利用python对本地数据进行操作
一、TXT文件操作
1.1 TXT文件介绍
由字符串行组成,每行由EOL (End Of Line) 字符隔开,‘\n’
1.2 查看文件数据
该文本文件是一个关于Python语言的介绍

1.3 打开文件
利用Python内置 open() 方法 ,传入参数,并返回文件对象。
# 这里为相对路径,也可以写为绝对路径
txt_filename = './files/python_wiki.txt'
# 打开文件,设置只读,并且为UTF-8编码格式,会返回一个文件对象
file_obj = open(txt_filename, mode='r', encoding='utf-8')
1.4 读取文件
1.4.1 读取整个文件内容
利用 文件对象.read() 方法来读取整个文件内容,读完以后,一定要记得 关闭文件。
# 读取整个文件内容
all_content = file_obj.read()
# 打印输出
print(all_content)
# 关闭文件
file_obj.close()
Python是一种计算机程序设计语言。是一种动态的、面向对象的脚本语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
Python在设计上坚持了清晰划一的风格,这使得Python成为一门易读、易维护,并且被大量用户所欢迎的、用途广泛的语言。
设计者开发时总的指导思想是,对于一个特定的问题,只要有一种最好的方法来解决就好了。这在由Tim Peters写的Python格言(称为The Zen of Python)里面表述为:There should be one-- and preferably only one --obvious way to do it. 这正好和Perl语言(另一种功能类似的高级动态语言)的中心思想TMTOWTDI(There's More Than One Way To Do It)完全相反。
Python的作者有意的设计限制性很强的语法,使得不好的编程习惯(例如if语句的下一行不向右缩进)都不能通过编译。其中很重要的一项就是Python的缩进规则。
一个和其他大多数语言(如C)的区别就是,一个模块的界限,完全是由每行的首字符在这一行的位置来决定的(而C语言是用一对花括号{}来明确的定出模块的边界的,与字符的位置毫无关系)。这一点曾经引起过争议。因为自从C这类的语言诞生后,语言的语法含义与字符的排列方式分离开来,曾经被认为是一种程序语言的进步。不过不可否认的是,通过强制程序员们缩进(包括if,for和函数定义等所有需要使用模块的地方),Python确实使得程序更加清晰和美观。
1.4.2 逐行读取文件内容
利用 文件对象.readline() 方法来 逐行读取 文件内容,读完之后,要记得 关闭文件。
txt_filename = './files/python_wiki.txt'
# 打开文件
file_obj = open(txt_filename, mode='r', encoding='utf-8')
# 逐行读取
line = file_obj.readline()
print (line)
Python是一种计算机程序设计语言。是一种动态的、面向对象的脚本语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
# 继续读下一行
next_line = file_obj.readline()
print(next_line)
# 关闭文件
file_obj.close()
Python在设计上坚持了清晰划一的风格,这使得Python成为一门易读、易维护,并且被大量用户所欢迎的、用途广泛的语言。
1.4.3 读取全部内容,返回列表
利用 文件对象.readlines() 方法来读取全部内容,并且返回一个 列表 ,要记得 关闭文件。
txt_filename = './files/python_wiki.txt'
# 打开文件
file_obj = open(txt_filename, mode='r', encoding='utf-8')
# 返回列表文件
lines = file_obj.readlines()
# 打印列表
print(lines)
# 关闭文件
file_obj.close()
['Python是一种计算机程序设计语言。是一种动态的、面向对象的脚本语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。\n', 'Python在设计上坚持了清晰划一的风格,这使得Python成为一门易读、易维护,并且被大量用户所欢迎的、用途广泛的语言。\n', "设计者开发时总的指导思想是,对于一个特定的问题,只要有一种最好的方法来解决就好了。这在由Tim Peters写的Python格言(称为The Zen of Python)里面表述为:There should be one-- and preferably only one --obvious way to do it. 这正好和Perl语言(另一种功能类似的高级动态语言)的中心思想TMTOWTDI(There's More Than One Way To Do It)完全相反。\n", 'Python的作者有意的设计限制性很强的语法,使得不好的编程习惯(例如if语句的下一行不向右缩进)都不能通过编译。其中很重要的一项就是Python的缩进规则。\n', '一个和其他大多数语言(如C)的区别就是,一个模块的界限,完全是由每行的首字符在这一行的位置来决定的(而C语言是用一对花括号{}来明确的定出模块的边界的,与字符的位置毫无关系)。这一点曾经引起过争议。因为自从C这类的语言诞生后,语言的语法含义与字符的排列方式分离开来,曾经被认为是一种程序语言的进步。不过不可否认的是,通过强制程序员们缩进(包括if,for和函数定义等所有需要使用模块的地方),Python确实使得程序更加清晰和美观。']
