各大CNN网络结构汇总之LeNet-5篇
一、CNN 卷积神经网络
是一种深度学习的多层前馈神经网络,受生物自然视觉认知机制(动物视觉皮层细胞负责检测光学信号)启发而来,利用人工神经元(卷积核)响应输入的局部范围,常用于图像处理。
一般神经网络VS卷积神经网络:
相同点:卷积神经网络的训练过程也是使用一种反向传播算法(BP)
不同点:网络结构不同。卷积神经网络的网络连接具有局部连接、参数共享的特点。
局部连接:相对于全连接而言的,当前层的任意节点只与上一层的部分节点相连。
参数共享:是指两层的一些相连节点共享同一组参数,而不是每条连接都独有一个参数(同层共享卷积核的)。
参数个数:
在前层有n个节点,后层有m个节点的情况下。
全连接:m*n+m个参数。
CNN局部链接:i+1个参数, i 为卷积核内的参数数量。
二、LeNet-5
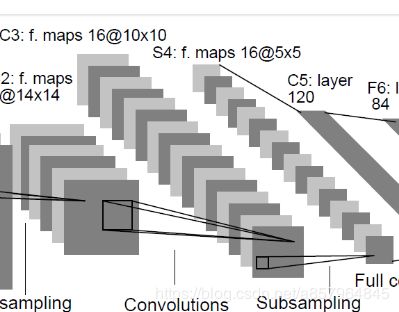
LeNet-5出自论文Gradient-Based Learning Applied to Document Recognition,是一种用于MNIST手写体字符识别的非常高效的卷积神经网络。Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。其网络结构如下
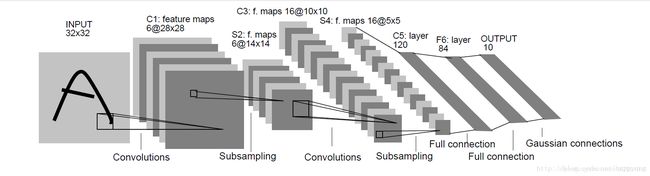
LeNet-5共有7层,不包含输入层,卷积层C1,下采样层S2,卷积层C3,下采样层S4,卷积层C5(全连接层),全连接层F6,全连接层Output。
卷积后输出层矩阵宽度的计算:
Outlength= (inlength-fileterlength+2*padding)/stridelength+1
Outlength:输出层矩阵的宽度
Inlength:输入层矩阵的宽度
Padding:补0的圈数(非必要)
Stridelength:步长,即过滤器每隔几步计算一次结果
C1层-卷积层
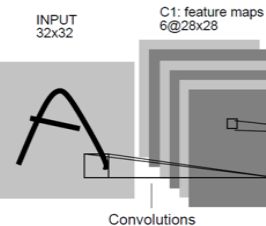
输入:32x32x1 (图片大小为32x32,单通道黑白图像)
卷积核:5x5x6 (大小为5x5,个数为6)
padding类型: VAILD
输出:28x28x6 ( (32-5+1)x(32-5+1)x6 每个卷积核会卷积出一张特征图 )
激活函数:sigmoid
可训练参数:(5x5+1)x6=156(每个卷积核 5x5=25个参数和一个bias参数,一共6个卷积核)
连接数:(5x5+1)x6x28x28=122304 (连接数远远小于训练参数的原因是参数共享机制)
S2层-下采样层
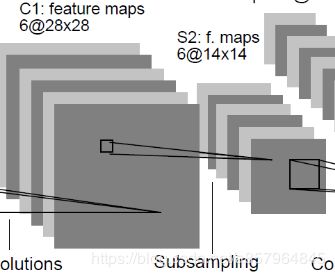
输入:28x28x6 (输入的特征图大小为28x28,有6层)
采样区域大小:2x2
原理:利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息
输出:14x14x6 (28/2) x (28/2) x 输入层数6
可训练参数:0 下采样层无训练参数 按照采样区域内的平均值或最大值采样
连接数:(2x2+1)x14x14*6=5880
C3层-卷积层
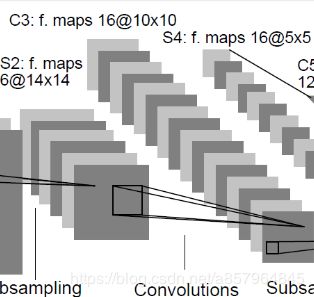
输入:14x14x6 (特征图大小为14x14, 有6层)
卷积核:5x5x16 (大小为5x5,个数为16)
padding类型: VAILD
激活函数:sigmoid
输出:10x10x16 (14-5+1)x(14-5+1)x16
可训练参数:C3层输出16个的图,每个图与S2层的连接的方式如下表 所示。
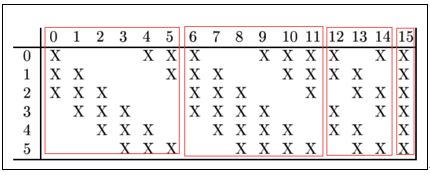
故可训练参数的个数为:6*(355+1)+6*(455+1)+3*(455+1)+1*(655+1)=1516
连接数:10101516=151600 (连接数远远小于训练参数的原因是参数共享机制)
S4层-下采样层
输入:10x10x16 (输入的特征图大小为10x10,有16层)
采样区域大小:2x2
原理:利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息
输出:5x5x16 (10/2) x (10/2) x 输入层数16
可训练参数:0 下采样层无训练参数 按照采样区域内的平均值或最大值采样
连接数:16*(2*2+1)55=2000
F5层-全连接层 (卷积层)
本层实际上是卷积操作,但也可以看作全连接的输入层
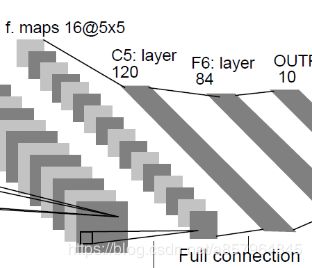
输入:5x5x16 (特征图大小为5x5, 有16层)
卷积核:5x5x120 (大小为5x5,个数为120)
padding类型: VAILD
激活函数:sigmoid
输出: 先得到 1x1x120 (5-5+1)x(5-5+1)x120
再展开成一维 120
可训练参数:120*(1655+1)=48120
连接数:120*(1655+1)=48120 (连接数恰好等于可训练参数的原因是输入图恰好等于卷积核大小,卷积步数在此时为1。)
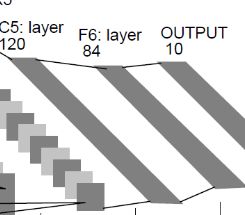
F6层-全连接层
输入: 120 维向量 (RANK=1 是个一阶向量)
计算方式:输入向量 点积 权重向量 加上 偏置值
激活函数:sigmoid
输出: 84维向量
可训练参数:84x(120+1)=10164 (+1是每维输出的偏置值)
F7层-输出层
输入: 84 维向量 (分别对应10类的得分)
计算方式:采用径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
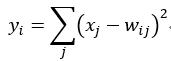
