Faster RCNN 学习笔记
下面的介绍都是基于VGG16 的Faster RCNN网络,各网络的差异在于Conv layers层提取特征时有细微差异,至于后续的RPN层、Pooling层及全连接的分类和目标定位基本相同.
一)、整体框架
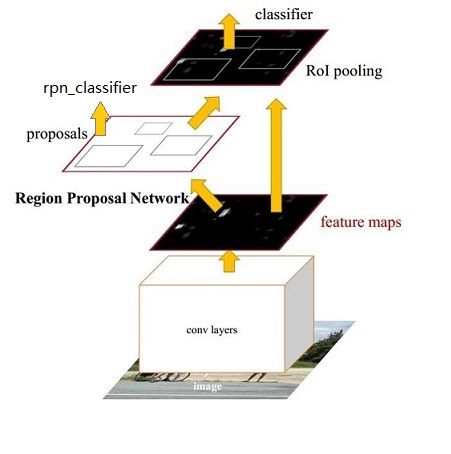
我们先整体的介绍下上图中各层主要的功能
1)、Conv layers提取特征图:
作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取input image的feature maps,该feature maps会用于后续的RPN层和全连接层
2)、RPN(Region Proposal Networks):
RPN网络主要用于生成region proposals,首先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体or不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal(注:这里的较精确是相对于后面全连接层的再一次box regression而言)
3)、Roi Pooling:
该层利用RPN生成的proposals和VGG16最后一层得到的feature map,得到固定大小的proposal feature map,进入到后面可利用全连接操作来进行目标识别和定位
4)、Classifier:
会将Roi Pooling层形成固定大小的feature map进行全连接操作,利用Softmax进行具体类别的分类,同时,利用L1 Loss完成bounding box regression回归操作获得物体的精确位置.
二)、网络结构
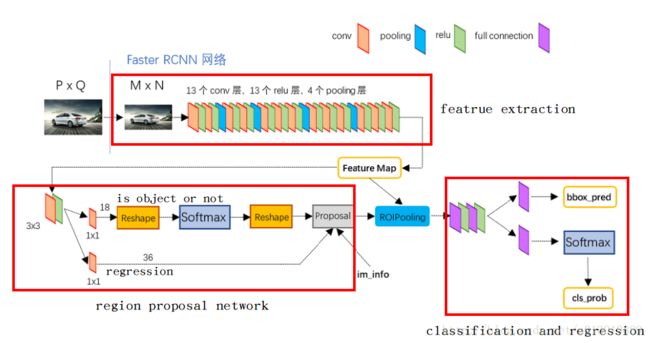
现在,通过上图开始逐层分析
1)、Conv layers
Faster RCNN首先是支持输入任意大小的图片的,比如上图中输入的P*Q,进入网络之前对图片进行了规整化尺度的设定,如可设定图像短边不超过600,图像长边不超过1000,我们可以假定M*N=1000*600(如果图片少于该尺寸,可以边缘补0,即图像会有黑色边缘)
- 13个conv层:kernel_size=3,pad=1,stride=1;
卷积公式:![]()
outputsize=intputsize-kernel_size+2*padstride+1
所以,conv层不会改变图片大小(即:输入的图片大小=输出的图片大小)
- 13个relu层:激活函数,不改变图片大小
- 4个pooling层:kernel_size=2,stride=2;pooling层会让输出图片是输入图片的1/2