1.5 写入数据
1.5.1 全部写入
利用 文件对象.write() 方法将数据写到 TXT文件 里,要记得 关闭文件。
# 文件路径
txt_filename = './files/test_write1.txt'
# 打开文件,这里传入参数为'w',说明为可写入文件对象。
file_obj = open(txt_filename, mode='w', encoding='utf-8')
# 写入全部内容
file_obj.write("《Python数据分析》,\n我爱Python")
file_obj.close()
写入文件如下:

1.5.2 将字符串列表内容逐行写入文件
利用 文件对象.writelines() 方法写入 TXT 文件,记得要 关闭文件 。
# 写入字符串列表,这里是一个列表推导式
lines = ['这是第{}行\n'.format(i) for i in range(100)]
txt_filename = './files/test_write2.txt'
# 打开文件
file_obj = open(txt_filename, mode='w', encoding='utf-8')
file_obj.writelines(lines)
file_obj.close()
写入的文件如下:

1.6 利用 with open 语句增强代码可读性
在Python中 with open 语句可以很好的解决忘记关闭文件这个问题,例子如下:
txt_filename = './files/test_write1.txt'
with open(txt_filename, 'r', encoding='utf-8') as f_obj:
print(f_obj.read())
《Python数据分析》,
我爱Python
二、JSON文件操作
2.1 JSON文件介绍
JSON文件的全写为:JavaScript Object Notation,它是一种 轻量级 的数据交换格式,用来传输由 属性值 或者 序列性 的值组成的数据对象。数据是键值对,存在两种结构
• 对象(object):由 { } 表示,如 {key1:val1, key2:val2}
• 数组(array):由 [ ] 表示,如 [val1, val2, …, valn]
有时候也会嵌套使用,下面是一个JSON文件:

2.2 读取JSON
2.2.1 查看数据文件
在pycharm中查看一下部分数据

2.2.2 从文件中读取
首先导入模块 json ,然后利用 json.load() 方法读取 json文件。
import json
filename = './files/climate.json'
with open(filename, 'r') as f_obj:
json_data = json.load(f_obj)
# 返回值是dict类型
print(type(json_data))
print(json_data.keys())
dict_keys(['data', 'description'])
# 查看data内容
print(len(json_data['data']))
105
for item in json_data['data']:
print(item['city'])
Amsterdam
Athens
Atlanta GA
Auckland
Austin TX
Bangkok
Barcelona
Beijing
Berlin
Bologna
Boston MA
Boulder CO
Brasilia
Brisbane
Brussels
Budapest
Buenos Aires
Calgary
Canberra
Cape Town
Chiang Mai
Chicago IL
Christchurch
Copenhagen
Dallas TX
Denver CO
Detroit MI
Dubai
Dublin
Granada
Halifax
Hanoi
Ho Chi Minh City
Hong Kong
Honolulu
Istanbul
Jakarta
Jerusalem
Johannesburg
Kansas City MO
Kolkata
Kuala Lumpur
Las Vegas NV
Lisbon
London
Los Angeles CA
Madrid
Marseille
Melbourne
Mexico City
Miami FL
Montreal
Moscow
Mumbai
New Delhi
New Orleans LA
New York City NY
Oakland CA
Orlando FL
Osaka
Oslo
Ottawa
Paris
Philadelphia PA
Phoenix AZ
Phuket
Portland OR
Porto
Prague
Quebec City
Reykjavik
Rio de Janeiro
Rome
Saint Petersburg
Salt Lake City UT
San Francisco CA
Santiago
Sao Paulo
Seattle WA
Seoul
Sevilla
Shanghai
Singapore
Sofia
Stockholm
Sydney
Taghazout
Tel Aviv
Tokyo
Toronto
Tucson AZ
Ubud Bali
Valencia
Vancouver
Venice
Vienna
Warsaw
Washington DC
Wellington
Zurich
Albuquerque NM
Vermont IL
Nashville TE
St. Louis MO
Minneapolis MN
2.2.3 从字符串变量读取
首先导入模块 json ,然后利用 json.loads() 方法读取 字符串变量。
import json
