Spark学习实例(Python):窗口操作 Window Operations
说到流处理,Spark为我们提供了窗口函数,允许在滑动数据窗口上应用转换,常用场景如每五分钟商场人流密度、每分钟流量等等,接下来我们通过画图来了解Spark Streaming的窗口函数如何工作的,处理过程图如下所示:
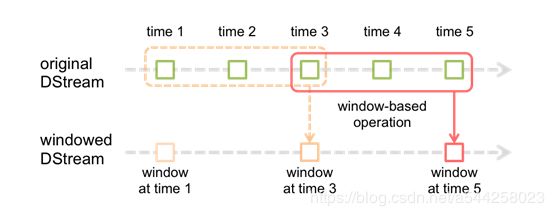
上图中绿色的小框框是一批一批的数据流,虚线框和实线框分别是前一个窗口和后一个窗口,从图中可以看出后一个窗口在前一个窗口基础上移动了两个批次的数据流,而我们真正通过算子操作的数据其实就是窗口内所有的数据流。
在代码实现前了解下窗口操作常用的函数有:
- window
- countByWindow
- reduceByWindow
- reduceByKeyAndWindow
- reduceByKeyAndWindow
- countByValueAndWindow
window最原始的窗口,提供两个参数,第一个参数是窗口长度,第二个参数是滑动间隔,返回一个新的DStream, 返回的结果可以进行算子操作,代码实现如下
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == '__main__':
sc = SparkContext(appName="windowStream", master="local[*]")
# 第二个参数指统计多长时间的数据
ssc = StreamingContext(sc, 5)
lines = ssc.socketTextStream("localhost", 9999)
# 第一个参数是窗口长度,这里是60秒, 第二个参数是滑动间隔,这里是10秒
dstream = lines.window(60, 10)
dstream.pprint()
# -------------------------------------------
# Time: 2019-08-13 19:46:45
# -------------------------------------------
# hello
# world
ssc.start()
ssc.awaitTermination()现在终端使用nc发送数据
root@root:~$ nc -lk 9999
hello
world
countByWindow统计每个滑动窗口内数据条数,要注意的是使用该函数要加上checkpoint机制,代码实现如下
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == '__main__':
sc = SparkContext(appName="windowStream", master="local[*]")
# 第二个参数指统计多长时间的数据
ssc = StreamingContext(sc, 5)
ssc.checkpoint("/tmp/window")
lines = ssc.socketTextStream("localhost", 9999)
# 第一个参数是窗口长度,这里是60秒, 第二个参数是滑动间隔,这里是10秒
dstream = lines.countByWindow(60, 10)
dstream.pprint()
# -------------------------------------------
# Time: 2019-08-14 18:56:40
# -------------------------------------------
# 2
ssc.start()
ssc.awaitTermination()reduceByWindow聚合每个键的值,底层执行的是reduceByKeyAndWindow,实现代码如下
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
def fun(x):
return x
if __name__ == '__main__':
sc = SparkContext(appName="windowStream", master="local[*]")
# 第二个参数指统计多长时间的数据
ssc = StreamingContext(sc, 5)
ssc.checkpoint("/tmp/window")
lines = ssc.socketTextStream("localhost", 9999)
# 第一个参数执行指定函数, 第二个参数是窗口长度,这里是60秒, 第三个参数是滑动间隔,这里是10秒
dstream = lines.reduceByWindow(fun, 60, 10)
dstream.pprint()
# -------------------------------------------
# Time: 2019-08-14 19:23:30
# -------------------------------------------
# hello
ssc.start()
ssc.awaitTermination()reduceByKeyAndWindow是对(K,V)窗口数据相同的K执行对应的fun,实现代码如下
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
def fun(x,y):
return x+y
if __name__ == '__main__':
sc = SparkContext(appName="windowStream", master="local[*]")
# 第二个参数指统计多长时间的数据
ssc = StreamingContext(sc, 5)
ssc.checkpoint("/tmp/window")
lines = ssc.socketTextStream("localhost", 9999)
# 第一个参数执行的功能函数fun, 第二个参数是窗口长度,这里是60秒, 第三个参数是滑动间隔,这里是10秒,
# 第四个参数设定并行度
dstream = lines.map(lambda x:(x,1)).reduceByKeyAndWindow(fun, 60, 10)
dstream.pprint()
# -------------------------------------------
# Time: 2019-08-14 19:23:30
# -------------------------------------------
# ('hello', 2)
ssc.start()
ssc.awaitTermination()countByValueAndWindow是对窗口数据进行单词统计,实现代码如下
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == '__main__':
sc = SparkContext(appName="windowStream", master="local[*]")
# 第二个参数指统计多长时间的数据
ssc = StreamingContext(sc, 5)
ssc.checkpoint("/tmp/window")
lines = ssc.socketTextStream("localhost", 9999)
# 第一个参数是窗口长度,这里是60秒, 第二个参数是滑动间隔,这里是10秒, 第三个参数任务并行度
dstream = lines.countByValueAndWindow(60, 10)
dstream.pprint()
# -------------------------------------------
# Time: 2019-08-14 19:23:30
# -------------------------------------------
# ('hello', 3)
# ('world', 1)
ssc.start()
ssc.awaitTermination()以上就是所有窗口函数的使用
Spark学习目录:
- Spark学习实例1(Python):单词统计 Word Count
- Spark学习实例2(Python):加载数据源Load Data Source
- Spark学习实例3(Python):保存数据Save Data
- Spark学习实例4(Python):RDD转换 Transformations
- Spark学习实例5(Python):RDD执行 Actions
- Spark学习实例6(Python):共享变量Shared Variables
- Spark学习实例7(Python):RDD、DataFrame、DataSet相互转换
- Spark学习实例8(Python):输入源实时处理 Input Sources Streaming
- Spark学习实例9(Python):窗口操作 Window Operations