TensorFlow
用tensorflow实现线性回归,主要考察的是一个tf的一个实现思路。(贝壳)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#使用numpy生成200个随机点
x_data=np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise=np.random.normal(0,0.02,x_data.shape)
y_data=np.square(x_data)+noise
#定义两个placeholder存放输入数据
x=tf.placeholder(tf.float32,[None,1])
y=tf.placeholder(tf.float32,[None,1])
#定义神经网络中间层
Weights_L1=tf.Variable(tf.random_normal([1,10]))
biases_L1=tf.Variable(tf.zeros([1,10])) #加入偏置项
Wx_plus_b_L1=tf.matmul(x,Weights_L1)+biases_L1
L1=tf.nn.tanh(Wx_plus_b_L1) #加入激活函数
#定义神经网络输出层
Weights_L2=tf.Variable(tf.random_normal([10,1]))
biases_L2=tf.Variable(tf.zeros([1,1])) #加入偏置项
Wx_plus_b_L2=tf.matmul(L1,Weights_L2)+biases_L2
prediction=tf.nn.tanh(Wx_plus_b_L2) #加入激活函数
#定义损失函数(均方差函数)
loss=tf.reduce_mean(tf.square(y-prediction))
#定义反向传播算法(使用梯度下降算法训练)
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
with tf.Session() as sess:
#变量初始化
sess.run(tf.global_variables_initializer())
#训练2000次
for i in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#获得预测值
prediction_value=sess.run(prediction,feed_dict={x:x_data})
#画图
plt.figure()
plt.scatter(x_data,y_data) #散点是真实值
plt.plot(x_data,prediction_value,'r-',lw=5) #曲线是预测值
plt.show()TensorFlow——实现线性回归算法
TensorFlow——实现简单的线性回归
请简要介绍下Tensorflow的计算图。(阿里)
Tensorflow是一个通过计算图的形式来表述计算的编程系统,计算图也叫数据流图,可以把计算图看做是一种有向图,Tensorflow中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。
tf前向传播
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 声明w1、w2两个变量,这里还通过seed参数设定了随机种子,
# 这样可以保证每次运行得到的结果是一样的。
w1 = tf.Variable(tf.random_normal((2, 3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), stddev=1, seed=1))
# 暂时将输入的特征向量定义为一个常量,注意这里x是一个1*2的矩阵。
x = tf.constant([[0.7, 0.9]])
# 通过前向传播算法获得神经网络输出。
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
# 这里不能直接通过sess.run(y)来获取y的取值,
# 因为w1和w2都还没有运行初始化过程,以下两行分别初始化了w1和w2两个变量。
sess.run(w1.initializer)
sess.run(w2.initializer)
# 输出[[3.95757794]]
print(sess.run(y))
sess.close()
sess.close()
tf.random_normal([2, 3], stddev=1) 会产生一个 2×3 的矩阵,矩阵中的元素是均值为 0,标准差为 1 的随机数,tf.random_normal 函数可以通过参数 mean 来指定平均值,在没有指定时默认为 0。
Tensorflow实战-前向传播算法
tensorflow(六)训练分类自己的图片(CNN超详细入门版)
tensorflow如何实现并行,梯度更新是同步还是异步,同步异步的优缺点
Tensorflow的梯度异步更新
背景:先说一下应用吧,一般我们进行网络训练时,都有一个batchsize设置,也就是一个batch一个batch的更新梯度,能有这个batch的前提是这个batch中所有的图片的大小一致,这样才能组成一个placeholder。那么若一个网络对图片的输入没有要求,任意尺寸的都可以,但是我们又想一个batch一个batch的更新梯度怎么办呢?——梯度异步更新。
TensorFlow多GPU并行的实现(这个完全解决了上面的问题)
梯度更新可以同步,也可以异步。
同步/异步优劣比较
同步模式解决了异步模式中存在的参数更新问题,然而同步模式的效率却低于异步模式
在同步模式下,每一轮迭代都需要设备统一开始、统一结束
如果设备的运行速度不一致,那么每一轮训练都需要等待最慢的设备结束才能开始更新参数,于是很多时间将被花在等待上
虽然理论上异步模式存在缺陷,但是因为训练深度学习模型时,使用的随机梯度下降本身就是梯度下降的一个近似解法,而且即使是梯度下降也无法保证达到全局最优
所以在实际应用中,相同时间内,使用异步模式训练的模型不一定比同步模式差
tensorflow的分布式版本
Tensorflow分布式原理理解
关于 TensorFlow
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
什么是数据流图(Data Flow Graph)?
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
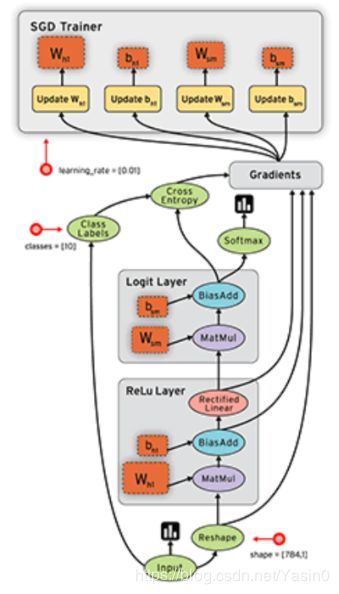
初识tf
使用 TensorFlow, 你必须明白Tensorflow有一下几个简单的步骤:
- 使用 tensor 表示数据.
- 使用图 (graph) 来表示计算任务.
- 在会话(session)中运行图s
在 TF 中发生的所有事,都是在会话(Session) 中进行的。所以,当你在 TF 中编写一个加法时,其实你只是设计了一个加法操作,而不是实际添加任何东西。所有的这些设计都是会在图(Graph)中产生,你会在图中保留这些计算操作和张量,而不是具体的值。
图
TensorFlow程序通常被组织成一个构建阶段和一个执行阶段. 在构建阶段, op的执行步骤被描述成一个图. 在执行阶段, 使用会话执行执行图中的op。我们来构建一个简单的计算图。每个节点采用零个或多个张量作为输入,并产生张量作为输出。一种类型的节点是一个常数。像所有TensorFlow常数一样,它不需要任何输入,它输出一个内部存储的值。我们可以创建两个浮点型常量node1 ,node2如下所示:
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0)
print(node1, node2)
最终的打印声明生成
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
他为什么不是输出结果,那是因为tensorflow中的图形节点操作必须在会话中运行,稍后介绍
构建图
构建图的第一步, 是创建源 op (source op). 源 op 不需要任何输入, 例如 常量 (Constant). 源 op 的输出被传递给其它 op 做运算.TensorFlow Python 库有一个默认图 (default graph), op 构造器可以为其增加节点. 这个默认图对 许多程序来说已经足够用了.,后面我们会接触多个图的使用
默认Graph值始终注册,并可通过调用访问 tf.get_default_graph()
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点,加到默认图中.构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)
print tf.get_default_graph(),matrix1.graph,matrix2.graph
重要注意事项:此类对于图形构造不是线程安全的。所有操作都应从单个线程创建,或者必须提供外部同步。除非另有说明,所有方法都不是线程安全的
在会话中启动图
构造阶段完成后,才能启动图。启动图的第一步是创建一个Session对象,如果无任何创建参数,会话构造器将启动默认图。
调用Session的run()方法来执行矩阵乘法op, 传入product作为该方法的参数,会话负责传递op所需的全部输入,op通常是并发执行的。
# 启动默认图.
sess = tf.Session()
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print result
# 任务完成, 关闭会话.
sess.close()
Session对象在使用完后需要关闭以释放资源,当然也可以使用上下文管理器来完成自动关闭动作。
op
计算图中的每个节点可以有任意多个输入和任意多个输出,每个节点描述了一种运算操作(operation, op),节点可以算作运算操作的实例化(instance)。一种运算操作代表了一种类型的抽象运算,比如矩阵乘法、加法。tensorflow内建了很多种运算操作,如下表所示:
| 类型 | 示例 |
|---|---|
| 标量运算 | Add、Sub、Mul、Div、Exp、Log、Greater、Less、Equal |
| 向量运算 | Concat、Slice、Splot、Constant、Rank、Shape、Shuffle |
| 矩阵运算 | Matmul、MatrixInverse、MatrixDeterminant |
| 带状态的运算 | Variable、Assign、AssignAdd |
| 神经网络组件 | SoftMax、Sigmoid、ReLU、Convolution2D、MaxPooling |
| 存储、恢复 | Save、Restore |
| 队列及同步运算 | Enqueue、Dequeue、MutexAcquire、MutexRelease |
| 控制流 | Merge、Switch、Enter、Leave、NextIteration |
feed
TensorFlow还提供了feed机制, 该机制可以临时替代图中的任意操作中的tensor可以对图中任何操作提交补丁,直接插入一个 tensor。feed 使用一个 tensor 值临时替换一个操作的输入参数,从而替换原来的输出结果.
feed 只在调用它的方法内有效, 方法结束,feed就会消失。最常见的用例是将某些特殊的操作指定为"feed"操作, 标记的方法是使用 tf.placeholder() 为这些操作创建占位符.并且在Session.run方法中增加一个feed_dict参数
# 创建两个个浮点数占位符op
input1 = tf.placeholder(tf.types.float32)
input2 = tf.placeholder(tf.types.float32)
#增加一个乘法op
output = tf.mul(input1, input2)
with tf.Session() as sess:
# 替换input1和input2的值
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
如果没有正确提供feed, placeholder() 操作将会产生错误
Tensorflow进阶
本节我们将学习以下知识点:
- 张量
- 变量
- 名称域
- 图
- 会话
张量的阶和数据类型
TensorFlow用张量这种数据结构来表示所有的数据.你可以把一个张量想象成一个n维的数组或列表.一个张量有一个静态类型和动态类型的维数.张量可以在图中的节点之间流通.其实张量更代表的就是一种多位数组。
阶
在TensorFlow系统中,张量的维数来被描述为阶.但是张量的阶和矩阵的阶并不是同一个概念.张量的阶(有时是关于如顺序或度数或者是n维)是张量维数的一个数量描述.比如,下面的张量(使用Python中list定义的)就是2阶.
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
你可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量.
| 阶 | 数学实例 | Python | 例子 |
|---|---|---|---|
| 0 | 纯量 | (只有大小) | s = 483 |
| 1 | 向量 | (大小和方向) | v = [1.1, 2.2, 3.3] |
| 2 | 矩阵 | (数据表) | m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| 3 | 3阶张量 | (数据立体) | t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
| n | n阶 | (自己想想看) | .... |
数据类型
Tensors有一个数据类型属性.你可以为一个张量指定下列数据类型中的任意一个类型:
| 数据类型 | Python 类型 | 描述 |
|---|---|---|
| DT_FLOAT | tf.float32 | 32 位浮点数. |
| DT_DOUBLE | tf.float64 | 64 位浮点数. |
| DT_INT64 | tf.int64 | 64 位有符号整型. |
| DT_INT32 | tf.int32 | 32 位有符号整型. |
| DT_INT16 | tf.int16 | 16 位有符号整型. |
| DT_INT8 | tf.int8 | 8 位有符号整型. |
| DT_UINT8 | tf.uint8 | 8 位无符号整型. |
| DT_STRING | tf.string | 可变长度的字节数组.每一个张量元素都是一个字节数组. |
| DT_BOOL | tf.bool | 布尔型. |
| DT_COMPLEX64 | tf.complex64 | 由两个32位浮点数组成的复数:实数和虚数. |
| DT_QINT32 | tf.qint32 | 用于量化Ops的32位有符号整型. |
| DT_QINT8 | tf.qint8 | 用于量化Ops的8位有符号整型. |
| DT_QUINT8 | tf.quint8 | 用于量化Ops的8位无符号整型. |
张量操作
在tensorflow中,有很多操作张量的函数,有生成张量、创建随机张量、张量类型与形状变换和张量的切片与运算
生成张量
固定值张量
tf.zeros(shape, dtype=tf.float32, name=None)
创建所有元素设置为零的张量。此操作返回一个dtype具有形状shape和所有元素设置为零的类型的张量。
tf.zeros_like(tensor, dtype=None, name=None)
给tensor定单张量(),此操作返回tensor与所有元素设置为零相同的类型和形状的张量。
tf.ones(shape, dtype=tf.float32, name=None)
创建一个所有元素设置为1的张量。此操作返回一个类型的张量,dtype形状shape和所有元素设置为1。
tf.ones_like(tensor, dtype=None, name=None)
给tensor定单张量(),此操作返回tensor与所有元素设置为1 相同的类型和形状的张量。
tf.fill(dims, value, name=None)
创建一个填充了标量值的张量。此操作创建一个张量的形状dims并填充它value。
tf.constant(value, dtype=None, shape=None, name='Const')
创建一个常数张量。
用常数张量作为例子
t1 = tf.constant([1, 2, 3, 4, 5, 6, 7])
t2 = tf.constant(-1.0, shape=[2, 3])
print(t1,t2)
我们可以看到在没有运行的时候,输出值为:
(, )
一个张量包含了一下几个信息
- 一个名字,它用于键值对的存储,用于后续的检索:Const: 0
- 一个形状描述, 描述数据的每一维度的元素个数:(2,3)
- 数据类型,比如int32,float32
创建随机张量
一般我们经常使用的随机数函数 Math.random() 产生的是服从均匀分布的随机数,能够模拟等概率出现的情况,例如 扔一个骰子,1到6点的概率应该相等,但现实生活中更多的随机现象是符合正态分布的,例如20岁成年人的体重分布等。
假如我们在制作一个游戏,要随机设定许许多多 NPC 的身高,如果还用Math.random(),生成从140 到 220 之间的数字,就会发现每个身高段的人数是一样多的,这是比较无趣的,这样的世界也与我们习惯不同,现实应该是特别高和特别矮的都很少,处于中间的人数最多,这就要求随机函数符合正态分布。
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从截断的正态分布中输出随机值,和 tf.random_normal() 一样,但是所有数字都不超过两个标准差
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从正态分布中输出随机值,由随机正态分布的数字组成的矩阵
# 正态分布的 4X4X4 三维矩阵,平均值 0, 标准差 1
normal = tf.truncated_normal([4, 4, 4], mean=0.0, stddev=1.0)
a = tf.Variable(tf.random_normal([2,2],seed=1))
b = tf.Variable(tf.truncated_normal([2,2],seed=2))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(a))
print(sess.run(b))
输出:
[[-0.81131822 1.48459876]
[ 0.06532937 -2.44270396]]
[[-0.85811085 -0.19662298]
[ 0.13895047 -1.22127688]]
tf.random_uniform(shape, minval=0.0, maxval=1.0, dtype=tf.float32, seed=None, name=None)
从均匀分布输出随机值。生成的值遵循该范围内的均匀分布 [minval, maxval)。下限minval包含在范围内,而maxval排除上限。
a = tf.random_uniform([2,3],1,10)
with tf.Session() as sess:
print(sess.run(a))
tf.random_shuffle(value, seed=None, name=None)
沿其第一维度随机打乱
tf.set_random_seed(seed)
设置图级随机种子
要跨会话生成不同的序列,既不设置图级别也不设置op级别的种子:
a = tf.random_uniform([1])
b = tf.random_normal([1])
print "Session 1"
with tf.Session() as sess1:
print sess1.run(a)
print sess1.run(a)
print sess1.run(b)
print sess1.run(b)
print "Session 2"
with tf.Session() as sess2:
print sess2.run(a)
print sess2.run(a)
print sess2.run(b)
print sess2.run(b)
要为跨会话生成一个可操作的序列,请为op设置种子:
a = tf.random_uniform([1], seed=1)
b = tf.random_normal([1])
print "Session 1"
with tf.Session() as sess1:
print sess1.run(a)
print sess1.run(a)
print sess1.run(b)
print sess1.run(b)
print "Session 2"