json_str = '{"firstName": "John", "lastName": "Simit", "phoneNumber": [{"type": "home", "number": "1234567"}, {"type": "work", "number": "7654321"}]}'
json_data = json.loads(json_str)
print(json_data)
{'phoneNumber': [{'type': 'home', 'number': '1234567'}, {'type': 'work', 'number': '7654321'}], 'lastName': 'Simit', 'firstName': 'John'}
2.3 写入json
2.3.1 写入json文件
使用 json.dump() 写入json文件,要注意编码格式为 UTF-8,它的默认参数 ensure_ascii 默认为 True,是指默认编码格式为 ascii码,我们这里写入了中文,所以要修改这个参数。
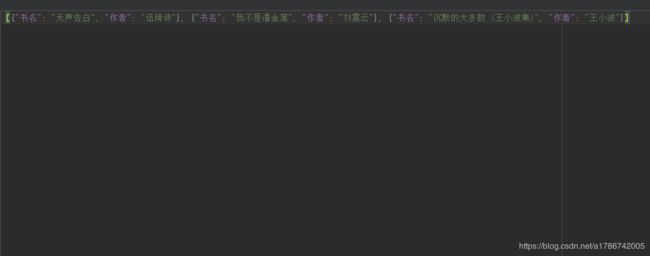
book_dict_list = [{'书名':'无声告白', '作者':'伍绮诗'}, {'书名':'我不是潘金莲', '作者':'刘震云'}, {'书名':'沉默的大多数 (王小波集)', '作者':'王小波'}]
filename = './files/json_output.json'
with open(filename, mode='w', encoding='utf-8') as f_obj:
json.dump(book_dict_list, f_obj, ensure_ascii=False)
看一下这个json文件:
2.3.2 写入字符串变量
使用 json.dumps() 写入字符串变量,要注意编码格式为 UTF-8,它的默认参数 ensure_ascii 默认为 True,是指默认编码格式为 ascii码,我们这里写入了中文,所以要修改这个参数。
json_str = json.dumps(book_dict_list, ensure_ascii=False)
type(json_str)
print(json_str)
str
[{"书名": "无声告白", "作者": "伍绮诗"}, {"书名": "我不是潘金莲", "作者": "刘震云"}, {"书名": "沉默的大多数 (王小波集)", "作者": "王小波"}]
三、CSV文件操作
3.1 CSV文件介绍
以纯文本形式存储的表格数据(以逗号作为分隔符),通常第一行为列名 。
3.2 CSV文件的读取
常用 pandas工具包 中的 pandas.read_csv() 来读取,数据类型为 DataFrame
import pandas as pd
filename = './files/menu.csv'
df_obj = pd.read_csv(filename)
print(type(df_obj))
1、获取单列数据
# 获取单列数据
single_col_data = df_obj['Item']
print(single_col_data)
0 Egg McMuffin
1 Egg White Delight
2 Sausage McMuffin
3 Sausage McMuffin with Egg
4 Sausage McMuffin with Egg Whites
5 Steak & Egg McMuffin
6 Bacon, Egg & Cheese Biscuit (Regular Biscuit)
7 Bacon, Egg & Cheese Biscuit (Large Biscuit)
8 Bacon, Egg & Cheese Biscuit with Egg Whites (R...
9 Bacon, Egg & Cheese Biscuit with Egg Whites (L...
10 Sausage Biscuit (Regular Biscuit)
11 Sausage Biscuit (Large Biscuit)
12 Sausage Biscuit with Egg (Regular Biscuit)
13 Sausage Biscuit with Egg (Large Biscuit)
14 Sausage Biscuit with Egg Whites (Regular Biscuit)
15 Sausage Biscuit with Egg Whites (Large Biscuit)
16 Southern Style Chicken Biscuit (Regular Biscuit)
17 Southern Style Chicken Biscuit (Large Biscuit)
18 Steak & Egg Biscuit (Regular Biscuit)
19 Bacon, Egg & Cheese McGriddles
20 Bacon, Egg & Cheese McGriddles with Egg Whites
21 Sausage McGriddles
22 Sausage, Egg & Cheese McGriddles
23 Sausage, Egg & Cheese McGriddles with Egg Whites
24 Bacon, Egg & Cheese Bagel
25 Bacon, Egg & Cheese Bagel with Egg Whites
26 Steak, Egg & Cheese Bagel
27 Big Breakfast (Regular Biscuit)
28 Big Breakfast (Large Biscuit)
29 Big Breakfast with Egg Whites (Regular Biscuit)
...
