SSD(Single Shot MultiBoxDetector)目标检测

借鉴YOLO:直接回归bbox和分类概率;
借鉴Faster R-CNN:使用anchor提升识别准确度;
借鉴FPN:加入金字塔的检测方式;
结合两者优点,提高速度上超过YOLO,精度上与Faster R-CNN媲美;
网络结构
base network
采用VGG19提取卷积特征,在后面添加一系列卷积层,进行多尺度检测,低层特征保留图像的细节信息,用于检测较小的目标,高层特征用于检测较大的目标。如下图所示:
在base network基础上添加辅助结构:
1. 多尺度预测:在base network后,添加一些卷积层,这些层的大小逐渐减小,可以进行多尺度预测
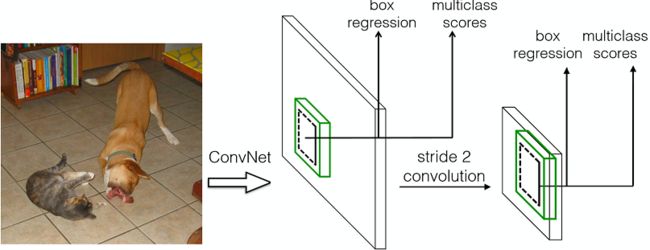
2. 在特征图上预测: 在特征图的每个位置预测K个box。对于每个box,预测C个类别得分,以及相对于default bounding box的4个偏移值,这样需要(C+4)*k个预测器,在m*n的特征图上将产生(C+4)*k*m*n个预测值。这里,default bounding box类似于FasterRCNN中anchors。
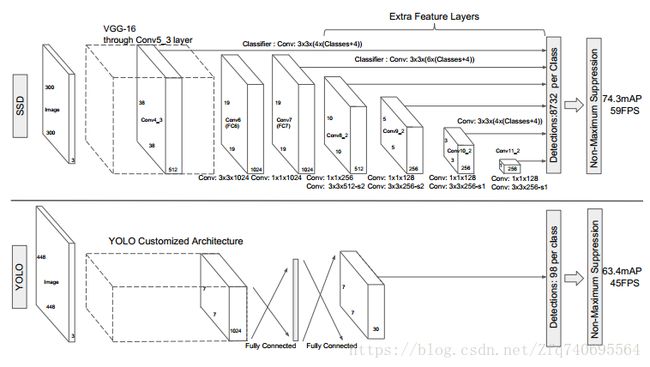

而SSD采用了特征金字塔结构进行检测,即检测时利用了conv4-3,conv-7(FC7),conv6-2,conv7-2,conv8_2,conv9_2这些大小不同的feature maps,在多个feature maps上同时进行softmax分类和位置回归。

SSD在不同的特征层中考虑不同的尺度,RPN在一个特征层考虑不同的尺度。
anchor box
作为一些目标的候选框,后续通过softmax分类+bounding box regression获得真实目标的位置。
生成规则:以feature map上每个点的中点为中心(offset=0.5),生成一些列同心的prior box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)
长宽规则
正方形:最小正方形:min_size,最大正方形边长:![]()
长方形:对于每个aspect ratio,生成2个长方形,长宽分别为![]() 和
和![]()

确定min_size和max_size

其中:m是使用feature map的数量;
第一层feature map对应的min_size=S1,max_size=S2;第二层min_size=S2,max_size=S3;其他类推。在原文中,Smin=0.2,Smax=0.9。
采用不同的aspect ratios:{1,2,3,1/2,1/3}
使用anchor box检测

在conv4_3 feature map网络pipeline分为了3条线路:
1. 经过一次batch norm+一次卷积后,生成了[1, num_class*num_priorbox, layer_height, layer_width]大小的feature用于softmax分类目标和非目标(其中num_class是目标类别,SSD 300中num_class = 21)。
2. 经过一次batch norm+一次卷积后,生成了[1, 4*num_priorbox, layer_height, layer_width]大小的feature用于bounding box regression(即每个点一组[dxmin,dymin,dxmax,dymax]。
3. 生成了[1, 2, 4*num_priorbox]大小的prior box blob,其中2个channel分别存储prior box的4个点坐标和对应的4个variance