with tf.Session() as sess2:
print sess2.run(a)
print sess2.run(a)
print sess2.run(b)
print sess2.run(b)

为了使所有op产生的随机序列在会话之间是可重复的,设置一个图级别的种子:
tf.set_random_seed(1234)
a = tf.random_uniform([1])
b = tf.random_normal([1])
print "Session 1"
with tf.Session() as sess1:
print sess1.run(a)
print sess1.run(a)
print sess1.run(b)
print sess1.run(b)
print "Session 2"
with tf.Session() as sess2:
print sess2.run(a)
print sess2.run(a)
print sess2.run(b)
print sess2.run(b)
我们可以看到结果

张量变换
TensorFlow提供了几种操作,您可以使用它们在图形中改变张量数据类型。
改变类型
提供了如下一些改变张量中数值类型的函数
- tf.string_to_number(string_tensor, out_type=None, name=None)
- tf.to_double(x, name='ToDouble')
- tf.to_float(x, name='ToFloat')
- tf.to_bfloat16(x, name='ToBFloat16')
- tf.to_int32(x, name='ToInt32')
- tf.to_int64(x, name='ToInt64')
- tf.cast(x, dtype, name=None)
我们用一个其中一个举例子
tf.string_to_number(string_tensor, out_type=None, name=None)
将输入Tensor中的每个字符串转换为指定的数字类型。注意,int32溢出导致错误,而浮点溢出导致舍入值
n1 = tf.constant(["1234","6789"])
n2 = tf.string_to_number(n1,out_type=tf.types.float32)
sess = tf.Session()
result = sess.run(n2)
print result
sess.close()
形状和变换
可用于确定张量的形状并更改张量的形状
- tf.shape(input, name=None)
- tf.size(input, name=None)
- tf.rank(input, name=None)
- tf.reshape(tensor, shape, name=None)
- tf.squeeze(input, squeeze_dims=None, name=None)
- tf.expand_dims(input, dim, name=None)
tf.shape(input, name=None)
返回张量的形状。
t = tf.constant([[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]])
shape(t) -> [2, 2, 3]
静态形状与动态形状
静态维度 是指当你在创建一个张量或者由操作推导出一个张量时,这个张量的维度是确定的。它是一个元祖或者列表。TensorFlow将尽最大努力去猜测不同张量的形状(在不同操作之间),但是它不会总是能够做到这一点。特别是如果您开始用未知维度定义的占位符执行操作。tf.Tensor.get_shape方法读取静态形状
t = tf.placeholder(tf.float32,[None,2])
print(t.get_shape())
结果

动态形状 当你在运行你的图时,动态形状才是真正用到的。这种形状是一种描述原始张量在执行过程中的一种张量。如果你定义了一个没有标明具体维度的占位符,即用None表示维度,那么当你将值输入到占位符时,这些无维度就是一个具体的值,并且任何一个依赖这个占位符的变量,都将使用这个值。tf.shape来描述动态形状
t = tf.placeholder(tf.float32,[None,2])
print(tf.shape(t))

tf.squeeze(input, squeeze_dims=None, name=None)
这个函数的作用是将input中维度是1的那一维去掉。但是如果你不想把维度是1的全部去掉,那么你可以使用squeeze_dims参数,来指定需要去掉的位置。
import tensorflow as tf
sess = tf.Session()
data = tf.constant([[1, 2, 1], [3, 1, 1]])
print sess.run(tf.shape(data))
d_1 = tf.expand_dims(data, 0)
d_1 = tf.expand_dims(d_1, 2)
d_1 = tf.expand_dims(d_1, -1)
d_1 = tf.expand_dims(d_1, -1)
print sess.run(tf.shape(d_1))
d_2 = d_1
print sess.run(tf.shape(tf.squeeze(d_1)))
print sess.run(tf.shape(tf.squeeze(d_2, [2, 4])))
tf.expand_dims(input, dim, name=None)
该函数作用与squeeze相反,添加一个指定维度
import tensorflow as tf
import numpy as np
sess = tf.Session()
data = tf.constant([[1, 2, 1], [3, 1, 1]])
print sess.run(tf.shape(data))
d_1 = tf.expand_dims(data, 0)
print sess.run(tf.shape(d_1))
d_1 = tf.expand_dims(d_1, 2)
print sess.run(tf.shape(d_1))
d_1 = tf.expand_dims(d_1, -1)
print sess.run(tf.shape(d_1))
切片与扩展
TensorFlow提供了几个操作来切片或提取张量的部分,或者将多个张量加在一起
- tf.slice(input_, begin, size, name=None)
- tf.split(split_dim, num_split, value, name='split')
- tf.tile(input, multiples, name=None)
- tf.pad(input, paddings, name=None)
- tf.concat(concat_dim, values, name='concat')
- tf.pack(values, name='pack')
- tf.unpack(value, num=None, name='unpack')
- tf.reverse_sequence(input, seq_lengths, seq_dim, name=None)
- tf.reverse(tensor, dims, name=None)
- tf.transpose(a, perm=None, name='transpose')
- tf.gather(params, indices, name=None)
- tf.dynamic_partition(data, partitions, num_partitions, name=None)
- tf.dynamic_stitch(indices, data, name=None)
其它一些张量运算(了解查阅)
张量复制与组合
- tf.identity(input, name=None)
- tf.tuple(tensors, name=None, control_inputs=None)
- tf.group(inputs, *kwargs)
- tf.no_op(name=None)
- tf.count_up_to(ref, limit, name=None)
逻辑运算符
- tf.logical_and(x, y, name=None)
- tf.logical_not(x, name=None)
- tf.logical_or(x, y, name=None)
- tf.logical_xor(x, y, name='LogicalXor')
比较运算符
- tf.equal(x, y, name=None)
- tf.not_equal(x, y, name=None)
- tf.less(x, y, name=None)
- tf.less_equal(x, y, name=None)
- tf.greater(x, y, name=None)
- tf.greater_equal(x, y, name=None)
- tf.select(condition, t, e, name=None)
- tf.where(input, name=None)
判断检查
- tf.is_finite(x, name=None)
- tf.is_inf(x, name=None)
- tf.is_nan(x, name=None)
- tf.verify_tensor_all_finite(t, msg, name=None) 断言张量不包含任何NaN或Inf
- tf.check_numerics(tensor, message, name=None)
- tf.add_check_numerics_ops()
- tf.Assert(condition, data, summarize=None, name=None)
- tf.Print(input_, data, message=None, first_n=None, summarize=None, name=None)
变量的的创建、初始化、保存和加载
其实变量的作用在语言中相当,都有存储一些临时值的作用或者长久存储。在Tensorflow中当训练模型时,用变量来存储和更新参数。变量包含张量(Tensor)存放于内存的缓存区。建模时它们需要被明确地初始化,模型训练后它们必须被存储到磁盘。值可在之后模型训练和分析是被加载。
Variable类
tf.Variable.init(initial_value, trainable=True, collections=None, validate_shape=True, name=None)
创建一个带值的新变量initial_value
-
initial_value:A Tensor或Python对象可转换为a Tensor.变量的初始值.必须具有指定的形状,除非 validate_shape设置为False.
-
trainable:如果True,默认值也将该变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES,该集合用作Optimizer类要使用的变量的默认列表
-
collections:图表集合键列表,新变量添加到这些集合中.默认为[GraphKeys.VARIABLES]
-
validate_shape:如果False允许使用未知形状的值初始化变量,如果True,默认形状initial_value必须提供.
-
name:变量的可选名称,默认'Variable'并自动获取
变量的创建
创建当一个变量时,将你一个张量作为初始值传入构造函数Variable().TensorFlow提供了一系列操作符来初始化张量,值初始的英文常量或是随机值。像任何一样Tensor,创建的变量Variable()可以用作图中其他操作的输入。此外,为Tensor该类重载的所有运算符都被转载到变量中,因此您也可以通过对变量进行算术来将节点添加到图形中。
x = tf.Variable(5.0,name="x")
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")
调用tf.Variable()向图中添加了几个操作:
- 一个variable op保存变量值。
- 初始化器op将变量设置为其初始值。这实际上是一个tf.assign操作。
- 初始值的ops,例如 示例中biases变量的zeros op 也被添加到图中。
变量的初始化
- 变量的初始化必须在模型的其它操作运行之前先明确地完成。最简单的方法就是添加一个给所有变量初始化的操作,并在使用模型之前首先运行那个操作。最常见的初始化模式是使用便利函数 initialize_all_variables()将Op添加到初始化所有变量的图形中。
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
- 还可以通过运行其初始化函数op来初始化变量,从保存文件还原变量,或者简单地运行assign向变量分配值的Op。实际上,变量初始化器op只是一个assignOp,它将变量的初始值赋给变量本身。assign是一个方法,后面方法的时候会提到
with tf.Session() as sess:
sess.run(w.initializer)
通过另一个变量赋值
你有时候会需要用另一个变量的初始化值给当前变量初始化,由于tf.global_variables_initializer()初始化所有变量,所以需要注意这个方法的使用。
就是将已初始化的变量的值赋值给另一个新变量!
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
w2 = tf.Variable(weights.initialized_value(), name="w2")
w_twice = tf.Variable(weights.initialized_value() * 0.2, name="w_twice")
所有变量都会自动收集到创建它们的图形中。默认情况下,构造函数将新变量添加到图形集合GraphKeys.GLOBAL_VARIABLES。方便函数 global_variables()返回该集合的内容。
属性
name
返回变量的名字
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
print(weights.name)
op
返回op操作
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35))
print(weights.op)
方法
assign
为变量分配一个新值。
x = tf.Variable(5.0,name="x")
w.assign(w + 1.0)
eval
在会话中,计算并返回此变量的值。这不是一个图形构造方法,它不会向图形添加操作。方便打印结果
v = tf.Variable([1, 2])
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 指定会话
print(v.eval(sess))
# 使用默认会话
print(v.eval())
变量的静态形状与动态形状
TensorFlow中,张量具有静态(推测)形状和动态(真实)形状
- 静态形状:
创建一个张量或者由操作推导出一个张量时,初始状态的形状
- tf.Tensor.get_shape:获取静态形状
- tf.Tensor.set_shape():更新Tensor对象的静态形状,通常用于在不能直接推断的情况下
- 动态形状:
一种描述原始张量在执行过程中的一种形状
- tf.shape(tf.Tensor):如果在运行的时候想知道None到底是多少,只能通过tf.shape(tensor)[0]这种方式来获得
- tf.reshape:创建一个具有不同动态形状的新张量
要点
1、转换静态形状的时候,1-D到1-D,2-D到2-D,不能跨阶数改变形状
2、 对于已经固定或者设置静态形状的张量/变量,不能再次设置静态形状
3、tf.reshape()动态创建新张量时,元素个数不能不匹配
4、运行时候,动态获取张量的形状值,只能通过tf.shape(tensor)[]
管理图中收集的变量
tf.global_variables()
返回图中收集的所有变量
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35))
print(tf.global_variables())
变量作用域
tensorflow提供了变量作用域和共享变量这样的概念,有几个重要的作用。
- 让模型代码更加清晰,作用分明
变量作用域域
通过tf.variable_scope()创建指定名字的变量作用域
with tf.variable_scope("itcast") as scope:
print("----")
加上with语句就可以在整个itcast变量作用域下就行操作。
嵌套使用
变量作用域可以嵌套使用
with tf.variable_scope("itcast") as itcast:
with tf.variable_scope("python") as python:
print("----")
变量作用域下的变量
在同一个变量作用域下,如果定义了两个相同名称的变量(这里先用tf.Variable())会怎么样呢?
with tf.variable_scope("itcast") as scope:
a = tf.Variable([1.0,2.0],name="a")
b = tf.Variable([2.0,3.0],name="a")
我们通过tensoflow提供的计算图界面观察

我们发现取了同样的名字,其实tensorflow并没有当作同一个,而是另外又增加了一个a_1,来表示b的图
变量范围
当每次在一个变量作用域中创建变量的时候,会在变量的name前面加上变量作用域的名称
with tf.variable_scope("itcast"):
a = tf.Variable(1.0,name="a")
b = tf.get_variable("b", [1])
print(a.name,b.name)
得道结果
(u'itcast/a:0', u'itcast/b:0')
对于嵌套的变量作用域来说
with tf.variable_scope("itcast"):
with tf.variable_scope("python"):
python3 = tf.get_variable("python3", [1])
assert python3.name == "itcast/python/python3:0"
var2 = tf.get_variable("var",[3,4],initializer=tf.constant_initializer(0.0))
```
图与会话
图
tf.Graph
TensorFlow计算,表示为数据流图。一个图包含一组表示 tf.Operation计算单位的对象和tf.Tensor表示操作之间流动的数据单元的对象。默认Graph值始终注册,并可通过调用访问 tf.get_default_graph。
a = tf.constant(1.0)
assert c.graph is tf.get_default_graph()
我们可以发现这两个图是一样的。那么如何创建一个图呢,通过tf.Graph()
g1= tf.Graph()
g2= tf.Graph()
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(g1,g2,tf.get_default_graph())
图的其它属性和方法
作为一个图的类,自然会有一些图的属性和方法。
as_default()
返回一个上下文管理器,使其成为Graph默认图形。
如果要在同一过程中创建多个图形,则应使用此方法。为了方便起见,提供了一个全局默认图形,如果不明确地创建一个新的图形,所有操作都将添加到此图形中。使用该with关键字的方法来指定在块的范围内创建的操作应添加到此图形中。
g = tf.Graph()
with g.as_default():
a = tf.constant(1.0)
assert c.graph is g
会话
tf.Session
运行TensorFlow操作图的类,一个包含ops执行和tensor被评估
a = tf.constant(5.0)
b = tf.constant(6.0)
c = a * b
sess = tf.Session()
print(sess.run(c))
在开启会话的时候指定图
with tf.Session(graph=g) as sess:
资源释放
会话可能拥有很多资源,如 tf.Variable,tf.QueueBase和tf.ReaderBase。在不再需要这些资源时,重要的是释放这些资源。要做到这一点,既可以调用tf.Session.close会话中的方法,也可以使用会话作为上下文管理器。以下两个例子是等效的:
# 使用close手动关闭
sess = tf.Session()
sess.run(...)
