sbt的安装以及用sbt编译打包scala编写的spark程序
众所周知,spark可以使用三种语言进行编写,分别是scala,phython,java三种语言,而且执行方式不同,Scala是用sbt编译打包,Java是用Maven进行编译打包,而phython则是用spark-submit提交运行。而sbt本身就是用scala进行编写的。这里记录以下自己在Linux下安装sbt的过程以及编译打包spark程序的流程,以做备忘。
1 .首先进入根目录创建相应的目录结构,执行下面的这些命令,这里-p参数表示创建多级目录
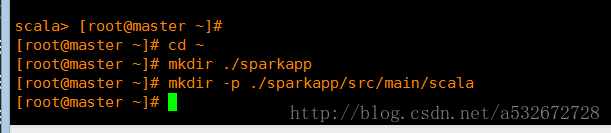
2 .之后通过cd 命令进入这里创建的scala目录下,通过vim SimpleApp.scala创建scala文件,里面是空的,添加下面这些内容,这个程序是用来统计一个文本中含有字母a和含有字母b的行数,这里指定的logFile是存放在Linux下的相应目录下,注意这里是///,这个logFile可以在windows下创建通过xftp4进行传输,也可以直接在linux下直接创建,这个内容是Spark压缩包中自带的

3 .之后在Linux下输入spark-shell,查看一下spark和scala对应的版本,记录下来,稍后会用到

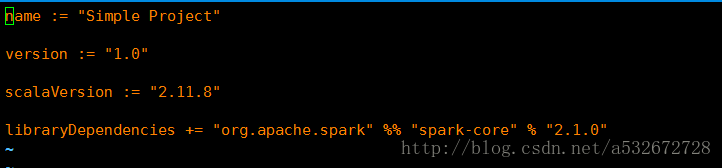
4 .进入之前创建的sparkapp目录,通过vim simple.sbt创建一个sbt文件,这个文件用来指明之前创建的scala文件与spark之间的关系,主要是指定名字,spark,scala的相关版本,注意这里一定要和自己安装的版本对应起来。

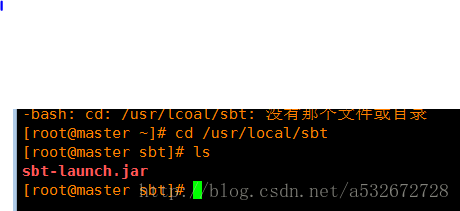
5 .之后去这个网站下载sbt的jar包,下载后将其拷贝到/usr/local/sbt目录下,如果没有这个目录,通过mkdir -p创建这个目录,之后通过cd,进入这个sbt目录
http://www.scala-sbt.org/0.13/docs/zh-cn/Manual-Installation.html
6 .之后在这个sbt同级目录下,通过vim sbt创建sbt脚本,内容如下,这里主要指定Java虚拟机内存相关配置以及sbt jar包的位置

7 .之后执行chmod u+x sbt为sbt脚本增加可执行权限,其实这里没必要,因为我使用得是root用户,如果你是普通用户,那么一定要执行这条命令

8 .接下来验证下是否成功,执行./sbt sbt-version,这里需要等很长时间,取决于网速了,闲着无聊测了下大概有十分钟,够我打两盘炉石了,哈哈。。。
9 .玩了两盘炉石后回来发现出现下面这个内容,之后再次执行刚才的命令,出现下面这两张图,表示ok


10 .用sbt编译打包之前首先看一下包结构是否符合要求,只有符合要求的编译结构才能成功编译打包,执行下面命令查看
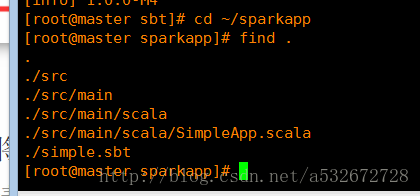
11 .之后进入之前存放jar包的目录,即/usr/local/sbt,执行sbt package命令进行打包,放心,这里又会等待漫长时间,又可以打两盘炉石了。。。。回来看

12 .最后显示这么一个信息,表示打包成功,打包的jar包放在了根目录下的sparkapp/target下面

13 .最后进入spark的bin目录,通过spark-submit命令将打包好的jar包提交到spark运行即可,见下图运行结果

14 .OK,以上就是在Linux下面sbt的安装以及如果用sbt编译打包一个spark程序的过程。