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到84-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。
其实就是10类的模板匹配,当前84维向量和哪个类别模板最接近就属于哪个类。
输出: 类别
可训练参数:10x(84)=840 (+1是每维输出的偏置值)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import time
# 声明输入图片数据,类别
x = tf.placeholder('float', [None, 784])
y_ = tf.placeholder('float', [None, 10])
# 输入图片数据转化
x_image = tf.reshape(x, [-1, 28, 28, 1])
#第一层卷积层,初始化卷积核参数、偏置值,该卷积层5*5大小,一个通道,共有6个不同卷积核
filter1 = tf.Variable(tf.truncated_normal([5, 5, 1, 6]))
bias1 = tf.Variable(tf.truncated_normal([6]))
conv1 = tf.nn.conv2d(x_image, filter1, strides=[1, 1, 1, 1], padding='SAME')
h_conv1 = tf.nn.sigmoid(conv1 + bias1)
print(conv1)
maxPool2 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')
print(maxPool2)
filter2 = tf.Variable(tf.truncated_normal([5, 5, 6, 16]))
bias2 = tf.Variable(tf.truncated_normal([16]))
conv2 = tf.nn.conv2d(maxPool2, filter2, strides=[1, 1, 1, 1], padding='VALID')
print(conv2)
h_conv2 = tf.nn.sigmoid(conv2 + bias2)
maxPool3 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')
print(maxPool3)
filter3 = tf.Variable(tf.truncated_normal([5, 5, 16, 120]))
bias3 = tf.Variable(tf.truncated_normal([120]))
conv3 = tf.nn.conv2d(maxPool3, filter3, strides=[1, 1, 1, 1], padding='VALID')
print(conv3)
h_conv3 = tf.nn.sigmoid(conv3 + bias3)
# 全连接层
# 权值参数
W_fc1 = tf.Variable(tf.truncated_normal([1* 1* 120, 84]))
# 偏置值
b_fc1 = tf.Variable(tf.truncated_normal([84]))
# 将卷积的产出展开
h_pool2_flat = tf.reshape(h_conv3, [-1, 1 * 1 * 120])
# 神经网络计算,并添加sigmoid激活函数
h_fc1 = tf.nn.sigmoid(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# 输出层,使用softmax进行多分类
W_fc2 = tf.Variable(tf.truncated_normal([84, 10]))
b_fc2 = tf.Variable(tf.truncated_normal([10]))
y_conv = tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2)
# 损失函数
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
# 使用GDO优化算法来调整参数
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(cross_entropy)
sess = tf.InteractiveSession()
# 测试正确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# 所有变量进行初始化
sess.run(tf.initialize_all_variables())
# 获取mnist数据
mnist_data_set = input_data.read_data_sets('MNIST_data', one_hot=True)
# 进行训练
start_time = time.time()
for i in range(20000):
# 获取训练数据
batch_xs, batch_ys = mnist_data_set.train.next_batch(200)
# 每迭代100个 batch,对当前训练数据进行测试,输出当前预测准确率
if i % 2 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch_xs, y_: batch_ys})
print("step %d, training accuracy %g" % (i, train_accuracy))
# 计算间隔时间
end_time = time.time()
print('time: ', (end_time - start_time))
start_time = end_time
# 训练数据
train_step.run(feed_dict={x: batch_xs, y_: batch_ys})
# 关闭会话
sess.close()