLabels.filter(lambda (v, p): v != p).count() / float(test_parsed.count())
print('Test Error = ' + str(testErr))
from pyspark.mllib.evaluation import BinaryClassificationMetrics
metrics = BinaryClassificationMetrics(PredictionsAndLabels)
#计算ROC曲线下的面积即AUC值
print("Area under ROC = %s" % metrics.areaUnderROC)