windows10下安装spark+scala+intellij
1:先安装intellij
https://www.jetbrains.com/idea/download/#section=windows

下载社区版即可
2:安装java
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
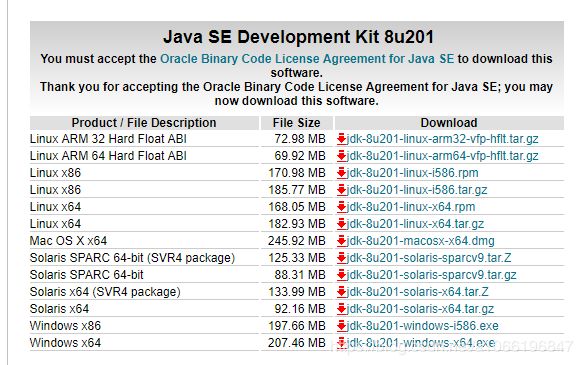
下载截图里面最底下那一个,因为1.8是个稳定的版本,而且是现在的公司主流版本
安装完成后,如果这个时候就在“命令行”下输入java -version,也会出现你刚安装的那个版本,原因是因为你在安装java的时候,默认往环境变量的path下写入了这样一行 C:\Program Files (x86)\Common Files\Oracle\Java\javapath 而这个目录下有java的映射,导致java现在就可以解析了,

在这块搜索:环境变量

会出现
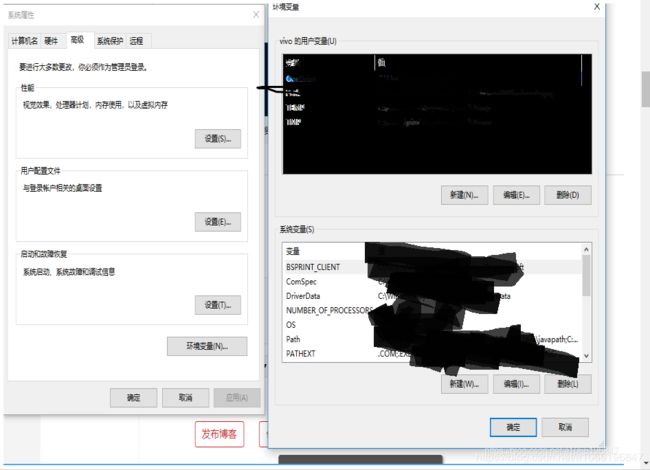
先删掉刚刚那个java相关的path
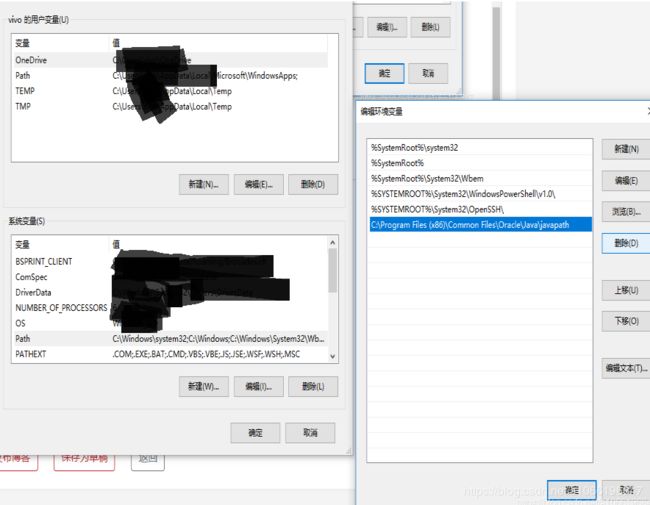
然后重新搭建配置
环境配置:
1:新建JAVA_HOME === E:\Java\jdk1.8.0_201
2:新建CLASSPATH ==== E:\Java\jdk1.8.0_201\lib
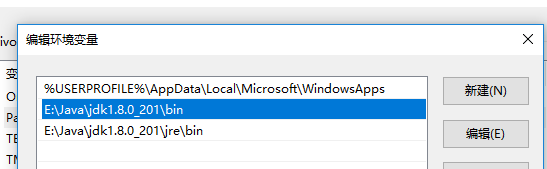
3:添加E:\Java\jdk1.8.0_201\bin; E:\Java\jdk1.8.0_201\jre\bin; 到Path里

3: 安装scala
https://www.scala-lang.org/download/
 -> https://www.scala-lang.org/download/all.html ->
-> https://www.scala-lang.org/download/all.html ->
![]() ->
-> 
现阶段下载的版本是2.11.8,记住这个版本,因为后面下载安装spark的时候 需要保证对应spark版本里面的scala的版本也是2.11.8
安装完后,查看系统变量里面的path。发现已经自动写好路径了

