mysql高可用架构之MHA
MHA原理:
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性
MHA切换步骤:
1.从宕机的master中保存二进制文件
2.检测含有最新日至更新的slave
3.应用差异的中继日至(relay log)到其他的slave
4.应用从master中保存的二进制日至事件到其他的slave中
5.提升一个slave为master
6.使其他的slave指向最新的master进行复制。
manager的工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
node的工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
MHA的环境(基于主从复制或者半复制)
Master server2
Slave server1 server3
Mah-manager server1
1.master的配置
server2:
mysql> grant replication slave on *.* to repl@'172.25.24.%' identified by 'Westos+007'; ##加权
Query OK, 0 rows affected, 1 warning (0.35 sec)
mysql> reset master;
Query OK, 0 rows affected (0.22 sec)
mysql> create database westos;
Query OK, 1 row affected (0.34 sec)2.slave的配置
server1:
mysql> change master to master_host='172.25.24.2',master_user='repl',master_password='Westos+007',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.64 sec)
mysql> stop slave;
Query OK, 0 rows affected (0.33 sec)
mysql> reset slave;
Query OK, 0 rows affected (0.20 sec)
mysql> start slave;
Query OK, 0 rows affected (0.18 sec)
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| westos |
+--------------------+
5 rows in set (0.00 sec)server3:
mysql> change master to master_host='172.25.24.2',master_user='repl',master_password='Westos+007',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.35 sec)
mysql> start slave;
Query OK, 0 rows affected (0.08 sec)
mysql> show slave status\G
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| westos |
+--------------------+
5 rows in set (0.00 sec)3.配置Mah-manager
server1:安装管理服务
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56-0.el6.noarch.rpm
perl-Config-Tiny-2.12-7.1.el6.noarch.rpm
perl-Email-Date-Format-1.002-5.el6.noarch.rpm
perl-Log-Dispatch-2.27-1.el6.noarch.rpm
perl-Mail-Sender-0.8.16-3.el6.noarch.rpm
perl-Mail-Sendmail-0.79-12.el6.noarch.rpm
perl-MIME-Lite-3.027-2.el6.noarch.rpm
perl-MIME-Types-1.28-2.el6.noarch.rpm
perl-Parallel-ForkManager-0.7.9-1.el6.noarch.rpm[root@server1 mnt]# yum install *.rpm -yserver2 和server3 安装节点服务
[root@server2 mnt]# ls
mha4mysql-node-0.56-0.el6.noarch.rpm
[root@server2 mnt]# yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y
[root@server3 ~]# cd /mnt/
[root@server3 mnt]# ls
mha4mysql-node-0.56-0.el6.noarch.rpm
[root@server3 mnt]# yum install -y mha4mysql-node-0.56-0.el6.noarch.rpm4.添加配置文件
[root@server1 mnt]# mkdir -p /etc/masterha
[root@server1 mnt]# cd /etc/masterha/
[root@server1 masterha]# vim app1.cnf
[root@server1 masterha]# cat app1.cnf
[server default]
manager_workdir=/etc/masterha
manager_log=/etc/masterha/app1.log
master_binlog_dir=/var/lib/mysql
#master_ip_failover_script= /usr/local/bin/master_ip_failover