还有一个细节就是上面prototxt中的4个variance,这实际上是一种bounding regression中的权重。在图4线路(2)中,网络输出[dxmin,dymin,dxmax,dymax],即对应下面代码中bbox;
decode_bbox->set_xmin(
prior_bbox.xmin() + prior_variance[0] * bbox.xmin() * prior_width);
decode_bbox->set_ymin(
prior_bbox.ymin() + prior_variance[1] * bbox.ymin() * prior_height);
decode_bbox->set_xmax(
prior_bbox.xmax() + prior_variance[2] * bbox.xmax() * prior_width);
decode_bbox->set_ymax(
prior_bbox.ymax() + prior_variance[3] * bbox.ymax() * prior_height); 计算所有特征输出
综合6个featuremap的结果:使用Permute,Flatten和Concat层进行计算,计算方式如下:交换维度->展开->连接
Permute
作用:交换数据维度
bottom blob = [batch_num, channel, height, width]
top blob = [batch_num, height, width, channel]
Flatten
作用:将四维展开成两维;
bottom blob = [batch_num, height, width, channel]
top blob = [batch_num, height*width*channel]
Concat
作用:拼接
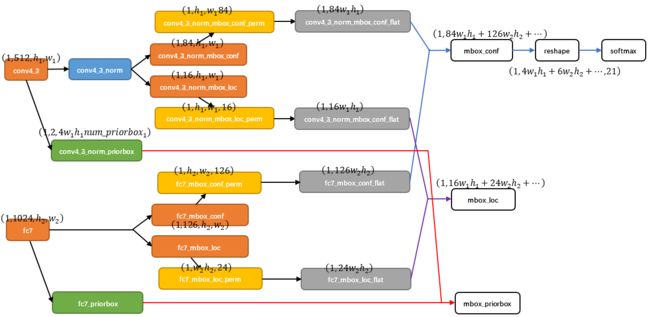
以conv4_3和fc7为例:
- 对于conv4_3 feature map,conv4_3_norm_priorbox(priorbox层)设置了每个点共有4个prior box。由于SSD 300共有21个分类,所以conv4_3_norm_mbox_conf的channel值为num_priorbox * num_class = 4 * 21 = 84;而每个prior box都要回归出4个位置变换量,所以conv4_3_norm_mbox_loc的caffe blob channel值为4 * 4 = 16。
- fc7每个点有6个prior box,其他feature map同理。
- 经过一系列图7展示的caffe blob shape变化后,最后拼接成mbox_conf和mbox_loc。而mbox_conf后接reshape,再进行softmax(为何在softmax前进行reshape,Faster RCNN有提及)。
- 最后这些值输出detection_out_layer,获得检测结果。
训练
- 损失函数
总损失函数:loc(位置损失)+conf(置信度损失)
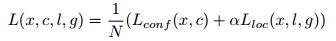
loc损失函数:

其实就是计算GTbox和prebox相对于anchor的坐标值,相当于归一化,分别对坐标值对应相减后求smoothL1损失。
smoothl1 s m o o t h l 1 :
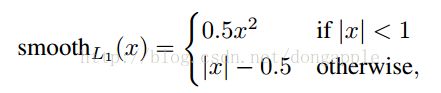
置信度损失:

SSD对小目标检测效果不好,在mAP高于YOLO和Faster RCNN,速度低于YOLO,如下图所示:

- GT和anchor匹配策略:
将每个groundtruth box与具有最大jaccard overlap的defalult box进行匹配, 这样保证每个groundtruth都有对应的default box;并且,将每个defalut box与任意ground truth配对,只要两者的jaccard overlap大于某一阈值,本文取0.5,这样的话,一个groundtruth box可能对应多个default box。
- Hard negative mining
值得注意的是,一般情况下negative default boxes数量>>positive default boxes数量,直接训练会导致网络过于重视负样本,从而loss不稳定。所以需要采取:所以SSD在训练时会依据confidience score排序default box,挑选其中confidience高的box进行训练,控制positive:negative=1:3
- Hard negative mining
- Data augmentation
进数据增广,即每一张训练图像,随机的进行如下几种选择:
使用原始的图像
采样一个 patch,与物体之间最小的 jaccard overlap 为:0.1,0.3,0.5,0.7 或 0.9
随机的采样一个 patch
采样的 patch 是原始图像大小比例是[0.1,1],aspect ratio在1/2与2之间。当 groundtruth box 的 中心(center)在采样的patch中时,保留重叠部分。在这些采样步骤之后,每一个采样的patch被resize到固定的大小,并且以0.5的概率随机的 水平翻转(horizontally flipped)。
- GT和anchor匹配策略:
优缺点
优点:运行速度可以和YOLO媲美,检测精度可以和Faster RCNN媲美。
缺点:
1. 需要人工设置prior box的参数(min_size,max_size和aspect_ratio)。网络中prior
box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的prior
box大小和形状恰好都不一样,导致调试过程非常依赖经验。
2. 对小目标的recall一般。虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。作者认为,这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
参考资料
CNN目标检测(三):SSD详解