sess.close()
# 使用上下文管理器
with tf.Session() as sess:
sess.run(...)
run方法介绍
run(fetches, feed_dict=None, options=None, run_metadata=None)
运行ops和计算tensor
- fetches 可以是单个图形元素,或任意嵌套列表,元组,namedtuple,dict或OrderedDict
- feed_dict 允许调用者覆盖图中指定张量的值
如果a,b是其它的类型,比如tensor,同样可以覆盖原先的值
a = tf.placeholder(tf.float32, shape=[])
b = tf.placeholder(tf.float32, shape=[])
c = tf.constant([1,2,3])
with tf.Session() as sess:
a,b,c = sess.run([a,b,c],feed_dict={a: 1, b: 2,c:[4,5,6]})
print(a,b,c)
错误
- RuntimeError:如果它Session处于无效状态(例如已关闭)。
- TypeError:如果fetches或feed_dict键是不合适的类型。
- ValueError:如果fetches或feed_dict键无效或引用 Tensor不存在。
其它属性和方法
graph
返回本次会话中的图
as_default()
返回使此对象成为默认会话的上下文管理器。
获取当前的默认会话,请使用 tf.get_default_session
c = tf.constant(..)
sess = tf.Session()
with sess.as_default():
assert tf.get_default_session() is sess
print(c.eval())
注意: 使用这个上下文管理器并不会在退出的时候关闭会话,还需要手动的去关闭
c = tf.constant(...)
sess = tf.Session()
with sess.as_default():
print(c.eval())
# ...
with sess.as_default():
print(c.eval())
sess.close()
模型保存与恢复、自定义命令行参数、
在我们训练或者测试过程中,总会遇到需要保存训练完成的模型,然后从中恢复继续我们的测试或者其它使用。模型的保存和恢复也是通过tf.train.Saver类去实现,它主要通过将Saver类添加OPS保存和恢复变量到checkpoint。它还提供了运行这些操作的便利方法。
tf.train.Saver(var_list=None, reshape=False, sharded=False, max_to_keep=5, keep_checkpoint_every_n_hours=10000.0, name=None, restore_sequentially=False, saver_def=None, builder=None, defer_build=False, allow_empty=False, write_version=tf.SaverDef.V2, pad_step_number=False)
- var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递.
- max_to_keep:指示要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5(即保留最新的5个检查点文件。)
- keep_checkpoint_every_n_hours:多久生成一个新的检查点文件。默认为10,000小时
保存
保存我们的模型需要调用Saver.save()方法。save(sess, save_path, global_step=None),checkpoint是专有格式的二进制文件,将变量名称映射到张量值。
import tensorflow as tf
a = tf.Variable([[1.0,2.0]],name="a")
b = tf.Variable([[3.0],[4.0]],name="b")
c = tf.matmul(a,b)
saver=tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(c))
saver.save(sess, '/tmp/ckpt/test/matmul')
我们可以看保存了什么文件

在多次训练的时候可以指定多少间隔生成检查点文件
saver.save(sess, '/tmp/ckpt/test/matmu', global_step=0) ==> filename: 'matmu-0'
saver.save(sess, '/tmp/ckpt/test/matmu', global_step=1000) ==> filename: 'matmu-1000'
恢复
恢复模型的方法是restore(sess, save_path),save_path是以前保存参数的路径,我们可以使用tf.train.latest_checkpoint来获取最近的检查点文件(也恶意直接写文件目录)
import tensorflow as tf
a = tf.Variable([[1.0,2.0]],name="a")
b = tf.Variable([[3.0],[4.0]],name="b")
c = tf.matmul(a,b)
saver=tf.train.Saver(max_to_keep=1)
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(c))
saver.save(sess, '/tmp/ckpt/test/matmul')
# 恢复模型
model_file = tf.train.latest_checkpoint('/tmp/ckpt/test/')
saver.restore(sess, model_file)
print(sess.run([c], feed_dict={a: [[5.0,6.0]], b: [[7.0],[8.0]]}))
自定义命令行参数
tf.app.run(),默认调用main()函数,运行程序。main(argv)必须传一个参数。
tf.app.flags,它支持应用从命令行接受参数,可以用来指定集群配置等。在tf.app.flags下面有各种定义参数的类型
-
DEFINE_string(flag_name, default_value, docstring)
-
DEFINE_integer(flag_name, default_value, docstring)
-
DEFINE_boolean(flag_name, default_value, docstring)
-
DEFINE_float(flag_name, default_value, docstring)
第一个也就是参数的名字,路径、大小等等。第二个参数提供具体的值。第三个参数是说明文档
tf.app.flags.FLAGS,在flags有一个FLAGS标志,它在程序中可以调用到我们前面具体定义的flag_name.
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('data_dir', '/tmp/tensorflow/mnist/input_data',
"""数据集目录""")
tf.app.flags.DEFINE_integer('max_steps', 2000,
"""训练次数""")
tf.app.flags.DEFINE_string('summary_dir', '/tmp/summary/mnist/convtrain',
"""事件文件目录""")
def main(argv):
print(FLAGS.data_dir)
print(FLAGS.max_steps)
print(FLAGS.summary_dir)
print(argv)
if __name__=="__main__":
tf.app.run()
IO操作
本节我们将介绍Tensorflow在IO处理上的一些知识点
- 线程与队列
- 数据读取
- 图像操作
线程和队列
在使用TensorFlow进行异步计算时,队列是一种强大的机制。
为了感受一下队列,让我们来看一个简单的例子。我们先创建一个“先入先出”的队列(FIFOQueue),并将其内部所有元素初始化为零。然后,我们构建一个TensorFlow图,它从队列前端取走一个元素,加上1之后,放回队列的后端。慢慢地,队列的元素的值就会增加。
TensorFlow提供了两个类来帮助多线程的实现:tf.Coordinator和 tf.QueueRunner。Coordinator类可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常,QueueRunner类用来协调多个工作线程同时将多个张量推入同一个队列中。
队列概述
队列,如FIFOQueue和RandomShuffleQueue,在TensorFlow的张量异步计算时都非常重要。
例如,一个典型的输入结构:是使用一个RandomShuffleQueue来作为模型训练的输入:
- 多个线程准备训练样本,并且把这些样本推入队列。
- 一个训练线程执行一个训练操作
同步执行队列
# 创建一个队列
Q = tf.FIFOQueue(3, dtypes=tf.float32)
# 数据进队列
init = Q.enqueue_many(([0.1, 0.2, 0.3],))
# 定义操作,op,出队列,+1,进队列,注意返回的都是op
out_q = Q.dequeue()
data = out_q + 1
en_q = Q.enqueue(data)
with tf.Session() as sess:
# 初始化队列,是数据进入
sess.run(init)
# 执行两次入队加1
for i in range(2):
sess.run(en_q)
# 循环取队列
for i in range(3):
print(sess.run(Q.dequeue()))
tf.QueueRunner
QueueRunner类会创建一组线程, 这些线程可以重复的执行Enquene操作, 他们使用同一个Coordinator来处理线程同步终止。此外,一个QueueRunner会运行一个closer thread,当Coordinator收到异常报告时,这个closer thread会自动关闭队列。
您可以使用一个queue runner,来实现上述结构。 首先建立一个TensorFlow图表,这个图表使用队列来输入样本。增加处理样本并将样本推入队列中的操作。增加training操作来移除队列中的样本。
tf.Coordinator
Coordinator类用来帮助多个线程协同工作,多个线程同步终止。 其主要方法有:
- should_stop():如果线程应该停止则返回True。
- request_stop(): 请求该线程停止。
- join():等待被指定的线程终止。
首先创建一个Coordinator对象,然后建立一些使用Coordinator对象的线程。这些线程通常一直循环运行,一直到should_stop()返回True时停止。 任何线程都可以决定计算什么时候应该停止。它只需要调用request_stop(),同时其他线程的should_stop()将会返回True,然后都停下来。
异步执行队列:
#主线程,不断的去取数据,开启其它线程来进行增加计数,入队
#主线程结束了,队列线程没有结束,就会抛出异常
#主线程没有结束,需要将队列线程关闭,防止主线程等待
Q = tf.FIFOQueue(1000,dtypes=tf.float32)
# 定义操作
var = tf.Variable(0.0)
increment_op = tf.assign_add(var,tf.constant(1.0))
en_op = Q.enqueue(increment_op)
# 创建一个队列管理器,指定线程数,执行队列的操作
qr = tf.train.QueueRunner(Q,enqueue_ops=[increment_op,en_op]*3)
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 生成一个线程协调器
coord = tf.train.Coordinator()
# 启动线程执行操作
threads_list = qr.create_threads(sess,coord=coord,start=True)
print(len(threads_list),"----------")
# 主线程去取数据
for i in range(20):
print(sess.run(Q.dequeue()))
# 请求其它线程终止
coord.request_stop()
# 关闭线程
coord.join(threads_list)读取数据
小数量数据读取
这仅用于可以完全加载到存储器中的小的数据集有两种方法:
- 存储在常数中。
- 存储在变量中,初始化后,永远不要改变它的值。
使用常数更简单一些,但是会使用更多的内存,因为常数会内联的存储在数据流图数据结构中,这个结构体可能会被复制几次。
training_data = ...
training_labels = ...
with tf.Session():
input_data = tf.constant(training_data)
input_labels = tf.constant(training_labels)
要改为使用变量的方式,您就需要在数据流图建立后初始化这个变量。
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,
shape=training_data.shape)
label_initializer = tf.placeholder(dtype=training_labels.dtype,
shape=training_labels.shape)
input_data = tf.Variable(data_initalizer, trainable=False, collections=[])
input_labels = tf.Variable(label_initalizer, trainable=False, collections=[])
...
sess.run(input_data.initializer,
feed_dict={data_initializer: training_data})
sess.run(input_labels.initializer,
feed_dict={label_initializer: training_lables})
设定trainable=False可以防止该变量被数据流图的GraphKeys.TRAINABLE_VARIABLES收集,这样我们就不会在训练的时候尝试更新它的值;设定collections=[]可以防止GraphKeys.VARIABLES收集后做为保存和恢复的中断点。设定这些标志,是为了减少额外的开销
文件读取
先看下文件读取以及读取数据处理成张量结果的过程:

一般数据文件格式有文本、excel和图片数据。那么TensorFlow都有对应的解析函数,除了这几种。还有TensorFlow指定的文件格式。
标准TensorFlow格式
TensorFlow还提供了一种内置文件格式TFRecord,二进制数据和训练类别标签数据存储在同一文件。模型训练前图像等文本信息转换为TFRecord格式。TFRecord文件是protobuf格式。数据不压缩,可快速加载到内存。TFRecords文件包含 tf.train.Example protobuf,需要将Example填充到协议缓冲区,将协议缓冲区序列化为字符串,然后使用该文件将该字符串写入TFRecords文件。在图像操作我们会介绍整个过程以及详细参数。
数据读取实现
文件队列生成函数
- tf.train.string_input_producer(string_tensor, num_epochs=None, shuffle=True, seed=None, capacity=32, name=None)
产生指定文件张量
文件阅读器类
- class tf.TextLineReader
阅读文本文件逗号分隔值(CSV)格式
- tf.FixedLengthRecordReader
要读取每个记录是固定数量字节的二进制文件
- tf.TFRecordReader
读取TfRecords文件
解码
由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
-
tf.decode_csv(records,record_defaults,field_delim = None,name = None)将CSV转换为张量,与tf.TextLineReader搭配使用
-
tf.decode_raw(bytes,out_type,little_endian = None,name = None) 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用
生成文件队列
将文件名列表交给tf.train.string_input_producer函数。string_input_producer来生成一个先入先出的队列,文件阅读器会需要它们来取数据。string_input_producer提供的可配置参数来设置文件名乱序和最大的训练迭代数,QueueRunner会为每次迭代(epoch)将所有的文件名加入文件名队列中,如果shuffle=True的话,会对文件名进行乱序处理。一过程是比较均匀的,因此它可以产生均衡的文件名队列。
这个QueueRunner工作线程是独立于文件阅读器的线程,因此乱序和将文件名推入到文件名队列这些过程不会阻塞文件阅读器运行。根据你的文件格式,选择对应的文件阅读器,然后将文件名队列提供给阅读器的 read 方法。阅读器的read方法会输出一个键来表征输入的文件和其中纪录(对于调试非常有用),同时得到一个字符串标量,这个字符串标量可以被一个或多个解析器,或者转换操作将其解码为张量并且构造成为样本。
# 读取CSV格式文件
# 1、构建文件队列
# 2、构建读取器,读取内容
# 3、解码内容
# 4、现读取一个内容,如果有需要,就批处理内容
import tensorflow as tf
import os
def readcsv_decode(filelist):
"""
读取并解析文件内容
:param filelist: 文件列表
:return: None
"""
# 把文件目录和文件名合并
flist = [os.path.join("./csvdata/",file) for file in filelist]
# 构建文件队列
file_queue = tf.train.string_input_producer(flist,shuffle=False)
# 构建阅读器,读取文件内容
reader = tf.TextLineReader()
key,value = reader.read(file_queue)
record_defaults = [["null"],["null"]] # [[0],[0],[0],[0]]
# 解码内容,按行解析,返回的是每行的列数据
example,label = tf.decode_csv(value,record_defaults=record_defaults)
# 通过tf.train.batch来批处理数据
example_batch,label_batch = tf.train.batch([example,label],batch_size=9,num_threads=1,capacity=9)
with tf.Session() as sess:
# 线程协调员
coord = tf.train.Coordinator()
# 启动工作线程
threads = tf.train.start_queue_runners(sess,coord=coord)
# 这种方法不可取
# for i in range(9):
# print(sess.run([example,label]))
# 打印批处理的数据
print(sess.run([example_batch,label_batch]))
coord.request_stop()
coord.join(threads)
return None
if __name__=="__main__":
filename_list = os.listdir("./csvdata")
readcsv_decode(filename_list)
每次read的执行都会从文件中读取一行内容,注意,(这与后面的图片和TfRecords读取不一样),decode_csv操作会解析这一行内容并将其转为张量列表。如果输入的参数有缺失,record_default参数可以根据张量的类型来设置默认值。在调用run或者eval去执行read之前,你必须调用tf.train.start_queue_runners来将文件名填充到队列。否则read操作会被阻塞到文件名队列中有值为止。
图像操作
图像基本概念
在图像数字化表示当中,分为黑白和彩色两种。在数字化表示图片的时候,有三个因素。分别是图片的长、图片的宽、图片的颜色通道数。那么黑白图片的颜色通道数为1,它只需要一个数字就可以表示一个像素位;而彩色照片就不一样了,它有三个颜色通道,分别为RGB,通过三个数字表示一个像素位。TensorFlow支持JPG、PNG图像格式,RGB、RGBA颜色空间。图像用与图像尺寸相同(heightwidthchnanel)张量表示。图像所有像素存在磁盘文件,需要被加载到内存。
图像大小压缩
大尺寸图像输入占用大量系统内存。训练CNN需要大量时间,加载大文件增加更多训练时间,也难存放多数系统GPU显存。大尺寸图像大量无关本征属性信息,影响模型泛化能力。最好在预处理阶段完成图像操作,缩小、裁剪、缩放、灰度调整等。图像加载后,翻转、扭曲,使输入网络训练信息多样化,缓解过拟合。Python图像处理框架PIL、OpenCV。TensorFlow提供部分图像处理方法。
- tf.image.resize_images 压缩图片导致定大小
图像数据读取实例
同样图像加载与二进制文件相同。图像需要解码。输入生成器(tf.train.string_input_producer)找到所需文件,加载到队列。tf.WholeFileReader 加载完整图像文件到内存,WholeFileReader.read 读取图像,tf.image.decode_jpeg 解码JPEG格式图像。图像是三阶张量。RGB值是一阶张量。加载图像格 式为[batch_size,image_height,image_width,channels]。批数据图像过大过多,占用内存过高,系统会停止响应。直接加载TFRecord文件,可以节省训练时间。支持写入多个样本。
读取图片数据到Tensor
管道读端多文件内容处理
但是会发现read只返回一个图片的值。所以我们在之前处理文件的整个流程中,后面的内容队列的出队列需要用特定函数去获取。
- tf.train.batch 读取指定大小(个数)的张量
- tf.train.shuffle_batch 乱序读取指定大小(个数)的张量
def readpic_decode(file_list):
"""
批量读取图片并转换成张量格式
:param file_list: 文件名目录列表
:return: None
"""
# 构造文件队列
file_queue = tf.train.string_input_producer(file_list)
# 图片阅读器和读取数据
reader = tf.WholeFileReader()
key,value = reader.read(file_queue)
# 解码成张量形式
image_first = tf.image.decode_jpeg(value)
print(image_first)
# 缩小图片到指定长宽,不用指定通道数
image = tf.image.resize_images(image_first,[256,256])
# 设置图片的静态形状
image.set_shape([256,256,3])
print(image)
# 批处理图片数据,tensors是需要具体的形状大小
image_batch = tf.train.batch([image],batch_size=100,num_threads=1,capacity=100)
tf.summary.image("pic",image_batch)
with tf.Session() as sess:
merged = tf.summary.merge_all()
filewriter = tf.summary.FileWriter("/tmp/summary/dog/",graph=sess.graph)
# 线程协调器
coord = tf.train.Coordinator()
# 开启线程
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
print(sess.run(image_batch))
summary = sess.run(merged)
filewriter.add_summary(summary)
# 等待线程回收
coord.request_stop()
coord.join(threads)
return None
if __name__=="__main__":
# 获取文件列表
filename = os.listdir("./dog/")
# 组合文件目录和文件名
file_list = [os.path.join("./dog/",file) for file in filename]
# 调用读取函数
readpic_decode(file_list)
读取TfRecords文件数据
#CIFAR-10的数据读取以及转换成TFRecordsg格式
#1、数据的读取
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("data_dir","./cifar10/cifar-10-batches-bin/","CIFAR数据目录")
tf.app.flags.DEFINE_integer("batch_size",50000,"样本个数")
tf.app.flags.DEFINE_string("records_file","./cifar10/cifar.tfrecords","tfrecords文件位置")
class CifarRead(object):
def __init__(self,filename):
self.filelist = filename
# 定义图片的长、宽、深度,标签字节,图像字节,总字节数
self.height = 32
self.width = 32
self.depth = 3
self.label_bytes = 1
self.image_bytes = self.height*self.width*self.depth
self.bytes = self.label_bytes + self.image_bytes
def readcifar_decode(self):
"""
读取数据,进行转换
:return: 批处理的图片和标签
"""
# 1、构造文件队列
file_queue = tf.train.string_input_producer(self.filelist)
# 2、构造读取器,读取内容
reader = tf.FixedLengthRecordReader(self.bytes)
key,value = reader.read(file_queue)
# 3、文件内容解码
image_label = tf.decode_raw(value,tf.uint8)
# 分割标签与图像张量,转换成相应的格式
label = tf.cast(tf.slice(image_label,[0],[self.label_bytes]),tf.int32)
image = tf.slice(image_label,[self.label_bytes],[self.image_bytes])
print(image)
# 给image设置形状,防止批处理出错
image_tensor = tf.reshape(image,[self.height,self.width,self.depth])
print(image_tensor.eval())
# depth_major = tf.reshape(image, [self.depth,self.height, self.width])
# image_tensor = tf.transpose(depth_major, [1, 2, 0])
# 4、处理流程
image_batch,label_batch = tf.train.batch([image_tensor,label],batch_size=10,num_threads=1,capacity=10)
return image_batch,label_batch
def convert_to_tfrecords(self,image_batch,label_batch):
"""
转换成TFRecords文件
:param image_batch: 图片数据Tensor
:param label_batch: 标签数据Tensor
:param sess: 会话
:return: None
"""
# 创建一个TFRecord存储器
writer = tf.python_io.TFRecordWriter(FLAGS.records_file)
# 构造每个样本的Example
for i in range(10):
print("---------")
image = image_batch[i]
# 将单个图片张量转换为字符串,以可以存进二进制文件
image_string = image.eval().tostring()
# 使用eval需要注意的是,必须存在会话上下文环境
label = int(label_batch[i].eval()[0])
# 构造协议块
example = tf.train.Example(features=tf.train.Features(feature={
"image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_string])),
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
})
)
# 写进文件
writer.write(example.SerializeToString())
writer.close()
return None
def read_from_tfrecords(self):
"""
读取tfrecords
:return: None
"""
file_queue = tf.train.string_input_producer(["./cifar10/cifar.tfrecords"])
reader = tf.TFRecordReader()
key, value = reader.read(file_queue)
features = tf.parse_single_example(value, features={
"image":tf.FixedLenFeature([], tf.string),
"label":tf.FixedLenFeature([], tf.int64),
})
image = tf.decode_raw(features["image"], tf.uint8)
# 设置静态形状,可用于转换动态形状
image.set_shape([self.image_bytes])
print(image)
image_tensor = tf.reshape(image,[self.height,self.width,self.depth])
print(image_tensor)
label = tf.cast(features["label"], tf.int32)
print(label)
image_batch, label_batch = tf.train.batch([image_tensor, label],batch_size=10,num_threads=1,capacity=10)
print(image_batch)
print(label_batch)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
print(sess.run([image_batch, label_batch]))
coord.request_stop()
coord.join(threads)
return None
if __name__=="__main__":
# 构造文件名字的列表
filename = os.listdir(FLAGS.data_dir)
file_list = [os.path.join(FLAGS.data_dir, file) for file in filename if file[-3:] == "bin"]
cfar = CifarRead(file_list)
# image_batch,label_batch = cfar.readcifar_decode()
cfar.read_from_tfrecords()
with tf.Session() as sess:
# 构建线程协调器
coord = tf.train.Coordinator()
# 开启线程
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# print(sess.run(image_batch))
# 存进文件
# cfar.convert_to_tfrecords(image_batch, label_batch)
coord.request_stop()
coord.join(threads)
可视化学习Tensorboard
TensorBoard 涉及到的运算,通常是在训练庞大的深度神经网络中出现的复杂而又难以理解的运算。为了更方便 TensorFlow 程序的理解、调试与优化,发布了一套叫做 TensorBoard 的可视化工具。你可以用 TensorBoard 来展现你的 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据。


数据序列化-events文件
TensorBoard 通过读取 TensorFlow 的事件文件来运行。TensorFlow 的事件文件包括了你会在 TensorFlow 运行中涉及到的主要数据。事件文件的生成通过在程序中指定tf.summary.FileWriter存储的目录,以及要运行的图
tf.summary.FileWriter('/tmp/summary/test/', graph=default_graph)
启动TensorBoard
要运行TensorBoard,请使用以下命令
tensorboard --logdir=path/to/log-directory
其中logdir指向其FileWriter序列化其数据的目录。如果此logdir目录包含从单独运行中包含序列化数据的子目录,则TensorBoard将可视化所有这些运行中的数据。一旦TensorBoard运行,浏览您的网页浏览器localhost:6006来查看TensorBoard
节点符号
下图给出了节点符号以及意义:

我们以下面代码来详细介绍一下整个主图的结构:
import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
with tf.name_scope("name1") as scope:
a = tf.Variable([1.0,2.0],name="a")
with tf.name_scope("name2") as scope:
b = tf.Variable(tf.zeros([20]),name="b")
c = tf.Variable(tf.ones([20]),name="c")
with tf.name_scope("cal") as scope:
d = tf.concat([b,c],0)
e = tf.add(a,5)
with tf.Session(graph=graph) as sess:
tf.global_variables_initializer().run()
# merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter('/tmp/summary/test/', graph=sess.graph)
sess.run([d,e])
我们定义了三个名称域,分别为name1,name2和cal,我们可以清晰的从图中看出。

那么所有的常数、变量或者操作都在对应的名称域中,我们可以通过点击加号或者减号来查看详细内容。在name1中,有我们定义的变量a,依赖于初始化,并且也有对应的张量的阶。同样在name2中,有变量b和c。图中实线是我们整个程序的数据流向边。在cal名称域中,有两个运算操作,数据从前面两个名称域中流入。
一般来说,如果一个程序中名称域利用的好,可以使你的主图的结构更加清晰。反之,则会显得非常混乱
节点详细信息
我们每点击一个节点在整个tensorboard右上角会出现节点的详细信息。

上面会详细列出节点的子节点数、属性以及输入输出。
添加节点汇总操作
那么tensorboard还提供了另外重要的功能,那就是追踪程序中的变量以及图片相关信息,也就是可以一直观察程序中的变量值的变化曲线首先在构建计算图的时候一个变量一个变量搜集,构建完后将这些变量合并然后在训练过程中写入到事件文件中。
收集操作
- tf.summary.scalar() 收集对于损失函数和准确率等单值变量
- tf.summary.histogram() 收集高维度的变量参数
- tf.summary.image() 收集输入的图片张量能显示图片
下面使用部分代码,说明了如何去收集变量并写入事件文件。
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("loss",cross_entropy)
tf.summary.scalar("accuracy", accuracy)
tf.summary.histogram("W",W)
然后合并所有的变量,将这些信息一起写入事件文件中
# 合并
merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(FLAGS.summary_dir, graph=sess.graph)
# 运行
summary = sess.run(merged)
#写入
summary_writer.add_summary(summary,i)
通过运行tensorboard,我们可以看见这样的结果,很直观的显示了变量在训练过程中的变化过程。


神经网络与深度学习
深度学习(deep learning)是机器学习拉出的分支,它试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。深度学习是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。深度学习的好处是用非监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
至今已有数种深度学习框架,如深度神经网络、卷积神经网络和深度置信网络和递归神经网络已被应用计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
神经网络,一种启发自生物学的优美的编程范式,能够从观测到的数据中进行学习
图像分类
图像分类问题,这是从固定的一组分类中分配输入图像一个标签的任务。这是计算机视觉的核心问题之一,尽管它的简单性,有各种各样的实际应用。此外,正如我们将在后面看到的,许多其他看似不同的计算机视觉任务(如对象检测,分割)可以减少到图像分类。
图像分类模型需要单个图像,并将概率分配给4个标签{cat,dog,hat,mug}。如图所示,请记住,对于计算机,图像被表示为数字的一个大的3维数组。在这个例子中,猫图像是248像素宽,400像素高,并且有三个颜色通道红色,绿色,蓝色(或简称RGB)。因此,该图像由248 x 400 x 3数字组成,总共297,600个数字。每个数字是一个整数,范围从0(黑色)到255(白色)。我们的任务是把这个四分之一的数字转成一个单一的标签,如“猫”。

由于识别视觉概念(例如猫)的这个任务对于人类来说相对微不足道,所以值得从计算机视觉算法的角度考虑所涉及的挑战。
数据驱动的方法
我们可以如何编写一个可以将图像分类到不同类别的算法?与编写一个算法(例如排序数字列表)不同的是,如何编写用于识别图像中的猫的算法是不明显的。因此,我们不会试图指定每个类别的每一个代码直接在代码中,我们将为计算机提供许多示例每个类,然后开发学习算法,查看这些例子,并了解每个类的视觉外观。这种方法被称为数据驱动方法,因为它依赖于首先累积标记图像的训练数据集。

神经网络基础与人工神经网络
神经网络方面的研究很早就已出现,今天“神经网络”已是一个相当大的、多学科交叉的学科领域。神经网络中最基本的成分是神经元模型。

上图中每个圆圈都是一个神经元,每条线表示神经元之间的连接。我们可以看到,上面的神经元被分成了多层,层与层之间的神经元有连接,而层内之间的神经元没有连接。
感知器
为了理解神经网络,我们应该先理解神经网络的组成单元——神经元。神经元也叫做感知器。还记得之前的线性回归模型中权重的作用吗?每一个输入值与对应权重的乘积之和得到的数据或通过激活函数来进行判别。下面我们看一下感知器:

可以看到,一个感知器有如下组成部分:
- 输入权值,一个感知器可以有多个输入x_1,x_2,x_3...x_nx1,x2,x3...xn,每个输入上有一个权值w_iwi
- 激活函数,感知器的激活函数有许多选择,以前用的是阶跃函数,sigmoid\left(\frac{1}{1+e^{w*x}}\right)sigmoid(1+ew∗x1),其中zz为权重数据积之和
- 输出,y{=}f\left({w*x}{+}{b}\right)y=f(w∗x+b)
我们了解过sigmoid函数是这样,在之前的线性回归中它对于 二类分类 问题非常擅长。所以在后续的多分类问题中,我们会用到其它的激活函数

神经网络
那么我们继续往后看,神经网络是啥?

神经网络其实就是按照一定规则连接起来的多个神经元。
- 输入向量的维度和输入层神经元个数相同
- 第N层的神经元与第N-1层的所有神经元连接,也叫 全连接
- 上图网络中最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,可以有多个输出层。我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
- 而且同一层的神经元之间没有连接
- 并且每个连接都有一个权值,
那么我们以下面的例子来看一看,图上已经标注了各种输入、权重信息。

对于每一个样本来说,我们可以得到输入值x_1,x_2,x_3x1,x2,x3,也就是节点1,2,3的输入值,那么对于隐层每一个神经元来说都对应有一个偏置项bb,它和权重一起才是一个完整的线性组合
{a_4}{=}sigmoid\left({W_{41}* x_1}{+}{W_{42}* x_2}{+}{W_{43}* x_3}{+}{W_{4b}}\right)a4=sigmoid(W41∗x1+W42∗x2+W43∗x3+W4b)
{a_5}{=}sigmoid\left({W_{51}* x_1}{+}{W_{52}* x_2}{+}{W_{53}* x_3}{+}{W_{5b}}\right)a5=sigmoid(W51∗x1+W52∗x2+W53∗x3+W5b)
{a_6}{=}sigmoid\left({W_{61}* x_1}{+}{W_{62}* x_2}{+}{W_{63}* x_3}{+}{W_{6b}}\right)a6=sigmoid(W61∗x1+W62∗x2+W63∗x3+W6b)
{a_7}{=}sigmoid\left({W_{71}* x_1}{+}{W_{72}* x_2}{+}{W_{73}* x_3}{+}{W_{7b}}\right)a7=sigmoid(W71∗x1+W72∗x2+W73∗x3+W7b)
这样得出隐层的输出,也就是输出层的输入值.
矩阵表示

同样,对于输出层来说我们已经得到了隐层的值,可以通过同样的操作得到输出层的值。那么重要的一点是,分类问题的类别个数决定了你的输出层的神经元个数
神经网络的训练
我们可以说神经网络是一个模型,那么这些权值就是模型的参数,也就是模型要学习的东西。然而,一个神经网络的连接方式、网络的层数、每层的节点数这些参数,则不是学习出来的,而是人为事先设置的。对于这些人为设置的参数,我们称之为超参数。
前向传播
神经网络的训练类似于之前线性回归中的训练优化过程。前面我们已经提到过梯度下降的意义,我们可以分为这么几步:
-
计算结果误差
-
通过梯度下降找到误差最小
-
更新权重以及偏置项
这样我们可以得出每一个参数在进行一次计算结果之后,通过特定的数学理论优化误差后会得出一个变化率\alphaα
反向传播
就是说通过误差最小得到新的权重等信息,然后更新整个网络参数。通常我们会指定学习的速率\lambdaλ(超参数),通过 变化率和学习速率 率乘积,得出各个权重以及偏置项在一次训练之后变化多少,以提供给第二次训练使用

tensorflow神经网络接口的实现
tf.train.GradientDescentOptimizer
在使用梯度下降时候,一般需要指定学习速率
tf.train.GradientDescentOptimizer(0.5)
方法
init
构造一个新的梯度下降优化器
__init__(
learning_rate,
use_locking=False,
name='GradientDescent'
)
- learning_rate tensor或者浮点值,用于学习速率
minimize
添加操作以更新最小化loss,这种方法简单结合调用compute_gradients()和 apply_gradients()(这两个方法也是梯度下降优化器的方法)。如果要在应用它们之前处理梯度,则调用compute_gradients()和apply_gradients()显式而不是使用此函数。
minimize(
loss,
global_step=None,
var_list=None,
gate_gradients=GATE_OP,
aggregation_method=None,
colocate_gradients_with_ops=False,
name=None,
grad_loss=None
)
- loss 损失值,变量值
- global_step 变量,在每次更新之后加1
ANN网络分析
Mnist手写数字识别
Mnist数据集可以从官网下载,网址: http://yann.lecun.com/exdb/mnist/ 下载下来的数据集被分成两部分:55000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为“xs”,把这些标签设为“ys”。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels。

我们可以知道图片是黑白图片,每一张图片包含28像素X28像素。我们把这个数组展开成一个向量,长度是 28x28 = 784。因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量。

MNIST中的每个图像都具有相应的标签,0到9之间的数字表示图像中绘制的数字。用的是one-hot编码

one-hot编码
独热编码将分类特征转换为使用分类和回归算法更好的格式,我们看下面这个例子。有七个分类数据的样本输入属于四类。现在,我可以将这些编码到我所做的这些名义值,但是从机器学习的角度来看这是不合适的。我们不能说“企鹅”的类别大于或小于“人”。那么他们只是单纯的序数值,而不是名义值。

我们做的是为每个类别生成一个布尔列。这些列中只有一列可以为每个样本取值1。因此,术语一个热编码。

tf.one_hot
tf.one_hot(indices, depth, on_value=None, off_value=None, axis=None, dtype=None, name=None)
- indices 在独热编码中位置,即数据集标签
- depth 张量的深度,即类别数
indices = [0, 1, 2, 1]
depth = 3
[[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[1., 1., 0.]]
SoftMax回归
MNIST中的每个图像都是零到九之间的手写数字。所以给定的图像只能有十个可能的东西。我们希望能够看到一个图像,并给出它是每个数字的概率。例如,我们的模型可能会看到一个九分之一的图片,80%的人肯定它是一个九,但是给它一个5%的几率是八分之一(因为顶级循环),并有一点概率所有其他,因为它不是100%确定。这是一个经典的情况,其中softmax回归是一种自然简单的模型。如果要将概率分配给几个不同的东西之一的对象,softmax是要做的事情,因为softmax给出了一个[0,1]之间的概率值加起来为1的列表。稍后,当我们训练更复杂型号,最后一步将是一层softmax。
那么我们通常说的激活函数有很多,我们这个使用softmax函数.softmax模型可以用来给不同的对象分配概率。即使在之后,我们训练更加精细的模型时,最后一步也需要用softmax来分配概率。这里的softmax可以看成是一个激励(activation)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。
softmax回归有两个步骤:首先我们将我们的输入的证据加在某些类中,然后将该证据转换成概率。每个输出的概率,对应着独热编码中具体的类别。
下面是softmax的公式:
\text{softmax}(x)_i=\frac{\exp(x_i)}{\sum_j\exp(x_j)}softmax(x)i=∑jexp(xj)exp(xi)
在神经网络中,整个过程如下:

也就是最后的softmax模型,用数学式子表示:
y=\text{softmax}(Wx + b)y=softmax(Wx+b)
损失计算-交叉熵损失
我们前面学习过了一种计算误差损失,预测值与标准值差的平方和。不过在这里我们不能再使用这个方式,我们的输出值是概率并且还有标签。那么就需要一种更好的方法形容这个分类过程的好坏。这里就要用到交叉熵损失。
确定模型损失的一个非常常见的非常好的功能称为“交叉熵”。交叉熵来源于对信息理论中的信息压缩代码的思考,但是从赌博到机器学习在很多领域都是一个重要的思想。它定义为
H_{y'}(y){=}-\sum_iy'_ilog\left(y_i\right)Hy′(y)=−∑iyi′log(yi)
它表示的是目标标签值与经过权值求和过后的对应类别输出值
tf.nn.softmax_cross_entropy_with_logits
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
计算logits与labels之间的softmax交叉熵损失,该函数已经包含了softmax功能,logits和labels必须有相同的形状[batch_size, num_classes]和相同的类型(float16, float32, or float64)。
- labels 独热编码过的标签值
- logits 没有log调用过的输入值
- 返回 交叉熵损失列表
tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y))
实现神经网络模型
获取数据
tensorflow提供给我们下载mnist数据集的接口,需要指定下载目录
from tensorflow.examples.tutorials.mnist import input_data
# 输入数据
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
计算数据
我们需要生成权重和偏置初始值,为了随时能够接收输入值,需要构造输入占位符
# 建立输入数据占位符
x = tf.placeholder(tf.float32, [None, 784])
#初始化权重和偏置
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# 输出结果
y = tf.matmul(x, W) + b
梯度下降优化与训练
我们知道我们想要我们的模型做什么,很容易让TensorFlow训练它来做到这一点。因为TensorFlow知道计算的整个图形,它可以自动使用反向传播算法来有效地确定变量如何影响您要求最小化的损失。那么它可以应用您选择的优化算法来修改变量并减少损失。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
我们每次提供一部分值,然后多次进行训练train_step,使之不断的更新
# 训练
for i in range(1000):
print("第%d次训练"%(i))
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_label: batch_ys})
模型正确率评估
有了目标值标签以及我们模型的输出值,就可以比较两者相同率,我们使用tf.argmax,这是一个非常有用的功能,它给出沿某个轴的张量中最高条目的索引
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
然后这给了我们一个布尔的列表。为了确定哪个部分是正确的,我们转换为浮点数,然后取平均值。例如, [True, False, True, True]会变成[1,0,1,1]哪一个0.75
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
跟踪变量
同时为了在tensorboard更好的观察变量的变化,我们去进行节点汇总操作,我们观察损失、准确率以及高维变量WW的变化
tf.summary.scalar("loss",cross_entropy)
tf.summary.scalar("accuracy", accuracy)
tf.summary.histogram("W",W)
完整代码:
from __future__ import absolute_import
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('data_dir', '/tmp/tensorflow/mnist/input_data',
"""数据集目录""")
tf.app.flags.DEFINE_integer('max_steps', 2000,
"""训练次数""")
tf.app.flags.DEFINE_string('summary_dir', '/tmp/summary/mnist/train',
"""事件文件目录""")
def main(sess):
# 输入数据
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
# 建立输入数据占位符
x = tf.placeholder(tf.float32, [None, 784])
# 初始化权重和偏置
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# 输出结果y
y = tf.matmul(x, W) + b
# 建立类别占位符
y_label = tf.placeholder(tf.float32, [None, 10])
# 计算交叉熵损失平均值
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y))
# 生成优化损失操作
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# 比较结果
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
# 计算正确率平均值
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("loss",cross_entropy)
tf.summary.scalar("accuracy", accuracy)
tf.summary.histogram("W",W)
tf.global_variables_initializer().run()
# 合并所有摘要
merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(FLAGS.summary_dir, graph=sess.graph)
# 训练
for i in range(1000):
print("第%d次训练"%(i))
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_label: batch_ys})
print(sess.run(accuracy,feed_dict={x: batch_xs, y_label: batch_ys}))
summary = sess.run(merged,feed_dict={x: batch_xs, y_label: batch_ys})
summary_writer.add_summary(summary,i)
# 模型在测试数据的准确率
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
test_accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("测试数据准确率:")
print(sess.run(test_accuracy, feed_dict={x: mnist.test.images,y_label: mnist.test.labels}))
if __name__ == '__main__':
with tf.Session() as sess:
main(sess)卷积神经网络与图像识别
我们介绍了人工神经网络,以及它的训练和使用。我们用它来识别了手写数字,然而,这种结构的网络对于图像识别任务来说并不是很合适。本文将要介绍一种更适合图像、语音识别任务的神经网络结构——卷积神经网络(Convolutional Neural Network, CNN)。说卷积神经网络是最重要的一种神经网络也不为过,它在最近几年大放异彩,几乎所有图像、语音识别领域的重要突破都是卷积神经网络取得的,比如谷歌的GoogleNet、微软的ResNet等,打败李世石的AlphaGo也用到了这种网络。本文将详细介绍卷积神经网络以及它的训练算法,以及动手实现一个简单的卷积神经网络。
人工神经网络网络VS卷积神经网络
人工神经网络神经网络之所以不太适合图像识别任务,主要有以下几个方面的问题:
-
参数数量太多,在CIFAR-10(一个比赛数据集)中,图像只有大小为32x32x3(32宽,32高,3色通道),因此在正常神经网络的第一隐藏层中的单个完全连接的神经元将具有32 32 3 = 3072个权重。这个数量仍然是可控的,但显然这个完全连接的结构不会扩大到更大的图像。例如,一个更可观的大小的图像,例如200x200x3,会导致具有200 200 3 = 120,000重量的神经元。此外,我们几乎肯定会有几个这样的神经元,所以参数会加快!显然,这种完全连接是浪费的,而且大量的参数会很快导致过度配套。
-
没有利用像素之间的位置信息 对于图像识别任务来说,每个像素和其周围像素的联系是比较紧密的,和离得很远的像素的联系可能就很小了。如果一个神经元和上一层所有神经元相连,那么就相当于对于一个像素来说,把图像的所有像素都等同看待,这不符合前面的假设。当我们完成每个连接权重的学习之后,最终可能会发现,有大量的权重,它们的值都是很小的(也就是这些连接其实无关紧要)。努力学习大量并不重要的权重,这样的学习必将是非常低效的。
-
网络层数限制 我们知道网络层数越多其表达能力越强,但是通过梯度下降方法训练深度人工神经网络很困难,因为全连接神经网络的梯度很难传递超过3层。因此,我们不可能得到一个很深的全连接神经网络,也就限制了它的能力。
那么,卷积神经网络又是怎样解决这个问题的呢?主要有三个思路:
-
局部连接 这个是最容易想到的,每个神经元不再和上一层的所有神经元相连,而只和一小部分神经元相连。这样就减少了很多参数。
-
权值共享 一组连接可以共享同一个权重,而不是每个连接有一个不同的权重,这样又减少了很多参数。
-
下采样 可以使用Pooling来减少每层的样本数,进一步减少参数数量,同时还可以提升模型的鲁棒性。对于图像识别任务来说,卷积神经网络通过尽可能保留重要的参数,去掉大量不重要的参数,来达到更好的学习效果
现在可能还不能理解,那我们详细说明卷积神经网络。
卷积神经网络CNN
卷积神经网络与上一章中的普通神经网络非常相似:它们由具有学习权重和偏差的神经元组成。每个神经元接收一些输入,执行点积,并且可选地以非线性跟随它。整个网络仍然表现出单一的可微分评分功能:从一端的原始图像像素到另一个类的分数。并且在最后(完全连接)层上它们仍然具有损失函数(例如SVM / Softmax),并且我们为学习正常神经网络开发的所有技巧/技巧仍然适用。
CNN每一层都通过可微分的函数将一个激活的值转换为另一个,一般来说CNN具有卷积层,池化层和完全连接层FC(正如在常规神经网络中所见),在池化层之前一般会有个激活函数,我们将堆叠这些层,形成一个完整的架构。我们先看下大概的一个图:


CNN它将一个输入3D体积变换为输出3D体积,正常的神经网络不同,CNN具有三维排列的神经元:宽度,高度,深度。

卷积层

参数及结构
四个超参数控制输出体积的大小:过滤器大小,深度,步幅和零填充。得到的每一个深度也叫一个Feature Map。
卷积层的处理,在卷积层有一个重要的就是过滤器大小(需要自己指定),若输入值是一个[32x32x3]的大小(例如RGB CIFAR-10彩色图像)。如果每个过滤器(Filter)的大小为5×5,则CNN层中的每个Filter将具有对输入体积中的[5x5x3]区域的权重,总共5 5 3 = 75个权重(和+1偏置参数),输入图像的3个深度分别与Filter的3个深度进行运算。请注意,沿着深度轴的连接程度必须为3,因为这是输入值的深度,并且也要记住这只是一个Filter。
- 假设输入卷的大小为[16x16x20]。然后使用3x3的示例接收字段大小,CNN中的每个神经元现在将具有总共3 3 20 = 180个连接到输入层的连接。
卷积层的输出深度,那么一个卷积层的输出深度是可以指定的,输出深度是由你本次卷积中Filter的个数决定。加入上面我们使用了64个Filter,也就是[5,5,3,64],这样就得到了64个Feature Map,这样这64个Feature Map可以作为下一次操作的输入值
卷积层的输出宽度,输出宽度可以通过特定算数公式进行得出,后面会列出公式。
卷积输出值的计算
我们用一个简单的例子来讲述如何计算卷积,然后,我们抽象出卷积层的一些重要概念和计算方法。
假设有一个55的图像,使用一个33的filter进行卷积,得到了到一个33的Feature Map,至于得到33大小,可以自己去计算一下。如下所示:

我们看下它的计算过程,首先计算公式如下:

根据计算的例子,第一次:

第二次:

通过这样我们可以依次计算出Feature Map中所有元素的值。下面的动画显示了整个Feature Map的计算过程:

步长
那么在卷积神经网络中有一个概念叫步长,也就是Filter移动的间隔大小。上面的计算过程中,步幅(stride)为1。步幅可以设为大于1的数。例如,当步幅为2时,我们可以看到得出2*2大小的Feature Map,发现这也跟步长有关。Feature Map计算如下:




外围补充与多Filter
我们前面还曾提到,每个卷积层可以有多个filter。每个filter和原始图像进行卷积后,都可以得到一个Feature Map。因此,卷积后Feature Map的深度(个数)和卷积层的filter个数是相同的。
如果我们的步长移动与filter的大小不适合,导致不能正好移动到边缘怎么办?

以上就是卷积层的计算方法。这里面体现了局部连接和权值共享:每层神经元只和上一层部分神经元相连(卷积计算规则),且filter的权值对于上一层所有神经元都是一样的。
总结输出大小
-
输入体积大小H_1*W_1*D_1H1∗W1∗D1
-
四个超参数:
- Filter数量KK
- Filter大小FF
- 步长SS
- 零填充大小PP
-
输出体积大小H_2*W_2*D_2H2∗W2∗D2
- H_2 = (H_1 - F + 2P)/S + 1H2=(H1−F+2P)/S+1
- W_2 = (W_1 - F + 2P)/S + 1W2=(W1−F+2P)/S+1
- D_2 = KD2=K
新的激活函数-Relu
一般在进行卷积之后就会提供给激活函数得到一个输出值。我们不使用sigmoid,softmax,而使用Relu。该激活函数的定义是:
f(x)= max(0,x)f(x)=max(0,x)
Relu函数如下:

特点
- 速度快 和sigmoid函数需要计算指数和倒数相比,relu函数其实就是一个max(0,x),计算代价小很多
- 稀疏性 通过对大脑的研究发现,大脑在工作的时候只有大约5%的神经元是激活的,而采用sigmoid激活函数的人工神经网络,其激活率大约是50%。有论文声称人工神经网络在15%-30%的激活率时是比较理想的。因为relu函数在输入小于0时是完全不激活的,因此可以获得一个更低的激活率。
Pooling计算
Pooling层主要的作用是下采样,通过去掉Feature Map中不重要的样本,进一步减少参数数量。Pooling的方法很多,最常用的是Max Pooling。Max Pooling实际上就是在nn的样本中取最大值,作为采样后的样本值。下图是22 max pooling:

除了Max Pooing之外,常用的还有Mean Pooling——取各样本的平均值。对于深度为D的Feature Map,各层独立做Pooling,因此Pooling后的深度仍然为D。
过拟合解决办法
Dropout
为了减少过拟合,我们在输出层之前加入dropout。我们用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率。这样我们可以在训练过程中启用dropout,在测试过程中关闭dropout。 TensorFlow的tf.nn.dropout操作除了可以屏蔽神经元的输出外,还会自动处理神经元输出值的scale。所以用dropout的时候可以不用考虑scale。一般在全连接层之后进行Dropout
x= tf.nn.dropout(x_in, 1.0)
FC层
那么在卷积网络当中,为什么需要加上FC层呢?
前面的卷积和池化相当于做特征工程,后面的全连接相当于做特征加权。最后的全连接层在整个卷积神经网络中起到“分类器”的作用
实例探究
卷积网络领域有几种架构,名称。最常见的是:
-
LeNet。卷积网络的第一个成功应用是由Yann LeCun于1990年代开发的。其中最着名的是LeNet架构,用于读取邮政编码,数字等。
-
AlexNet。该推广卷积网络计算机视觉中的第一部作品是AlexNet,由亚历克斯·克里维斯基,伊利亚·萨茨基弗和吉奥夫·欣顿发展。AlexNet在2012年被提交给ImageNet ILSVRC挑战,明显优于第二名(与亚军相比,前5名错误为16%,26%的错误)。该网络与LeNet具有非常相似的体系结构,但是更深入,更大和更具特色的卷积层叠在彼此之上(以前通常只有一个CONV层紧随着一个POOL层)。
-
ZFNet。ILSVRC 2013获奖者是Matthew Zeiler和Rob Fergus的卷积网络。它被称为ZFNet(Zeiler&Fergus Net的缩写)。通过调整架构超参数,特别是通过扩展中间卷积层的大小,使第一层的步幅和过滤器尺寸更小,这是对AlexNet的改进。
-
GoogleNet。ILSVRC 2014获奖者是Szegedy等人的卷积网络。来自Google。其主要贡献是开发一个初始模块,大大减少了网络中的参数数量(4M,与AlexNet的60M相比)。此外,本文使用ConvNet顶部的“平均池”而不是“完全连接”层,从而消除了大量似乎并不重要的参数。GoogLeNet还有几个后续版本,最近的是Inception-v4。
-
VGGNet。2011年ILSVRC的亚军是来自Karen Simonyan和Andrew Zisserman的网络,被称为VGGNet。它的主要贡献在于表明网络的深度是良好性能的关键组成部分。他们最终的最佳网络包含16个CONV / FC层,并且吸引人的是,具有非常均匀的架构,从始至终只能执行3x3卷积和2x2池。他们预先训练的模型可用于Caffe的即插即用。VGGNet的缺点是评估和使用更多的内存和参数(140M)是更昂贵的。这些参数中的大多数都在第一个完全连接的层中,因此发现这些FC层可以在没有性能降级的情况下被去除,
-
ResNet。Kaiming He等人开发的残留网络 是ILSVRC 2015的获胜者。它具有特殊的跳过连接和批量归一化的大量使用。该架构在网络末端也缺少完全连接的层。读者也参考了凯明的演讲(视频,幻灯片),以及一些最近在火炬中复制这些网络的实验。ResNets目前是迄今为止最先进的卷积神经网络模型,并且是实际使用ConvNets的默认选择(截至2016年5月10日)。特别是,也看到最近从Kaiming He等人调整原有架构的发展。
下面就是VGGNet的结构:
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
与卷积网络一样,注意大多数内存(以及计算时间)都是在早期的CONV层中使用的,大多数参数都在最后的FC层。在这种特殊情况下,第一个FC层包含100M的权重,总共140M。
图像识别卷积网络实现案例
Mnist数据集卷积网络实现
前面在MNIST上获得92%的准确性是不好的,对于CNN网络来说,我们同样使用Mnist数据集来做案例,这可以使我们的准确率提升很多。在感受输入通道时不是那么明显,因为是黑白图像的只有一个输入通道。那么在Tensorflow中,神经网络相关的操作都在tf.nn模块中,包含了卷积、池化和损失等相关操作。
准备基础函数
初始化卷积层权重
为了创建这个模型,我们需要创建大量的权重和偏置项。这个模型中的权重在初始化时应该加入少量的噪声来打破对称性以及避免0梯度。由于我们使用的是ReLU神经元,因此比较好的做法是用一个较小的正数来初始化偏置项,以避免神经元节点输出恒为0的问题(dead neurons)。为了不在建立模型的时候反复做初始化操作,我们定义两个函数用于初始化。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
卷积和池化
首先介绍一下Tensorflow当中的卷积和池化操作。
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
ARGS:
- input:A Tensor。必须是以下类型之一:float32,float64。
- filter:A Tensor。必须有相同的类型input。
- strides:列表ints。1-D长度4.每个尺寸的滑动窗口的步幅input。
- paddingA string来自:"SAME", "VALID"。使用的填充算法的类型。
- use_cudnn_on_gpu:可选bool。默认为True。
- name:操作的名称(可选)。
tf.nn.max_pool(value, ksize, strides, padding, name=None)
ARGS:
- value:A 4-D Tensor具有形状[batch, height, width, channels]和类型float32,float64,qint8,quint8,qint32。
- ksize:长度> = 4的int列表。输入张量的每个维度的窗口大小。
- strides:长度> = 4的int列表。输入张量的每个维度的滑动窗口的跨度。
- padding:一个字符串,或者'VALID'或'SAME'。填补算法。
- name:操作的可选名称。
TensorFlow在卷积和池化上有很强的灵活性。我们使用步长为2,1个零填充边距的模版。池化选择2*2大小。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
CNN实现
本次案例我们使用两层卷积池化,两个全连接层以及添加一个解决过拟合方法
输入数据占位符准备
我们在训练的过程中需要一直提供数据,所以我们准备一些占位符,以备训练的时候填充。并且我们把x变成一个4d向量,其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(因为是灰度图所以这里的通道数为1,如果是rgb彩色图,则为3)。
with tf.variable_scope("data") as scope:
y_label = tf.placeholder(tf.float32, [None, 10])
x = tf.placeholder(tf.float32, [None, 784])
x_image = tf.reshape(x, [-1, 28, 28, 1])
第一层卷积加池化
卷积的权重张量形状是[5, 5, 1, 32],前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目。 而对于每一个输出通道都有一个对应的偏置量。 我们把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max pooling。同样为了便于观察将高位变量W_con1、b_con1添加到事件文件中。
with tf.variable_scope("conv1") as scope:
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
tf.summary.histogram('W_con1', W_conv1)
tf.summary.histogram('b_con1', b_conv1)
第二层卷积加池化
为了构建一个更深的网络,我们会把几个类似的层堆叠起来。第二层中,接受上一层的输出32各通道,我们同样用5x5的的过滤器大小,指定输出64个通道。将高位变量W_con2、b_con2添加到事件文件中。
with tf.variable_scope("conv2") as scope:
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
tf.summary.histogram('W_con2', W_conv2)
tf.summary.histogram('b_con2', b_conv2)
两个全连接层
进行了两次卷积池化之后,数据量得到有效减少,并且也相当于进行了一些特征选择。那么现在就需要将所有数据进行权重乘积求和,来进行特征加权,这样就得到了输出结果,同时也可以提供给交叉熵进行优化器优化。将高位变量W_fc1、b_fc1、W_fc2、b_fc2添加到事件文件中。
with tf.variable_scope("fc1") as scope:
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
tf.summary.histogram('W_fc1', W_fc1)
tf.summary.histogram('b_fc1', b_fc1)
with tf.variable_scope("fc2") as scope:
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
tf.summary.histogram('W_fc2', W_fc2)
tf.summary.histogram('b_fc2', b_fc2)
计算损失
通过交叉熵进行计算,将损失添加到事件文件当中
def total_loss(y_conv,y_label):
"""
计算损失
:param y_conv: 模型输出
:param y_label: 数据标签
:return: 返回损失
"""
with tf.variable_scope("train") as scope:
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y_conv))
tf.summary.scalar("loss", cross_entropy)
return cross_entropy
训练
mnist数据是一个稀疏的数据矩阵,所以我们的优化器选择AdamOptimizer,同时指定学习率。通过tf.equal和tf.argmax来求准确率
def train(loss,sess,placeholder):
"""
训练模型
:param loss: 损失
:param sess: 会话
:param placeholder: 占位符,用于填充数据
:return: None
"""
# 生成梯度下降优化器
train_step = tf.train.AdamOptimizer(1e-4).minimize(loss)
# 计算准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("accuracy", accuracy)
# 初始化变量
tf.global_variables_initializer().run()
# 合并所有摘要
merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(FLAGS.summary_dir, graph=sess.graph)
# 循环训练
for i in range(FLAGS.max_steps):
batch_xs,batch_ys = mnist.train.next_batch(50)
# 每过100次进行一次输出
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={placeholder[0]: batch_xs, placeholder[1]: batch_ys, placeholder[2]: 1.0})
print("第%d轮,准确率:%f" % (i, train_accuracy))
summary = sess.run(merged, feed_dict={placeholder[0]: batch_xs, placeholder[1]: batch_ys, placeholder[2]: 1.0})
summary_writer.add_summary(summary,i)
train_step.run(feed_dict={placeholder[0]: batch_xs, placeholder[1]: batch_ys, placeholder[2]: 1.0})
print("测试数据准确率:%g" % accuracy.eval(feed_dict={placeholder[0]: mnist.test.images, placeholder[1]: mnist.test.labels, placeholder[2]: 1.0}))
输出结果以及显示
通过几分钟的训练等待,我们可以启用tensorboard来查看训练过程以及结果,pycharm中的结果为:

损失和准确率:

卷积参数:

全连接参数:

计算图:

完整代码如下
from __future__ import absolute_import
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('data_dir', '/tmp/tensorflow/mnist/input_data',
"""数据集目录""")
tf.app.flags.DEFINE_integer('max_steps', 2000,
"""训练次数""")
tf.app.flags.DEFINE_string('summary_dir', '/tmp/summary/mnist/convtrain',
"""事件文件目录""")
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')
def reference():
"""
得到模型输出
:return: 模型输出与数据标签
"""
with tf.variable_scope("data") as scope:
y_label = tf.placeholder(tf.float32, [None, 10])
x = tf.placeholder(tf.float32, [None, 784])
x_image = tf.reshape(x, [-1, 28, 28, 1])
with tf.variable_scope("conv1") as scope:
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
tf.summary.histogram('W_con1', W_conv1)
tf.summary.histogram('b_con1', b_conv1)
with tf.variable_scope("conv2") as scope:
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
tf.summary.histogram('W_con2', W_conv2)
tf.summary.histogram('b_con2', b_conv2)
with tf.variable_scope("fc1") as scope:
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
tf.summary.histogram('W_fc1', W_fc1)
tf.summary.histogram('b_fc1', b_fc1)
with tf.variable_scope("fc2") as scope:
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
tf.summary.histogram('W_fc2', W_fc2)
tf.summary.histogram('b_fc2', b_fc2)
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
return y_conv,y_label,(x,y_label,keep_prob)
def total_loss(y_conv,y_label):
"""
计算损失
:param y_conv: 模型输出
:param y_label: 数据标签
:return: 返回损失
"""
with tf.variable_scope("train") as scope:
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y_conv))
tf.summary.scalar("loss", cross_entropy)
return cross_entropy
def train(loss,sess,placeholder):
"""
训练模型
:param loss: 损失
:param sess: 会话
:param placeholder: 占位符,用于填充数据
:return: None
"""
# 生成梯度下降优化器
train_step = tf.train.AdamOptimizer(1e-4).minimize(loss)
# 计算准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("accuracy", accuracy)
# 初始化变量
tf.global_variables_initializer().run()
# 合并所有摘要
merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(FLAGS.summary_dir, graph=sess.graph)
# 循环训练
for i in range(FLAGS.max_steps):
batch_xs,batch_ys = mnist.train.next_batch(50)
# 每过100次进行一次输出
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={placeholder[0]: batch_xs, placeholder[1]: batch_ys, placeholder[2]: 1.0})
print("第%d轮,准确率:%f" % (i, train_accuracy))
summary = sess.run(merged, feed_dict={placeholder[0]: batch_xs, placeholder[1]: batch_ys, placeholder[2]: 1.0})
summary_writer.add_summary(summary,i)
train_step.run(feed_dict={placeholder[0]: batch_xs, placeholder[1]: batch_ys, placeholder[2]: 1.0})
print("测试数据准确率:%g" % accuracy.eval(feed_dict={placeholder[0]: mnist.test.images, placeholder[1]: mnist.test.labels, placeholder[2]: 1.0}))
if __name__ == '__main__':
with tf.Session() as sess:
y_conv,y_label,placeholder = reference()
loss = total_loss(y_conv,y_label)
train(loss,sess,placeholder)
网络优化改进
网络优化的方法有很多,在这里我们使用其中一种优化方式。在我们的模型训练时候,会有一个重要的因素需要设定,就是学习率。那么在手动设定学习率的时候不一定准确。 这种人为的设定对于模型的输出影响较大。所以在这里引入了一种自动更新学习率的函数。
指数衰减学习率exponential_decay
class tf.train.exponential_decay(learning_rate, global_step, decay_steps, decay_rate, staircase=False, name=None)
"""
实现学习率指数衰减
:param learning_rate:初始的学习率
:param global_step:全局的训练步数(样本学习了多少次)
:param decay_steps:衰减系数(每多少步衰减decay_rate)
:param decay_rate:衰减的速度
:param staircase:默认为False,如果设置为True时,将(global_step / decay_ steps)转换成整数
"""
那么衰减的公式为learningrate * decay_rate ^ (global_step / decay steps)
使用
# 让学习率根据步伐,自动变换学习率,指定了每10步衰减基数为0.99,0.001为初始的学习率
lr = tf.train.exponential_decay(0.001,
global_step,
10,
0.99,
staircase=True)
# 优化器
train_op = tf.train.GradientDescentOptimizer(lr).minimize(loss, global_step=global_step)
多分类图像识别案例
CIFAR-10
CIFAR-10数据集由10个类别的60000 32x32彩色图像组成,每个类别有6000张图像。有50000个训练图像和10000个测试图像。数据集分为五个训练集和一个测试集,每个集有10000个图像。测试集包含来自每个类的正好1000个随机选择的图像。训练集的每个类别5000个图像。图像类别如下:

下载数据集
可以去官网下载,https://www.cs.toronto.edu/~kriz/cifar.html
里面有很多种版本我们下载 CIFAR-10二进制版本。
二进制版本格式
二进制版本包含文件data_batch_1.bin,data_batch_2.bin,data_batch_4.bin,data_batch_5.bin以及test_batch.bin。这些文件的格式如下:
<1 x label> <3072 x像素>
...