230 Frappé Chocolate Chip (Medium)
231 Frappé Chocolate Chip (Large)
232 Blueberry Pomegranate Smoothie (Small)
233 Blueberry Pomegranate Smoothie (Medium)
234 Blueberry Pomegranate Smoothie (Large)
235 Strawberry Banana Smoothie (Small)
236 Strawberry Banana Smoothie (Medium)
237 Strawberry Banana Smoothie (Large)
238 Mango Pineapple Smoothie (Small)
239 Mango Pineapple Smoothie (Medium)
240 Mango Pineapple Smoothie (Large)
241 Vanilla Shake (Small)
242 Vanilla Shake (Medium)
243 Vanilla Shake (Large)
244 Strawberry Shake (Small)
245 Strawberry Shake (Medium)
246 Strawberry Shake (Large)
247 Chocolate Shake (Small)
248 Chocolate Shake (Medium)
249 Chocolate Shake (Large)
250 Shamrock Shake (Medium)
251 Shamrock Shake (Large)
252 McFlurry with M&M’s Candies (Small)
253 McFlurry with M&M’s Candies (Medium)
254 McFlurry with M&M’s Candies (Snack)
255 McFlurry with Oreo Cookies (Small)
256 McFlurry with Oreo Cookies (Medium)
257 McFlurry with Oreo Cookies (Snack)
258 McFlurry with Reese's Peanut Butter Cups (Medium)
259 McFlurry with Reese's Peanut Butter Cups (Snack)
Name: Item, Length: 260, dtype: object
2、获取多列数据
# 获取多列数据
filtered_data = df_obj[['Item', 'Calories']]
print(filtered_data)
Item Calories
0 Egg McMuffin 300
1 Egg White Delight 250
2 Sausage McMuffin 370
3 Sausage McMuffin with Egg 450
4 Sausage McMuffin with Egg Whites 400
5 Steak & Egg McMuffin 430
6 Bacon, Egg & Cheese Biscuit (Regular Biscuit) 460
7 Bacon, Egg & Cheese Biscuit (Large Biscuit) 520
8 Bacon, Egg & Cheese Biscuit with Egg Whites (R... 410
9 Bacon, Egg & Cheese Biscuit with Egg Whites (L... 470
10 Sausage Biscuit (Regular Biscuit) 430
11 Sausage Biscuit (Large Biscuit) 480
12 Sausage Biscuit with Egg (Regular Biscuit) 510
13 Sausage Biscuit with Egg (Large Biscuit) 570
14 Sausage Biscuit with Egg Whites (Regular Biscuit) 460
15 Sausage Biscuit with Egg Whites (Large Biscuit) 520
16 Southern Style Chicken Biscuit (Regular Biscuit) 410
17 Southern Style Chicken Biscuit (Large Biscuit) 470
18 Steak & Egg Biscuit (Regular Biscuit) 540
19 Bacon, Egg & Cheese McGriddles 460
20 Bacon, Egg & Cheese McGriddles with Egg Whites 400
21 Sausage McGriddles 420
22 Sausage, Egg & Cheese McGriddles 550
23 Sausage, Egg & Cheese McGriddles with Egg Whites 500
24 Bacon, Egg & Cheese Bagel 620
25 Bacon, Egg & Cheese Bagel with Egg Whites 570
26 Steak, Egg & Cheese Bagel 670
27 Big Breakfast (Regular Biscuit) 740
28 Big Breakfast (Large Biscuit) 800
29 Big Breakfast with Egg Whites (Regular Biscuit) 640
.. ... ...
