Kaggle项目Digit Recognizer实现(一):三层卷积神经网络
寒假期间学习了斯坦福大学CS231n课程卷积神经网络及以前的内容,并完成了assignment1,assignment2。课程后续内容还在学习中,为了避免遗忘过快,所以尝试着找些相关项目来练手保持热度。第一个项目选择了kaggle中的digit recognizer,即手写数字识别
卷积神经网络介绍
本节主要介绍卷积神经网络的特点和结构
相比于全连接神经网络,卷积神经网络具有许多优越之处。如:
1.它的权值共享以及局部连接的特点,使之更加类似生物神经网络
2.CNN的权值共享和局部连接的特点,使得需要训练的参数锐减
3.CNN具有强大的特征提取能力,而全连接神经网络基本没有特征提取的能力
卷积神经网络结构主要包括卷积层,池化层和全连接层
卷积层
卷积层,即特征提取层,是卷积神经网络最重要的部分。卷积层需要训练的参数是一系列的过滤器,这些过滤器的大小一致,通常都是正方形。
池化层
卷积层的下一层是池化层,卷积层的输出会经过激活函数(如ReLU)激活后,进入池化层。池化层的作用是将卷积层输出的维数进一步降低,以此来减少参数的数量和计算量。
全连接层
在最后几层(一般是1~3层)会采用全连接的方式去学习更多的信息。注意,全连接层的最后一层就是输出层;除了最后一层,其它的全连接层都包含激活函数。
卷积神经网络结构
CNN的的常用结构可以表示如下:
INPUT−>[[CONV−>RELU]∗N−>POOL?]∗M−>[FC−>RELU]∗K−>FC(OUTPUT)
其中,”?”是代表池化层是可选的,可有可无;N(一般0~3),K(一般0~2)和M(M>=0)是具体层数
b在本文中我们采用 N=1,M=1,K=1 的三层卷积神经网络结构
Digit Recognizer实现
读入数据
网站中提供的数据包括两个,train.csv和test.csv。其中,train.csv中为训练数据,每个手写数字图片为28*28的灰度值,保存为1*784的行向量,并在第一列添加对应的label值,即train.csv中文件格式为N*785,其中第一行为文件头,可忽略。test.csv中为测试数据,与train.csv文件类似,但此处没有label值,即文件格式为N*784.从csv文件中读入数据的python代码如下:
import numpy as np
import csv
def readCSVFile(file):
rawData = []
csvfile = open(file, 'rb')
reader = csv.reader(csvfile)
for line in reader:
rawData.append(line)
rawData.pop(0)#remove file header
intData = np.array(rawData).astype(np.int32)
csvfile.close()
return intData
def loadTrainingData():
intData = readCSVFile("CNN/readCSV/train.csv")
label = intData[:,0]#label: col 0
data = intData[:,1:]#pixel value: col 1:785
#data = np.where(data>0,[1,0])
return data, label;
def loadTestData():
intData = readCSVFile('CNN/readCSV/test.csv')
#data = np.where(intData>0,[1,0])
return intData
def get_mnist_data():
X_train,y_train = loadTrainingData()
X_test = loadTestData()
num_train = len(y_train)
num_test = np.size(X_test,axis=0)
num_val = num_train/10;
num_train = num_train - num_val
# Subsample the data
mask = range(num_train, num_train + num_val)
X_val = X_train[mask]
y_val = y_train[mask]
mask = range(num_train)
X_train = X_train[mask]
y_train = y_train[mask]
# Normalize the data: subtract the mean image
mean_image = np.mean(X_train, axis=0,keepdims =True).astype(np.int32)
X_train -= mean_image
X_val -= mean_image
X_test -= mean_image
X_train = np.reshape(X_train, (num_train, 1, 28, 28))
X_test = np.reshape(X_test, (num_test, 1, 28, 28))
X_val = np.reshape(X_val, (num_val, 1, 28, 28))
return {
'X_train': X_train, 'y_train': y_train,
'X_val': X_val, 'y_val': y_val,
'X_test': X_test
}get_mnist_data()返回一个字典,分别对应训练数据,交叉验证数据和测试数据,其中交叉验证数据占训练数据的1/10
CNN训练
q参数选择如下,权重初始化weight_scale=0.001; 滤波器大小为32*5*5,步长为1;池化层采样窗口大小2*2,步长为1;隐藏层大小为100;学习率learning_rate=1e-4;
利用cs231n课程assignment2提供的python代码进行训练
data = get_mnist_data()
for k, v in data.iteritems():
print '%s: ' % k, v.shape
model = ThreeLayerConvNet(weight_scale=0.001, hidden_dim=500,reg=0.001)
solver = Solver(model, data,num_epochs=10,batch_size=200,update_rule='adam',
optim_config={'learning_rate':1e-4,},verbose=True, print_every=10)
solver.train()
print 'finished training'并绘制训练过程中loss和准确率曲线
plt.subplot(2, 1, 1)
plt.plot(solver.loss_history, 'o')
plt.xlabel('iteration')
plt.ylabel('loss')
plt.subplot(2, 1, 2)
plt.plot(solver.train_acc_history, '-o')
plt.plot(solver.val_acc_history, '-o')
plt.legend(['train', 'val'], loc='upper left')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()损失和准确率曲线如下
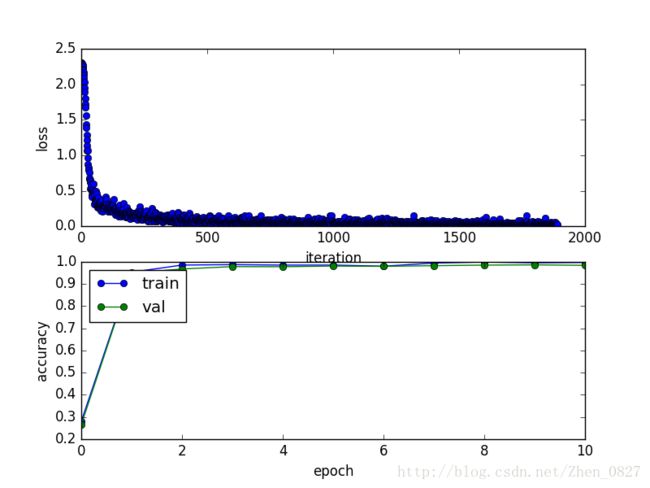
测试并提交结果
利用上一步训练好的模型,对X_test数据进行预测,并讲结果保存到csv文件中
num_test = np.size(data['X_test'],axis = 0)
batch_size = 200
y_test_pred = np.zeros((num_test/batch_size,batch_size))
for i in xrange(num_test/batch_size):
y_test_pred[i] = np.argmax(model.loss(data['X_test'][i*batch_size:(i+1)*batch_size,:,:,:]),axis=1)
label = np.concatenate(([y_test_pred[i] for i in xrange(num_test/batch_size)]))
label = np.array(label).astype(np.int32)
print 'finished testing'
csvfile = file('pred_3laycnn.csv','wb')
writer = csv.writer(csvfile)
row = ('ImageId','Label')
writer.writerow(row)
for i in xrange(num_test):#(len(y_test_pred)):
row = (i+1, label[i])
writer.writerow(row)
csvfile.close()将预测结果文件pred_3laycnn.csv提交到kaggle网站,准确率为98.457%,还算不错。但在网站的排名中已经位于31%,可见选择三层卷积神经网络网络的模型还是太简单了。
下一步准备利用caffe实现更为复杂的模型