但最好自己检查一下,以免没弄好

3.5: 安装python
https://www.anaconda.com/distribution/ -> ![]()
![]() ->
->
ctrl+F 找到这个进行下载 Anaconda3-4.2.0-Windows-x86_64.exe (这个对应的是python3.5版本的,是为了之后的时候用到Gpu版本的tf,它不支持高版本的python)
安装完成后,anaconda会自动写好环境变量,这一步在安装的时候可以配置
3.6安装git
官网:https://git-scm.com/download/win 现在下载的版本是 2.20.1
添加 E:\Git\bin 到环境变量Path里
3.7:安装hadoop2.7.2,下载之后进行解压,然后再找一些辅助的文件进行补充,就可以正常启动起来
http://hadoop.apache.org/releases.html ->
 ->
->
ctrl+F找到 hadoop-2.7.2/ 这个链接进行下载,下载完成后,解压到 E:\hadoop-2.7.2
然后配置环境变量HADOOP_HOME中,在PATH里加上%HADOOP_HOME%\bin
点击http://download.csdn.net/detail/wuxun1997/9841472下载相关工具类,直接解压后把文件丢到E:\hadoop-2.7.2\bin目录中去,将其中的hadoop.dll在c:/Windows/System32下也丢一份;(这个csdn资源中的数据也可以从这个github里面找到 https://github.com/steveloughran/winutils/tree/master/hadoop-2.7.1/bin 网上找Hadoop 2.7.2的winutils.exe找不到的时候,直接用2.7.1的winutils.exe,照样能用)
之后启动hadoop的时候,具体参考这篇文档:https://www.cnblogs.com/wuxun1997/p/6847950.html
**自己在执行上面这篇文档时候的时候,按理说
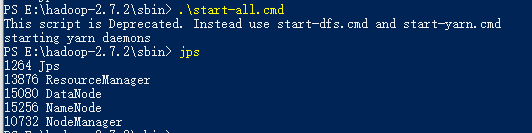
E:\hadoop-2.7.2\bin>hadoop namenode -format 进行格式化后,切换到 E:\hadoop-2.7.2\sbin 这个目录下执行 .\start-all.cmd就可以启动4个窗口,代表4个进程。但是实际上我这边的namenode没有启动起来

很明显是在格式化的时候,只创建了 E:\hadoop\data\dfs\datanode 这个文件夹,而少了同路径下的namenode,,自己手动把这个文件夹创建好后。再重新格式化 hadoop namenode -format ,然后再重启所有进程 .\start-all.cmd,这时候再jps就正常了
4:安装spark,要注意spark的版本号和scala并不一致,而是spark依赖scala
http://spark.apache.org/ 查看Documentation可以查看对应版本问题
Spark runs on Java 8+, Python 2.7+/3.4+ and R 3.1+. For the Scala API, Spark 2.4.0 uses Scala 2.11. You will need to use a compatible Scala version (2.11.x).
可以看到现在最新的版本的spark用的是scala2.11.*,所以刚刚安装scala的就要注意了,别安装太高
http://spark.apache.org/downloads.html
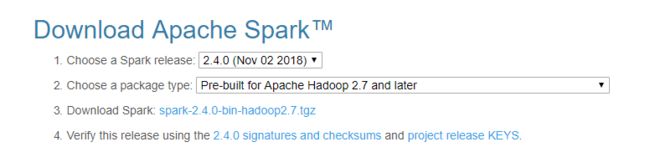
下载后,解压到 E:\spark,然后吧这个路径 E:\Spark\bin添加到系统环境目录下
检验上面的那些东西是否安装配置正确
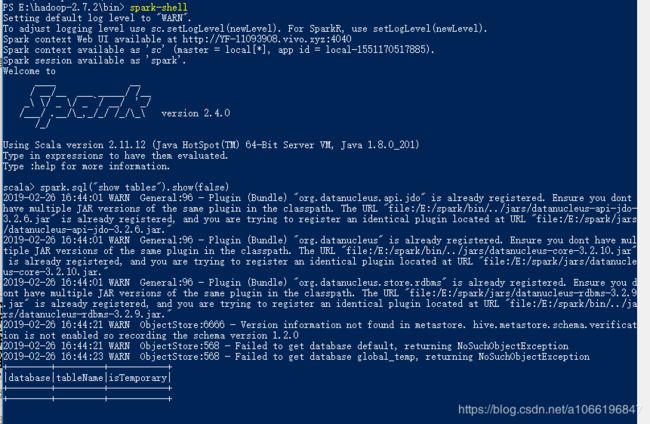
注意是否打印出来这个东西:
Spark context Web UI available at http://YF-11093908.vivo.xyz:4040
Spark context available as 'sc' (master = local[*], app id = local-1551170517885).
Spark session available as 'spark'.
在一些配置文档中还看到有输出:SQL context available as sqlContext. 但是我这个版本却没有输出来
5:之后是使用intellij新建个scala项目,参考这篇文档里面的配置(从*******2、intellij 配置*******开始看)
https://blog.csdn.net/u011464774/article/details/76697183
补充1:创建工程后,会在idea的右下角出现 dump project structure from sbt (虽然上面我们没有下载sbt,但是也会执行成功),因为是从国外的服务器拉取文件,所以大概持续10分钟左右,拉取到的文件默认存储在 c:\用户\{你当前的用户名}\vivo\.sbt ,从里面可以看到很多jar包
补充2:在创建工程时,需要填写sbt的版本,就照这篇blog文档里面来吧
补充3:博主写的这篇文档的整个的安装过程在这篇文档里也是很详细 https://blog.csdn.net/u011513853/article/details/52865076
而且这篇文档阅读量很大
6: 在windows下,还是使用xshell或者securtCRT方便开发些,再下载个这个。
7:如果导入公司/实验室 里面的scala项目,参考这篇文档:https://blog.csdn.net/a1066196847/article/details/87939658