230 Frappé Chocolate Chip (Medium) 630
231 Frappé Chocolate Chip (Large) 760
232 Blueberry Pomegranate Smoothie (Small) 220
233 Blueberry Pomegranate Smoothie (Medium) 260
234 Blueberry Pomegranate Smoothie (Large) 340
235 Strawberry Banana Smoothie (Small) 210
236 Strawberry Banana Smoothie (Medium) 250
237 Strawberry Banana Smoothie (Large) 330
238 Mango Pineapple Smoothie (Small) 210
239 Mango Pineapple Smoothie (Medium) 260
240 Mango Pineapple Smoothie (Large) 340
241 Vanilla Shake (Small) 530
242 Vanilla Shake (Medium) 660
243 Vanilla Shake (Large) 820
244 Strawberry Shake (Small) 550
245 Strawberry Shake (Medium) 690
246 Strawberry Shake (Large) 850
247 Chocolate Shake (Small) 560
248 Chocolate Shake (Medium) 700
249 Chocolate Shake (Large) 850
250 Shamrock Shake (Medium) 660
251 Shamrock Shake (Large) 820
252 McFlurry with M&M’s Candies (Small) 650
253 McFlurry with M&M’s Candies (Medium) 930
254 McFlurry with M&M’s Candies (Snack) 430
255 McFlurry with Oreo Cookies (Small) 510
256 McFlurry with Oreo Cookies (Medium) 690
257 McFlurry with Oreo Cookies (Snack) 340
258 McFlurry with Reese's Peanut Butter Cups (Medium) 810
259 McFlurry with Reese's Peanut Butter Cups (Snack) 410
[260 rows x 2 columns]
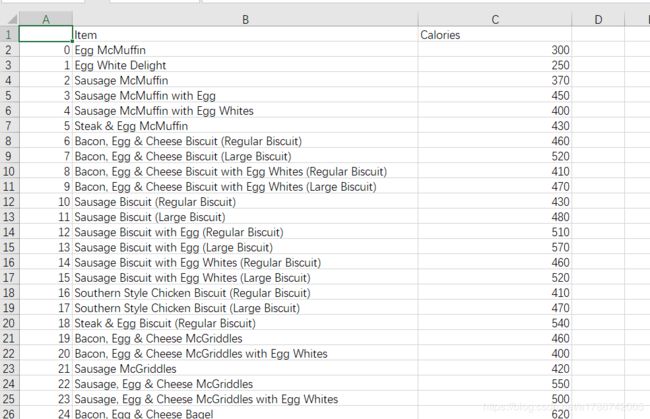
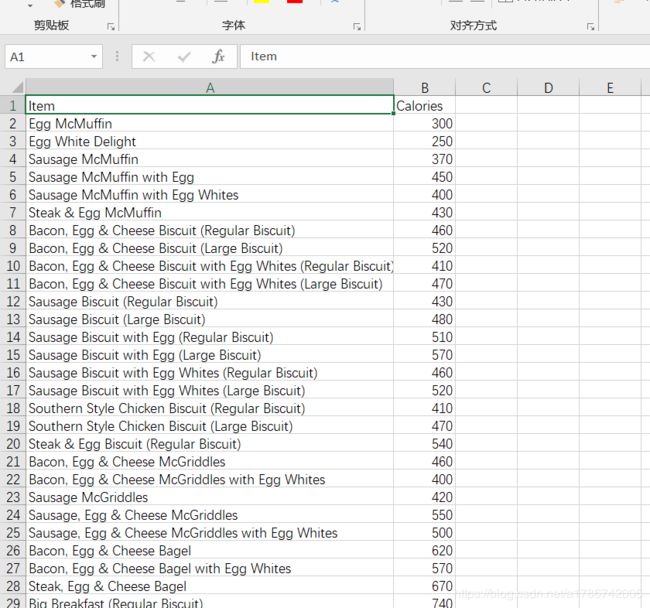
3.3 CSV文件的写入
使用 to_csv方法 进行写入
# 包含索引列
filtered_data.to_csv('./files/filtered_data.csv')
# 不包含索引列
filtered_data.to_csv('./files/filtered_data.csv', index=False)
写入结果如分别如下:
四、EXCEL文件操作
4.1 EXCEL文件的读取
导入 pandas库,利用 pandas.read_excel() 方法来读取 excel文件,其中的 sheetname 参数是指选取哪个工作簿。
4.1.1 读取单个工作簿
数据类型为 DataFrame 类型
import pandas as pd
filename = './files/happiness.xlsx'
# 读入单个工作簿,指定sheetname
df_obj = pd.read_excel(filename, sheetname='2016')
print(type(df_obj))
# 打印前五行数据
print(df_obj.head())
Country Region Happiness Rank Happiness Score \
0 Denmark Western Europe 1 7.526
1 Switzerland Western Europe 2 7.509
2 Iceland Western Europe 3 7.501
3 Norway Western Europe 4 7.498
