LVQ模型Python实现
- https://github.com/Sean16SYSU/MachineLearningImplement
简述
LVQ模型是聚类的经典模型,跟Kmeans有点像。但是作为一个聚类,这个模型是一个有监督的模型。
算法流程
- 输入的数据集X, y,还有学习率(在0,1之间) η \eta η
- 初始,选k个点,作为原型向量
- 然后开始循环
- 在样本集中随机选个点。
- 找到在原型向量中离它最近的点
- 然后来比较这两个点之间的y是否一样。一样就正向更新节点,不一样就反向更新节点
- p i = p i ( + / − ) η ∗ ( x j − p i ) p_i = p_i (+ / -) \eta * (x_j- p_i) pi=pi(+/−)η∗(xj−pi) 中间选是加或者减。
- 迭代一定的次数,或者变化足够小之后,就退出迭代
实验部分
- 导入数据
from sklearn import datasets
iris = datasets.load_iris()
- 数据规模测试
iris.data.shape, iris.target.shape
((150, 4), (150,))
- 随机挑选节点作为训练集合
import numpy as np
def random_split(X, y, train_rate=0.3):
y_ = np.array(list(zip(y, range(len(y)))))
np.random.shuffle(y_)
train_n = int(len(y) * train_rate)
y_train = y_[:train_n]
y_test = y_[train_n:]
index_train = y_train[:, 1]
index_test = y_test[:, 1]
return X[index_train], y_train[:, 0], X[index_test], y_test[:, 0]
- LVQ函数和LVQ的聚类函数
def LVQ(X, y, k, MAX_TIME=100, ita=0.2):
init_index = np.random.choice(len(y), k)
px = X[init_index]
py = y[init_index]
for _ in range(MAX_TIME):
j = np.random.choice(len(y), 1)
xj, yj = X[j], y[j]
i = np.argmin([np.linalg.norm(xj - pi) for pi in px])
pyi = py[i]
if pyi == yj:
px[i] = px[i] + ita * (xj - px[i])
else:
px[i] = px[i] - ita * (xj - px[i])
return px
def PVQ_clustering(X, px):
return np.array(list(map(lambda x: np.argmin([np.linalg.norm(x - pi) for pi in px]), X)))
- 拆分数据集并训练
train_x, train_y, test_x, test_y = random_split(iris.data, iris.target)
px = LVQ(train_x, train_y, 3)
y = PVQ_clustering(test_x, px)
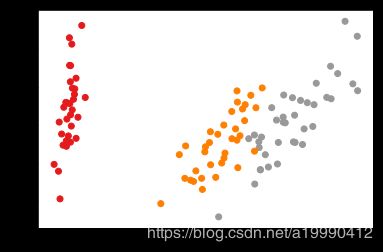
- 画图
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
X_reduced = PCA(n_components=2).fit_transform(test_x)
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=y, cmap=plt.cm.Set1)

- 实际值
- 算法估量:这里只考虑外部指标
def evaluate(y, t):
a, b, c, d = [0 for i in range(4)]
for i in range(len(y)):
for j in range(i+1, len(y)):
if y[i] == y[j] and y[j] == t[j]:
a += 1
elif y[i] == y[j] and y[j] != t[j]:
b += 1
elif y[i] != y[j] and y[j] == t[j]:
c += 1
elif y[i] != y[j] and y[j] != t[j]:
d += 1
return a, b, c, d
a, b, c, d = evaluate(y, test_y)
def external_index(a, b, c, d, m):
JC = a / (a + b + c)
FMI = np.sqrt(a**2 / ((a + b) * (a + c)))
RI = 2 * ( a + d ) / ( m * (m + 1) )
return JC, FMI, RI
external_index(a, b, c, d, len(y))
- 将最后的结果展示下
| External index | Value |
|---|---|
| JC | 0.1485971596813301 |
| FMI | 0.26021571720401077 |
| RI | 0.5394429469901169 |