<1 x label> <3072 x像素>
第一个字节是第一个图像的标签,它是0-9范围内的数字。接下来的3072个字节是图像像素的值。前1024个字节是红色通道值,接下来是1024个绿色,最后1024个是蓝色。
所以每个文件包含10000个这样的3073字节的“行”的图像,还有一个名为batches.meta.txt的文件。这是一个ASCII文件,将范围为0-9的数字标签映射到有意义的类名。
图片信息的读取与写入
二进制文件的读取
使用tf.FixedLengthRecordReader去读取,我们将其保存到TFRecords文件当中,以这种文件格式保存当作模型训练数据的来源
在这里我们设计一个CifarRead类去完成。将会初始化每个图片的大小数据
def __init__(self, filelist=None):
# 文件列表
self.filelist = filelist
# 每张图片大小数据初始化
self.height = 32
self.width = 32
self.channel = 3
self.label_bytes = 1
self.image_bytes = self.height * self.width * self.channel
self.bytes = self.image_bytes + self.label_bytes
读取代码:
def read_decode(self):
"""
读取数据并转换成张量
:return: 图片数据,标签值
"""
# 1、构造文件队列
file_queue = tf.train.string_input_producer(self.filelist)
# 2、构造二进制文件的阅读器,解码成张量
reader = tf.FixedLengthRecordReader(self.bytes)
key, value = reader.read(file_queue)
# 解码成张量
image_label = tf.decode_raw(value, tf.uint8)
# 分割标签与数据
label_tensor = tf.cast(tf.slice(image_label, [0], [self.label_bytes]), tf.int32)
image = tf.slice(image_label, [self.label_bytes], [self.image_bytes])
print(image)
# 3、图片数据格式转换
image_tensor = tf.reshape(image, [self.height, self.width, self.channel])
# 4、图片数据批处理,一次从二进制文件中读取多少数据出来
image_batch, label_batch = tf.train.batch([image_tensor, label_tensor], batch_size=5000, num_threads=1, capacity=50000)
return image_batch, label_batch
保存和读取TFRecords文件当中
我们通过两个接口实现
def write_to_tfrecords(self, image_batch, label_batch):
"""
把读取出来的数据进行存储(tfrecords)
:param image_batch: 图片RGB值
:param label_batch: 图片标签
:return:
"""
# 1、构造存储器
writer = tf.python_io.TFRecordWriter(FLAGS.image_dir)
# 2、每张图片进行example协议化,存储
for i in range(5000):
print(i)
# 图片的张量要转换成字符串才能写进去,否则大小格式不对
image = image_batch[i].eval().tostring()
# 标签值
label = int(label_batch[i].eval())
# 构造example协议快,存进去的名字是提供给取的时候使用
example = tf.train.Example(features=tf.train.Features(feature={
"image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])),
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
}))
writer.write(example.SerializeToString())
return None
def read_tfrecords(self):
# 1、构建文件的队列
file_queue = tf.train.string_input_producer([FLAGS.image_dir])
# 2、构建tfrecords文件阅读器
reader = tf.TFRecordReader()
key, value = reader.read(file_queue)
# 3、解析example协议块,返回字典数据,feature["image"],feature["label"]
feature = tf.parse_single_example(value, features={
"image": tf.FixedLenFeature([], tf.string),
"label": tf.FixedLenFeature([], tf.int64)
})
# 4、解码图片数据,标签数据不用
# 图片数据处理
image = tf.decode_raw(feature["image"], tf.uint8)
# 处理一下形状
image_reshape = tf.reshape(image, [self.height, self.width, self.channel])
# 改变数据类型
image_tensor = tf.cast(image_reshape, tf.float32)
# 标签数据处理
label_tensor = tf.cast(feature["label"], tf.int32)
# 批处理图片数据,训练数据每批次读取多少
image_batch, label_batch = tf.train.batch([image_tensor, label_tensor], batch_size=10, num_threads=1, capacity=10)
return image_batch, label_batch
我们将数据读取的代码放入cifar_data.py文件当中,当作我们的原始数据读取,完整代码如下
import tensorflow as tf
import os
"""用于获取Cifar TFRecords数据文件的程序"""
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("image_dir", "./cifar10.tfrecords","数据文件目录")
class CifarRead(object):
def __init__(self, filelist=None):
# 文件列表
self.filelist = filelist
# 每张图片大小数据初始化
self.height = 32
self.width = 32
self.channel = 3
self.label_bytes = 1
self.image_bytes = self.height * self.width * self.channel
self.bytes = self.image_bytes + self.label_bytes
def read_decode(self):
"""
读取数据并转换成张量
:return: 图片数据,标签值
"""
# 1、构造文件队列
file_queue = tf.train.string_input_producer(self.filelist)
# 2、构造二进制文件的阅读器,解码成张量
reader = tf.FixedLengthRecordReader(self.bytes)
key, value = reader.read(file_queue)
# 解码成张量
image_label = tf.decode_raw(value, tf.uint8)
# 分割标签与数据
label_tensor = tf.cast(tf.slice(image_label, [0], [self.label_bytes]), tf.int32)
image = tf.slice(image_label, [self.label_bytes], [self.image_bytes])
print(image)
# 3、图片数据格式转换
image_tensor = tf.reshape(image, [self.height, self.width, self.channel])
# 4、图片数据批处理
image_batch, label_batch = tf.train.batch([image_tensor, label_tensor], batch_size=5000, num_threads=1, capacity=50000)
return image_batch, label_batch
def write_to_tfrecords(self, image_batch, label_batch):
"""
把读取出来的数据进行存储(tfrecords)
:param image_batch: 图片RGB值
:param label_batch: 图片标签
:return:
"""
# 1、构造存储器
writer = tf.python_io.TFRecordWriter(FLAGS.image_dir)
# 2、每张图片进行example协议化,存储
for i in range(5000):
print(i)
# 图片的张量要转换成字符串才能写进去,否则大小格式不对
image = image_batch[i].eval().tostring()
# 标签值
label = int(label_batch[i].eval())
# 构造example协议快,存进去的名字是提供给取的时候使用
example = tf.train.Example(features=tf.train.Features(feature={
"image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])),
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
}))
writer.write(example.SerializeToString())
return None
def read_tfrecords(self):
# 1、构建文件的队列
file_queue = tf.train.string_input_producer([FLAGS.image_dir])
# 2、构建tfrecords文件阅读器
reader = tf.TFRecordReader()
key, value = reader.read(file_queue)
# 3、解析example协议块,返回字典数据,feature["image"],feature["label"]
feature = tf.parse_single_example(value, features={
"image": tf.FixedLenFeature([], tf.string),
"label": tf.FixedLenFeature([], tf.int64)
})
# 4、解码图片数据,标签数据不用
# 图片数据处理
image = tf.decode_raw(feature["image"], tf.uint8)
# 处理一下形状
image_reshape = tf.reshape(image, [self.height, self.width, self.channel])
# 改变数据类型
image_tensor = tf.cast(image_reshape, tf.float32)
# 标签数据处理
label_tensor = tf.cast(feature["label"], tf.int32)
# 批处理图片数据
image_batch, label_batch = tf.train.batch([image_tensor, label_tensor], batch_size=10, num_threads=1, capacity=10)
return image_batch, label_batch
if __name__ == "__main__":
# 生成文件名列表(路径+文件名)
filename = os.listdir("./cifar10/cifar-10-batches-bin")
filelist = [os.path.join("./cifar10/cifar-10-batches-bin", file) for file in filename if file[-3:] == "bin"]
# 实例化
cfr = CifarRead(filelist)
# 生成张量
image_batch, label_batch = cfr.read_decode()
# image_batch, label_batch = cfr.read_tfrecords()
# 会话
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord, start=True)
print(sess.run([image_batch, label_batch]))
# 写进tfrecords文件
cfr.write_to_tfrecords(image_batch, label_batch)
coord.request_stop()
coord.join(threads)
模型接口建立
模型接口的建立
我们将模型接口都放在cifar_omdel.py文件当中,设计了四个函数,input()作为从cifar_data文件中数据的获取,inference()作为神经网络模型的建立,total_loss()计算模型的损失,train()来通过梯度下降训练减少损失
input代码
def input():
"""
获取输入数据
:return: image,label
"""
# 实例化
cfr = cifar_data.CifarRead()
# 生成张量
image_batch, lab_batch = cfr.read_tfrecords()
# 将目标值转换为one-hot编码格式
label = tf.one_hot(label_batch, depth=10, on_value=1.0)
return image_batch, label, label_batch
inference代码
在这里使用的卷积神经网络模型与前面一致,需要修改图像的通道数以及经过两次卷积池化变换后的图像大小。
def inference(image_batch):
"""
得到模型的输出
:return: 预测概率输出以及占位符
"""
# 1、数据占位符建立
with tf.variable_scope("data"):
# 样本标签值
# y_label = tf.placeholder(tf.float32, [None, 10])
# 样本特征值
# x = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT * IMAGE_WIDTH * IMAGE_DEPTH])
# 改变形状,以提供给卷积层使用
x_image = tf.reshape(image_batch, [-1, 32, 32, 3])
# 2、卷积池化第一层
with tf.variable_scope("conv1"):
# 构建权重, 5*5, 3个输入通道,32个输出通道
w_conv1 = weight_variable([5, 5, 3, 32])
# 构建偏置, 个数位输出通道数
b_conv1 = bias_variable([32])
# 进行卷积,激活,指定滑动窗口,填充类型
y_relu1 = tf.nn.relu(tf.nn.conv2d(x_image, w_conv1, strides=[1, 1, 1, 1], padding="SAME") + b_conv1)
y_conv1 = tf.nn.max_pool(y_relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 3、卷积池化第二层
with tf.variable_scope("conv_pool2"):
# 构建权重, 5*5, 一个输入通道,32个输出通道
w_conv2 = weight_variable([5, 5, 32, 64])
# 构建偏置, 个数位输出通道数
b_conv2 = bias_variable([64])
# 进行卷积,激活,指定滑动窗口,填充类型
y_relu2 = tf.nn.relu(tf.nn.conv2d(y_conv1, w_conv2, strides=[1, 1, 1, 1], padding="SAME") + b_conv2)
y_conv2 = tf.nn.max_pool(y_relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 4、全连接第一层
with tf.variable_scope("FC1"):
# 构建权重,[7*7*64, 1024],根据前面的卷积池化后一步步计算的大小变换是32->16->8
w_fc1 = weight_variable([8 * 8 * 64, 1024])
# 构建偏置,个数位第一次全连接层输出个数
b_fc1 = bias_variable([1024])
y_reshape = tf.reshape(y_conv2, [-1, 8 * 8 * 64])
# 全连接结果激活
y_fc1 = tf.nn.relu(tf.matmul(y_reshape, w_fc1) + b_fc1)
# 5、全连接第二层
with tf.variable_scope("FC2"):
# droupout层
droup = tf.nn.dropout(y_fc1, 1.0)
# 构建权重,[1024, 10]
w_fc2 = weight_variable([1024, 10])
# 构建偏置 [10]
b_fc2 = bias_variable([10])
# 最后的全连接层
y_logit = tf.matmul(droup, w_fc2) + b_fc2
return y_logit
total_loss代码
def total_loss(y_label, y_logit):
"""
计算训练损失
:param y_label: 目标值
:param y_logit: 计算值
:return: 损失
"""
with tf.variable_scope("loss"):
# softmax回归,以及计算交叉损失熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y_logit)
# 计算损失平均值
loss = tf.reduce_mean(cross_entropy)
return loss
train代码
def train(loss, y_label, y_logit, global_step):
"""