4 Finland Western Europe 5 7.413
Lower Confidence Interval Upper Confidence Interval \
0 7.460 7.592
1 7.428 7.590
2 7.333 7.669
3 7.421 7.575
4 7.351 7.475
Economy (GDP per Capita) Family Health (Life Expectancy) Freedom \
0 1.44178 1.16374 0.79504 0.57941
1 1.52733 1.14524 0.86303 0.58557
2 1.42666 1.18326 0.86733 0.56624
3 1.57744 1.12690 0.79579 0.59609
4 1.40598 1.13464 0.81091 0.57104
Trust (Government Corruption) Generosity Dystopia Residual
0 0.44453 0.36171 2.73939
1 0.41203 0.28083 2.69463
2 0.14975 0.47678 2.83137
3 0.35776 0.37895 2.66465
4 0.41004 0.25492 2.82596
4.1.2 读取多行工作簿
数据类型为 OrderedDict 格式,也是一种字典形式
# 读入多个工作簿
df_data = pd.read_excel(filename, sheetname=['2015', '2017'])
print(type(df_data))
和 Dict 数据类型操作相同,若想提取出2015这一工作簿,则:
print(df_data['2015'].head())
Country Region Happiness Rank Happiness Score \
0 Switzerland Western Europe 1 7.587
1 Iceland Western Europe 2 7.561
2 Denmark Western Europe 3 7.527
3 Norway Western Europe 4 7.522
4 Canada North America 5 7.427
Standard Error Economy (GDP per Capita) Family \
0 0.03411 1.39651 1.34951
1 0.04884 1.30232 1.40223
2 0.03328 1.32548 1.36058
3 0.03880 1.45900 1.33095
4 0.03553 1.32629 1.32261
Health (Life Expectancy) Freedom Trust (Government Corruption) \
0 0.94143 0.66557 0.41978
1 0.94784 0.62877 0.14145
2 0.87464 0.64938 0.48357
3 0.88521 0.66973 0.36503
4 0.90563 0.63297 0.32957
Generosity Dystopia Residual
0 0.29678 2.51738
1 0.43630 2.70201
2 0.34139 2.49204
3 0.34699 2.46531
4 0.45811 2.45176
4.2 EXCEL文件的写入
使用 to_excel() 方法写入
4.2.1 写入单个工作簿
# 写入单个工作簿
top5_2015 = df_data['2015'].head()
# 不带索引写入,可以类比csv文件的写入
top5_2015.to_excel('./files/2015_top5.xlsx', index=False)
写入的结果如下:
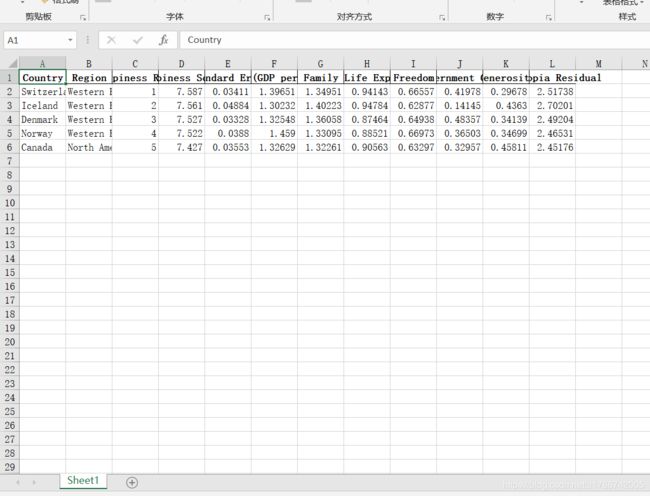
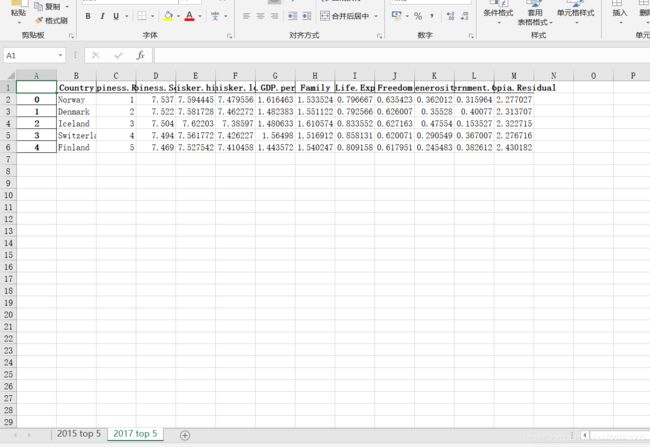
4.2.2 写入多个工作簿
# 写入多个工作簿
top5_2015 = df_data['2015'].head()
top5_2017 = df_data['2017'].head()
writer = pd.ExcelWriter('./files/2015_2017_top5.xlsx')
top5_2015.to_excel(writer, '2015 top 5')
top5_2017.to_excel(writer, '2017 top 5')
writer.save()
写入的结果如下: