手机对话中的语音处理(一)
本系列文章由 @YhL_Leo 出品,转载请注明出处。
文章链接: http://blog.csdn.net/yhl_leo/article/details/50311869
尽管大多数人认为手机是传统有线电话服务的延伸,事实上,手机技术是极其复杂而且堪称神奇的技术。很少有人意识到这些小型设备为了维持一个电话谈话需要每秒执行数百万次的计算,如果我们细看将语音电子信号转换为比特序列的模块,就会发现每20毫秒的输入语音就会被计算出一组语音参数然后传输到接收端,之后接收端再将这组参数转换为语音。本文将介绍手机语音传输中的核心——线性预测分析合成技术 (linear predictive (LP) analysis-synthesis)。

世界首款商用移动手机 Motorola DynaTAC 8000x
1 语音的线性预测处理背景
语音是由我们喉咙产生的一种激励信号,通过声带、鼻、咽部等共振调整出每个人所具有的不同的形式。这种激励信号,可以通过我们周期性地开启和关闭声带产生(例如语音中的元音),也可以仅仅是一些肺部推动的连续气流(例如语音中末尾的语气音),或者是两种结合在一起的方式等。
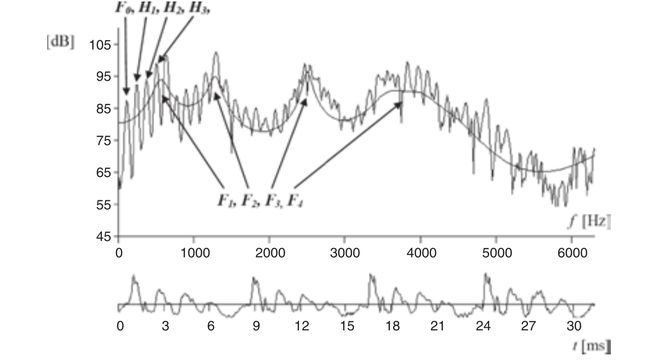
图 1 一段30毫秒的声音信号
如图 1所示,一段30毫秒的声音信号(底部)和它对应的波谱(这里显示的是其FFT的大小)。其中 F0 是基频,我们可以称之为音高(Pitch)(严格来讲,音高是指感知到的基频)。谐波或者谐频(Harmonics)是指像 H1,H2,H3 等峰值处对应的频率声波。共振峰(Formants)是指像 F1,F2,F3 等出现在频谱包络宽峰处。
1.1 语音的线性预测处理模型
早在1960年,Fant就提出一种语音的线性处理模型,称之为source-filter模型。它基于这样的假设:声门和声道是完全分离的。这个模型最终由Rabiner and Shafer(1978)发展成为有名的线性预测模型(linear predictive,LP)或者称为自我回归模型(autoregressive,AR),后来又被逐渐被广泛应用在语音编码中,所以也被称为语音线性预测编码模型(linear predictive coding,LPC):
其中, S~(z) 和 E~(z) 是Z-变换后的语音信号和激励信号(Z-变换,将时域信号(即:离散时间序列)变换为在复频域的表达式), p 是prediction order。整个过程如图 2所示:
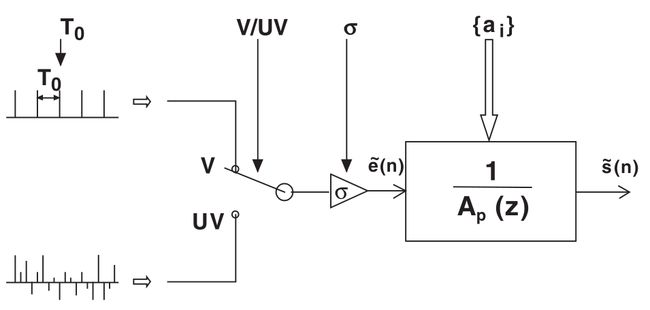
图 2 语音生成的LP模型
在这一模型中,LP模型的激励被认为是一串定期间隔的脉冲(其周期 T0 和振幅 σ 都是可调的)和高斯白噪声(方差 σ2 可调)中的一种,因此图中V/UV装置的含义就是决策信号是有声(voiced)或无声(unvoiced),滤波函数 1Ap(z) 是合成滤波器(synthesis filter)而 Ap(z) 称之为逆滤波器(inverse filter)。
公式 (1) 隐式地引入了语音线性预测的概念,即每个语音采样信号都可以被表示为其之前的 p 个采样信号的加权之和加上一些激励项:
1.2 LP估值算法
给定一个固定的短暂语音信号,实际处理中的常常遇到的问题是如何获得一组最佳的预测系数,使得模型的误差最小化,即使原始信号和经过图 2过程处理后的信号之间可以听出的差异最小化。因此,需要估算的LP模型参数:Pitch周期 T0 ,增益 σ ,V/UV决策和预测系数 {ai} 。