训练数据得出准确率
:param loss: 损失大小
:return:
"""
with tf.variable_scope("train"):
# 让学习率根据步伐,自动变换学习率,指定了每10步衰减基数为0.99,0.001为初始的学习率
lr = tf.train.exponential_decay(0.001,
global_step,
10,
0.99,
staircase=True)
# 优化器
train_op = tf.train.GradientDescentOptimizer(lr).minimize(loss, global_step=global_step)
# 计算准确率
equal_list = tf.equal(tf.argmax(y_logit, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
return train_op, accuracy
完整代码
import tensorflow as tf
import os
import cifar_data
#
#
from tensorflow.examples.tutorials.mnist import input_data
IMAGE_HEIGHT = 32
IMAGE_WIDTH = 32
IMAGE_DEPTH = 3
# 按照指定形状构建权重变量
def weight_variable(shape):
init = tf.truncated_normal(shape=shape, mean=0.0, stddev=1.0, dtype=tf.float32)
weight = tf.Variable(init)
return weight
# 按照制定形状构建偏置变量
def bias_variable(shape):
bias = tf.constant([1.0], shape=shape)
return tf.Variable(bias)
def inference(image_batch):
"""
得到模型的输出
:return: 预测概率输出以及占位符
"""
# 1、数据占位符建立
with tf.variable_scope("data"):
# 样本标签值
# y_label = tf.placeholder(tf.float32, [None, 10])
# 样本特征值
# x = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT * IMAGE_WIDTH * IMAGE_DEPTH])
# 改变形状,以提供给卷积层使用
x_image = tf.reshape(image_batch, [-1, 32, 32, 3])
# 2、卷积池化第一层
with tf.variable_scope("conv1"):
# 构建权重, 5*5, 3个输入通道,32个输出通道
w_conv1 = weight_variable([5, 5, 3, 32])
# 构建偏置, 个数位输出通道数
b_conv1 = bias_variable([32])
# 进行卷积,激活,指定滑动窗口,填充类型
y_relu1 = tf.nn.relu(tf.nn.conv2d(x_image, w_conv1, strides=[1, 1, 1, 1], padding="SAME") + b_conv1)
y_conv1 = tf.nn.max_pool(y_relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 3、卷积池化第二层
with tf.variable_scope("conv_pool2"):
# 构建权重, 5*5, 一个输入通道,32个输出通道
w_conv2 = weight_variable([5, 5, 32, 64])
# 构建偏置, 个数位输出通道数
b_conv2 = bias_variable([64])
# 进行卷积,激活,指定滑动窗口,填充类型
y_relu2 = tf.nn.relu(tf.nn.conv2d(y_conv1, w_conv2, strides=[1, 1, 1, 1], padding="SAME") + b_conv2)
y_conv2 = tf.nn.max_pool(y_relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 4、全连接第一层
with tf.variable_scope("FC1"):
# 构建权重,[7*7*64, 1024],根据前面的卷积池化后一步步计算的大小变换是32->16->8
w_fc1 = weight_variable([8 * 8 * 64, 1024])
# 构建偏置,个数位第一次全连接层输出个数
b_fc1 = bias_variable([1024])
y_reshape = tf.reshape(y_conv2, [-1, 8 * 8 * 64])
# 全连接结果激活
y_fc1 = tf.nn.relu(tf.matmul(y_reshape, w_fc1) + b_fc1)
# 5、全连接第二层
with tf.variable_scope("FC2"):
# droupout层
droup = tf.nn.dropout(y_fc1, 1.0)
# 构建权重,[1024, 10]
w_fc2 = weight_variable([1024, 10])
# 构建偏置 [10]
b_fc2 = bias_variable([10])
# 最后的全连接层
y_logit = tf.matmul(droup, w_fc2) + b_fc2
return y_logit
def total_loss(y_label, y_logit):
"""
计算训练损失
:param y_label: 目标值
:param y_logit: 计算值
:return: 损失
"""
with tf.variable_scope("loss"):
# 将y_label转换为one-hot编码形式
# y_onehot = tf.one_hot(y_label, depth=10, on_value=1.0)
# softmax回归,以及计算交叉损失熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y_logit)
# 计算损失平均值
loss = tf.reduce_mean(cross_entropy)
return loss
def train(loss, y_label, y_logit, global_step):
"""
训练数据得出准确率
:param loss: 损失大小
:return:
"""
with tf.variable_scope("train"):
# 让学习率根据步伐,自动变换学习率,指定了每10步衰减基数为0.99,0.001为初始的学习率
lr = tf.train.exponential_decay(0.001,
global_step,
10,
0.99,
staircase=True)
# 优化器
train_op = tf.train.GradientDescentOptimizer(lr).minimize(loss, global_step=global_step)
# 计算准确率
equal_list = tf.equal(tf.argmax(y_logit, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
return train_op, accuracy
def input():
"""
获取输入数据
:return: image,label
"""
# 实例化
cfr = cifar_data.CifarRead()
# 生成张量
image_batch, lab_batch = cfr.read_tfrecords()
# 将目标值转换为one-hot编码格式
label = tf.one_hot(label_batch, depth=10, on_value=1.0)
return image_batch, label, label_batch
训练以及高级会话函数
主训练逻辑
我们将在cifar_train.py文件实现主要训练逻辑。在这里我们将使用一个新的会话函数,叫tf.train.MonitoredTrainingSession
优点: 1、它自动的建立events文件、checkpoint文件,以记录重要的信息。 2、可以定义钩子函数,可以自定义每批次的训练信息,训练的限制等等
注意:在这个里面我们需要添加一个全局步数,这个步数是每批次训练的时候进行+1计数,内部使用。
代码如下:
import tensorflow as tf
import cifar_model
import time
from datetime import datetime
def train():
# 在图中进行训练
with tf.Graph().as_default():
# 定义全局步数,必须得使用这个,否则会出现StopCounterHook错误
global_step = tf.contrib.framework.get_or_create_global_step()
# 获取数据
image, label, label_1 = cifar_model.input()
# 通过模型进行类别预测
y_logit = cifar_model.inference(image)
# 计算损失
loss = cifar_model.total_loss(label, y_logit)
# 进行优化器减少损失
train_op, accuracy = cifar_model.train(loss, label, y_logit, global_step)
# 通过钩子定义模型输出
class _LoggerHook(tf.train.SessionRunHook):
"""Logs loss and runtime."""
def begin(self):
self._step = -1
self._start_time = time.time()
def before_run(self, run_context):
self._step += 1
return tf.train.SessionRunArgs(loss, float(accuracy.eval())) # Asks for loss value.
def after_run(self, run_context, run_values):
if self._step % 10 == 0:
current_time = time.time()
duration = current_time - self._start_time
self._start_time = current_time
loss_value = run_values.results
examples_per_sec = 10 * 10 / duration
sec_per_batch = float(duration / 10)
format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
'sec/batch)')
print(format_str % (datetime.now(), self._step, loss_value,
examples_per_sec, sec_per_batch))
with tf.train.MonitoredTrainingSession(
checkpoint_dir="./cifartrain/train",
hooks=[tf.train.StopAtStepHook(last_step=500),# 定义执行的训练轮数也就是max_step,超过了就会报错
tf.train.NanTensorHook(loss),
_LoggerHook()],
config=tf.ConfigProto(
log_device_placement=False)) as mon_sess:
while not mon_sess.should_stop():
mon_sess.run(train_op)
def main(argv):
train()
if __name__ == "__main__":
tf.app.run()
分布式Tensorflow
Tensorflow的一个特色就是分布式计算。分布式Tensorflow是由高性能的gRPC框架作为底层技术来支持的。这是一个通信框架gRPC(google remote procedure call),是一个高性能、跨平台的RPC框架。RPC协议,即远程过程调用协议,是指通过网络从远程计算机程序上请求服务。
分布式原理
Tensorflow分布式是由多个服务器进程和客户端进程组成。有几种部署方式,列如单机多卡和多机多卡(分布式)。
单机多卡
单机多卡是指单台服务器有多块GPU设备。假设一台机器上有4块GPU,单机多GPU的训练过程如下:
-
在单机单GPU的训练中,数据是一个batch一个batch的训练。 在单机多GPU中,数据一次处理4个batch(假设是4个GPU训练), 每个GPU处理一个batch的数据计算。
-
变量,或者说参数,保存在CPU上。数据由CPU分发给4个GPU,在GPU上完成计算,得到每个批次要更新的梯度
-
在CPU上收集完4个GPU上要更新的梯度,计算一下平均梯度,然后更新。
-
循环进行上面步骤
多机多卡(分布式)
而分布式是指有多台计算机,充分使用多台计算机的性能,处理数据的能力。可以根据不同计算机划分不同的工作节点。当数据量或者计算量达到超过一台计算机处理能力的上上限的话,必须使用分布式
分布式的架构
当我们知道的基本的分布式原理之后,我们来看看分布式的架构的组成。分布式架构的组成可以说是一个集群的组成方式。那么一般我们在进行Tensorflow分布式时,需要建立一个集群。通常是我们分布式的作业集合。一个作业中又包含了很多的任务(工作结点),每个任务由一个工作进程来执行。
节点之间的关系
一般来说,在分布式机器学习框架中,我们会把作业分成参数作业(parameter job)和工作结点作业(worker job)。运行参数作业的服务器我们称之为参数服务器(parameter server,PS),负责管理参数的存储和更新,工作结点作业负责主要从事计算的任务,如运行操作。
参数服务器,当模型越来越大时,模型的参数越来越多,多到一台机器的性能不够完成对模型参数的更新的时候,就需要把参数分开放到不同的机器去存储和更新。参数服务器可以是由多台机器组成的集群。工作节点是进行模型的计算的。Tensorflow的分布式实现了作业间的数据传输,也就是参数作业到工作结点作业的前向传播,以及工作节点到参数作业的反向传播。
分布式的模式
在训练一个模型的过程中,有哪些部分可以分开,放在不同的机器上运行呢?在这里就要接触到数据并行的概念。
数据并行
数据并总的原理很简单。其中CPU主要负责梯度平均和参数更新,而GPU主要负责训练模型副本。
- 模型副本定义在GPU上
- 对于每一个GPU,都是从CPU获得数据,前向传播进行计算,得到损失,并计算出梯度
- CPU接到GPU的梯度,取平均值,然后进行梯度更新
每一个设备的计算速度不一样,有的快有的满,那么CPU在更新变量的时候,是应该等待每一个设备的一个batch进行完成,然后求和取平均来更新呢?还是让一部分先计算完的就先更新,后计算完的将前面的覆盖呢?这就由同步更新和异步更新的问题。
同步更新和异步更新
更新参数分为同步和异步两种方式,即异步随机梯度下降法(Async-SGD)和同步随机梯度下降法(Sync-SGD)
-
同步随即梯度下降法的含义是在进行训练时,每个节点的工作任务需要读入共享参数,执行并行的梯度计算,同步需要等待所有工作节点把局部的梯度算好,然后将所有共享参数进行合并、累加,再一次性更新到模型的参数;下一个批次中,所有工作节点拿到模型更新后的参数再进行训练。这种方案的优势是,每个训练批次都考虑了所有工作节点的训练情况,损失下降比较稳定;劣势是,性能瓶颈在于最慢的工作结点上。
-
异步随机梯度下降法的含义是每个工作结点上的任务独立计算局部梯度,并异步更新到模型的参数中,不需要执行协调和等待操作。这种方案的优势是,性能不存在瓶颈;劣势是,每个工作节点计算的梯度值发送回参数服务器会有参数更新的冲突,一定程度上会影响算法的收敛速度,在损失下降的过程中抖动较大。
分布式接口
创建集群的方法是为每一个任务启动一个服务,这些任务可以分布在不同的机器上,也可以同一台机器上启动多个任务,使用不同的GPU等来运行。每个任务都会创建完成一下工作
-
1、创建一个tf.train.ClusterSpec,用于对集群中的所有任务进行描述,该描述内容对所有任务应该是相同的
-
2、创建一个tf.train.Server,用于创建一个任务,并运行相应作业上的计算任务。
Tensorflow的分布式API使用如下:
- tf.train.ClusterSpec()
创建ClusterSpec,表示参与分布式TensorFlow计算的一组进程
cluster = tf.train.ClusterSpec({"worker": ["worker0.example.com:2222", /job:worker/task:0
"worker1.example.com:2222", /job:worker/task:1
"worker2.example.com:2222"], /job:worker/task:2
"ps": ["ps0.example.com:2222", /job:ps/task:0
"ps1.example.com:2222"]}) /job:ps/task:1
创建Tensorflow的集群描述信息,其中ps和worker为作业名称,通过指定ip地址加端口创建,
- tf.train.Server(server_or_cluster_def, job_name=None, task_index=None, protocol=None, config=None, start=True)
- server_or_cluster_def: 集群描述
- job_name: 任务类型名称
- task_index: 任务数
创建一个服务(主节点或者工作节点服务),用于运行相应作业上的计算任务,运行的任务在task_index指定的机器上启动,例如在不同的ip+端口上启动两个工作任务
# 第一个任务
cluster = tf.train.ClusterSpec({"worker": ["localhost:2222","localhost:2223"]})
server = tf.train.Server(cluster, job_name="worker", task_index=0)
# 第二个任务
cluster = tf.train.ClusterSpec({"worker": ["localhost:2222","localhost:2223"]})
server = tf.train.Server(cluster, job_name="worker", task_index=1)
- 属性:target
- 返回tf.Session连接到此服务器的目标
- 方法:join()
- 参数服务器端等待接受参数任务,直到服务器关闭
- tf.device(device_name_or_function)
工作人任务端的代码在指定的设备上执行张量运算,指定代码运行在CPU或者GPU上
with tf.device("/job:ps/task:0"):
weights = tf.Variable(...)