经过Conv layers,图片大小变成(M/16)*(N/16),即:60*40(1000/16≈60,600/16≈40);则,Feature Map就是60*40*512-d(注:VGG16是512-d,ZF是256-d),表示特征图的大小为60*40,数量为512
2)、RPN(Region Proposal Networks):
Feature Map进入RPN后,先经过一次3*3的卷积,同样,特征图大小依然是60*40,数量512,这样做的目的应该是进一步集中特征信息,接着看到两个全卷积,即kernel_size=1*1,p=0,stride=1;
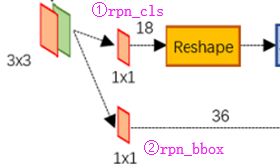
如上图中标识:
- rpn_cls:60*40*512-d ⊕ 1*1*512*18 ==> 60*40*9*2
- 逐像素对其9个Anchor box进行二分类
- rpn_bbox:60*40*512-d ⊕ 1*1*512*36==>60*40*9*4
逐像素得到其9个Anchor box四个坐标信息(其实是偏移量,后面介绍)
如下图所示:
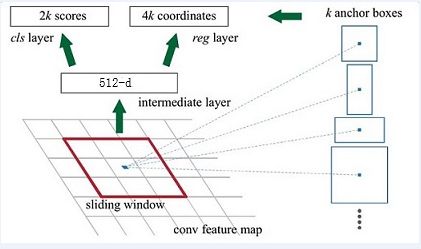
(2.1)、Anchors的生成规则
前面提到经过Conv layers后,图片大小变成了原来的1/16,令feat_stride=16,在生成Anchors时,我们先定义一个base_anchor,大小为16*16的box(因为特征图(60*40)上的一个点,可以对应到原图(1000*600)上一个16*16大小的区域),源码中转化为[0,0,15,15]的数组,参数ratios=[0.5, 1, 2]scales=[8, 16, 32]
先看[0,0,15,15],面积保持不变,长、宽比分别为[0.5, 1, 2]是产生的Anchors box
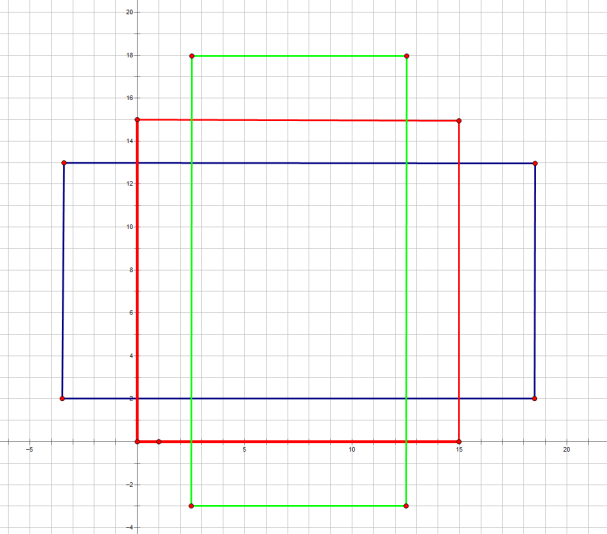
如果经过scales变化,即长、宽分别均为 (16*8=128)、(16*16=256)、(16*32=512),对应anchor box如图
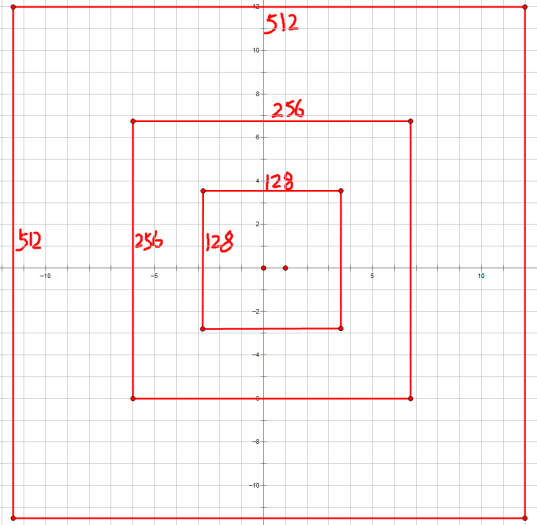
综合以上两种变换,最后生成9个Anchor box
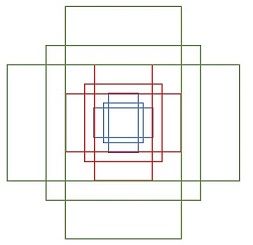
所以,最终base_anchor=[0,0,15,15]生成的9个Anchor box坐标如下:
![]()
1 [[ -84. -40. 99. 55.] 2 [-176. -88. 191. 103.] 3 [-360. -184. 375. 199.] 4 [ -56. -56. 71. 71.] 5 [-120. -120. 135. 135.] 6 [-248. -248. 263. 263.] 7 [ -36. -80. 51. 95.] 8 [ -80. -168. 95. 183.] 9 [-168. -344. 183. 359.]]
![]()
特征图大小为60*40,所以会一共生成60*40*9=21600个Anchor box
源码中,通过width:(0~60)*16,height(0~40)*16建立shift偏移量数组,再和base_ancho基准坐标数组累加,得到特征图上所有像素对应的Anchors的坐标值,是一个[216000,4]的数组
(2.2)、RPN工作原理解析
为了进一步更清楚的看懂RPN的工作原理,将Caffe版本下的网络图贴出来,对照网络图进行讲解会更清楚
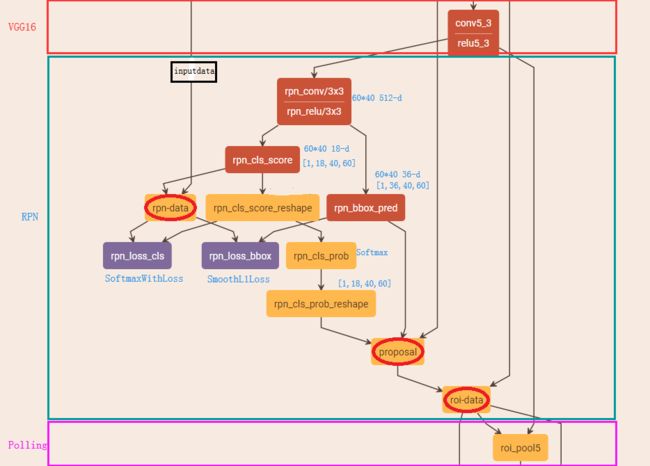
主要看上图中框住的‘RPN’部分的网络图,其中‘rpn_conv/3*3’是3*3的卷积,上面有提到过,接着是两个1*1的全卷积,分别是图中的‘rpn_cls_score’和‘rpn_bbox_pred’,在上面同样有提到过。接下来,分析网络图中其他各部分的含义
2.2.1)、rpn-data

这一层主要是为特征图60*40上的每个像素生成9个Anchor box,并且对生成的Anchor box进行过滤和标记,参照源码,过滤和标记规则如下:
- 去除掉超过1000*600这原图的边界的anchor box
- 如果anchor box与ground truth的IoU值最大,标记为正样本,label=1
- 如果anchor box与ground truth的IoU>0.7,标记为正样本,label=1
- 如果anchor box与ground truth的IoU<0.3,标记为负样本,label=0
剩下的既不是正样本也不是负样本,不用于最终训练,label=-1
什么是IoU:
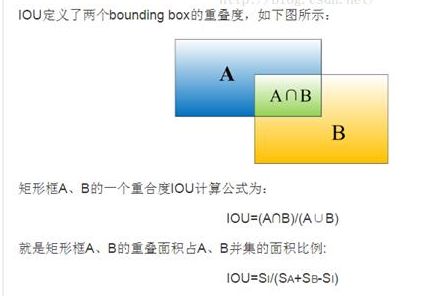
除了对anchor box进行标记外,另一件事情就是计算anchor box与ground truth之间的偏移量
令:ground truth:标定的框也对应一个中心点位置坐标x*,y*和宽高w*,h*
anchor box: 中心点位置坐标x_a,y_a和宽高w_a,h_a
所以,偏移量:
△x=(x*-x_a)/w_a △y=(y*-y_a)/h_a
△w=log(w*/w_a) △h=log(h*/h_a)
通过ground truth box与预测的anchor box之间的差异来进行学习,从而是RPN网络中的权重能够学习到预测box的能力
2.2.2) 、rpn_loss_cls、rpn_loss_bbox、rpn_cls_prob
下面集体看下这三个,其中‘rpn_loss_cls’、‘rpn_loss_bbox’是分别对应softmax,smooth L1计算损失函数,‘rpn_cls_prob’计算概率值(可用于下一层的nms非最大值抑制操作)
补充:
① Softmax公式,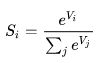 计算各分类的概率值
计算各分类的概率值
② Softmax Loss公式,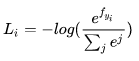 RPN进行分类时,即寻找最小Loss值
RPN进行分类时,即寻找最小Loss值
在’rpn-data’中已经为预测框anchor box进行了标记,并且计算出与gt_boxes之间的偏移量,利用RPN网络进行训练。
RPN训练设置:在训练RPN时,一个Mini-batch是由一幅图像中任意选取的256个proposal组成的,其中正负样本的比例为1:1。如果正样本不足128,则多用一些负样本以满足有256个Proposal可以用于训练,反之亦然
2.2.3)、proposal

在输入中我们看到’rpn_bbox_pred’,记录着训练好的四个回归值△x, △y, △w, △h。
源码中,会重新生成60*40*9个anchor box,然后累加上训练好的△x, △y, △w, △h,从而得到了相较于之前更加准确的预测框region proposal,进一步对预测框进行越界剔除和使用nms非最大值抑制,剔除掉重叠的框;比如,设定IoU为0.7的阈值,即仅保留覆盖率不超过0.7的局部最大分数的box(粗筛)。最后留下大约2000个anchor,然后再取前N个box(比如300个);这样,进入到下一层ROI Pooling时region proposal大约只有300个
用下图一个案例来对NMS算法进行简单介绍

如上图所示,一共有6个识别为人的框,每一个框有一个置信率。
现在需要消除多余的:
- 按置信率排序: 0.95, 0.9, 0.9, 0.8, 0.7, 0.7
- 取最大0.95的框为一个物体框
- 剩余5个框中,去掉与0.95框重叠率IoU大于0.6(可以另行设置),则保留0.9, 0.8, 0.7三个框
- 重复上面的步骤,直到没有框了,0.9为一个框
- 选出来的为: 0.95, 0.9
所以,整个过程,可以用下图形象的表示出来
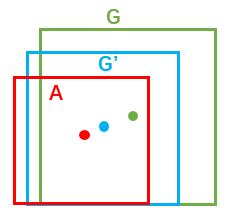
其中,红色的A框是生成的anchor box,而蓝色的G’框就是经过RPN网络训练后得到的较精确的预测框,绿色的G是ground truth box
2.2.4)、roi_data

为了避免定义上的误解,我们将经过‘proposal’后的预测框称为region proposal(其实,RPN层的任务其实已经完成,roi_data属于为下一层准备数据)
主要作用:
- RPN层只是来确定region proposal是否是物体(是/否),这里根据region proposal和ground truth box的最大重叠指定具体的标签(就不再是二分类问题了,参数中指定的是81类)
- 计算region proposal与ground truth boxes的偏移量,计算方法和之前的偏移量计算公式相同
经过这一步后的数据输入到ROI Pooling层进行进一步的分类和定位.
3)、ROI Pooling:

从上述的Caffe代码中可以看到,输入的是RPN层产生的region proposal(假定有300个region proposal box)和VGG16最后一层产生的特征图(60*40 512-d),遍历每个region proposal,将其坐标值缩小16倍,这样就可以将在原图(1000*600)基础上产生的region proposal映射到60*40的特征图上,从而将在feature map上确定一个区域(定义为RB*)。
在feature map上确定的区域RB*,根据参数pooled_w:7,pooled_h:7,将这个RB*区域划分为7*7,即49个相同大小的小区域,对于每个小区域,使用max pooling方式从中选取最大的像素点作为输出,这样,就形成了一个7*7的feature map
细节可查看:https://www.cnblogs.com/wangyong/p/8523814.html
以此,参照上述方法,300个region proposal遍历完后,会产生很多个7*7大小的feature map,故而输出的数组是:[300,512,7,7],作为下一层的全连接的输入
4)、全连接层:
经过roi pooling层之后,batch_size=300, proposal feature map的大小是7*7,512-d,对特征图进行全连接,参照下图,最后同样利用Softmax Loss和L1 Loss完成分类和定位
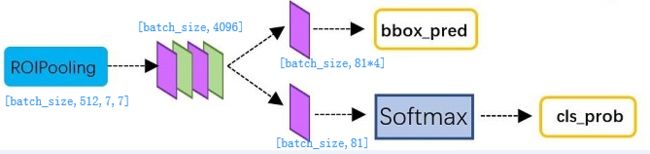
通过full connect层与softmax计算每个region proposal具体属于哪个类别(如人,马,车等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个region proposal的位置偏移量bbox_pred,用于回归获得更加精确的目标检测框
即从PoI Pooling获取到7x7大小的proposal feature maps后,通过全连接主要做了:
4.1)通过全连接和softmax对region proposals进行具体类别的分类
4.2)再次对region proposals进行bounding box regression,获取更高精度的rectangle boxVersion:1.0 StartHTML:000000210