Pitch和V/UV决策是比较难的问题,虽然语音虽然看起来像是周期性的,但是真实的情况绝不是这样的。声门的周期振幅在不同周期间具有差异性,而周期内也不是常数。而且显示出的语音波形仅仅是经过过滤的声门脉冲(如采样)而不是原始脉冲本身,这就使得实际测量 T0 变得非常复杂。除此以外,语音很少有完全是有声的,这就增加了噪声分量,从而使确定Pitch变得困难。
值得庆幸的是,估算 σ 和预测系数 {ai} 与估算 T0 是相互独立的,给定一个语音信号 s(n) ,利用预测系数 {ai} 可以计算出预测信号与原始信号的残差值:
由此,我们可以得到公式 (2) 和图 2所示的语音处理的逆滤波过程,如图 3所示。
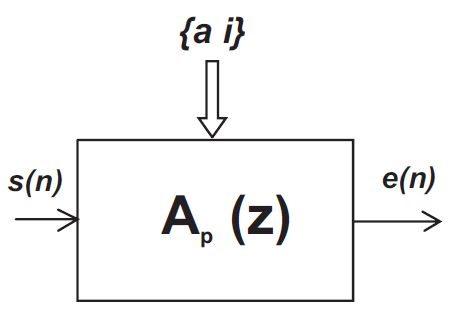
图 2 语音逆滤波过程
而LP估值算法的核心思想就是,选择一组最优的 {a1,a2,…ap} ,使得期望值 E(e2(n)) 的值最小(称之为最小均方误差准则):
事实上,一组固定的语音信号 s(n) ,由LP模型合成的语音 s~(n) ,见公式 (2) ,具有与原始信号 s(n) 相同的频谱包络。因此,LP模型中的激励信号(如脉冲或者白噪声)具有较平的频谱包络,相应的合成语音将会与原始信号具有近似匹配的频谱包络,同时LP残差也具有近似较平的频谱包络。
根据公式 (4) 的最小均方误差准则,可以推导出 p Yule-Walker 线性方程:
在上述方程中, ϕxx(k),(k=0,1,…,p) 是语音信号 s(n) 的 p+1 个一阶自相关系数,解决这一线性方程后,振幅 σ 的值可以通过公式 (6) 计算:
需要注意的是,可以看出公式 (5) 只是基于信号 s(n) 的自相关函数,LP模型的本意只是获得原语音信号的频谱包络特征,而不是最大程度模仿整个语音波型。
1.3 LP处理的实际应用
如果语音是非固定的(比如一系列连续的对话,对整体直接分析,基本不可能),LP模型一般被依次作用在每个语音帧上(类似于视频的图像帧,这里由于语音信号是离散的数字序列,一般的做法是每次取出30毫秒的语音作为一个信号帧,帧和帧之间有20毫秒的重叠,很像图像处理中的滑动窗口,见图 3),由于时间间隔很短,假设发音的肌肉具有惯性,相邻语音帧之间是相互关联的,而且每个语音帧都可以适用1.2小节中所假设的固定语音信号的处理方法。
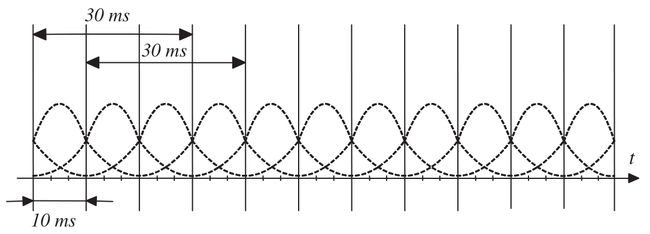
图 3 语音帧和采样示意图
语音采样通常使用加权窗(典型的方法如30毫秒长的Hamming 窗,见图 4)。这样可以抑制每个语音帧的前 13 部分的信号按照公式 (4) 计算时,因为权值过大从而导致 e2(n) 的值较大。
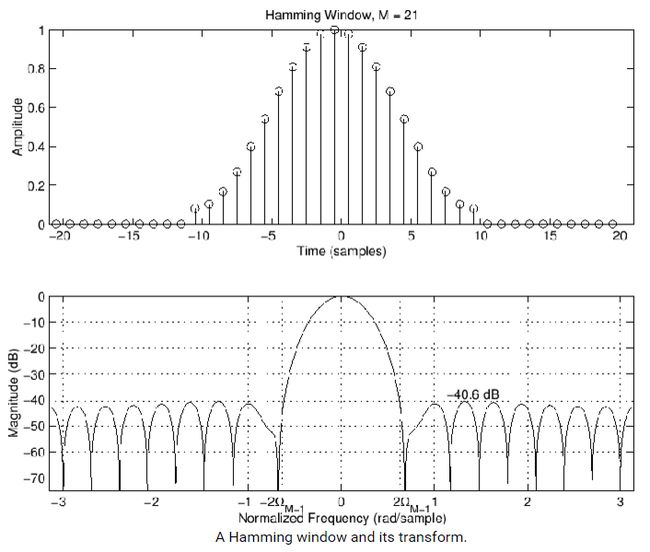
图 4 Hamming 窗及其DTFT变换
至于自相关系数 ϕxx(k)(k=0,…,p) ,是通过有限数量的信号采样(通常对于30毫秒的语音,等间隔产生240个采样值,也就是说采样的频率是8 kHz = 240/(30∗10−3)Hz )。 p 取值选择主要基于合成滤波器能够具有足够的自由度,可以较好的复制原始输入语音信号的频谱包络。在手机应用中,通常采样频率定为8 kHz , p=10 。
关于方程 (5) 的解法,经典的矩阵求逆方法就可以求解,但是Levinson-Durbin 方法求解更为快速和有效,Matlab中已有封装好的可执行函数levinson,详情可见Levinson-Durbin recursion。根据上面的解算,对于每一语音帧,都可以解算出其对应的预测系数 {ai} 。
因此,完整的LPC语音分析-合成算法系统,可以表示为图 5:
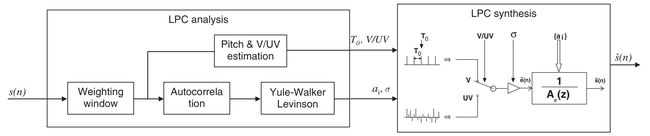
图 5 LPC语音分析-合成示意图