#master_ip_online_change_script= /usr/local/bin/master_ip_online_change
password=Westos+007
user=root
ping_interval=1
remote_workdir=/tmp
repl_password=Westos+007
repl_user=repl
#report_script=/usr/local/send_report
#secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02
#shutdown_script=""
ssh_user=root
[server1]
hostname=172.25.24.1
port=3306
[server2]
hostname=172.25.24.2
port=3306
#candidate_master=1
#check_repl_delay=05.装载ssh免密服务
[root@server1 mnt]# ssh-keygen -t rsa
[root@server1 mnt]# ssh-copy-id 172.25.24.1
[root@server1 mnt]# ssh-copy-id 172.25.24.2
[root@server1 mnt]# ssh-copy-id 172.25.24.3
所有的机器全部设置为好6.添加脚本
[root@server1 mnt]# vim master_ip_failover 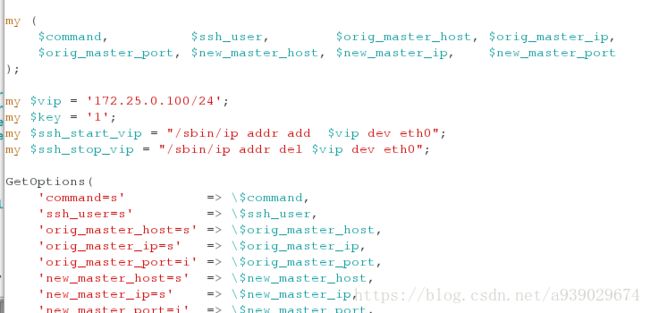
[root@server1 mnt]# vim master_ip_online_change 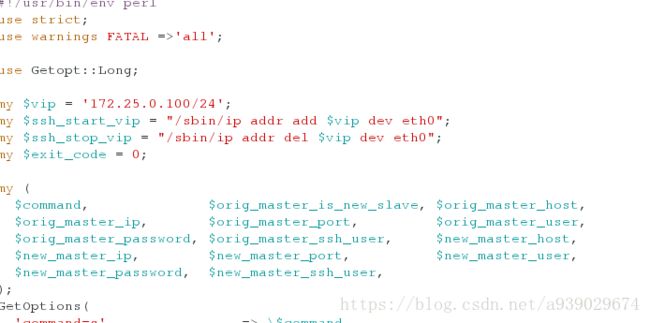
[root@server1 mnt]# mv master_ip_* /usr/local/bin/
[root@server1 mnt]# cd /usr/local/bin/
[root@server1 bin]# ls
master_ip_failover master_ip_online_change
[root@server1 bin]# chmod +x *
[root@server1 bin]# ls
master_ip_failover master_ip_online_change
[root@server1 bin]# vim /etc/masterha/app1.cnf ##开启脚本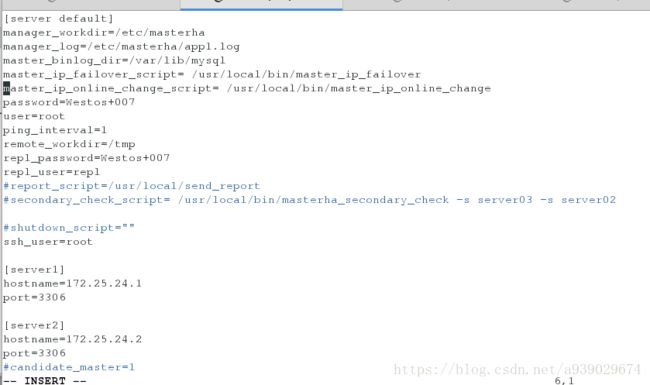
测试:
[root@server2 mnt]# ip addr add 172.25.24.100/24 dev eth0打入后台(mhm):
[root@server1 bin]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover &
[1] 2912
[root@server1 bin]# nohup: ignoring input and appending output to `nohup.ou关闭服务
Server2(master):
[root@server2 mnt]# ps ax
[root@server2 mnt]# kill -9 2318
[root@server2 mnt]# kill -9 2611server3: ##切换到server1
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.25.24.1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000001
Read_Master_Log_Pos: 986
Relay_Log_File: server3-relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 986
Relay_Log_Space: 614
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 0fbe268f-9d07-11e8-afd6-525400b9dbc1
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 0fbe268f-9d07-11e8-afd6-525400b9dbc1:1-2,
27a31d9e-9d07-11e8-b133-52540022235b:1
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Server1: VIP加入到了server1
mysql> show slave status;
Empty set (0.00 sec)
mysql> quit
Bye
[1]+ Done nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover
[root@server1 bin]# ip addr
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:b9:db:c1 brd ff:ff:ff:ff:ff:ff
inet 172.25.24.1/24 brd 172.25.24.255 scope global eth0
inet 172.25.0.100/24 scope global eth0
inet6 fe80::5054:ff:feb9:dbc1/64 scope link
valid_lft forever preferred_lft forever
物理机(客户端):
Database changed
MySQL [westos]> select * from userlist;
+----------+----------+
| username | password |
+----------+----------+
| user2 | 12345 |
| user3 | 3333 |
| user4 | 4444 |
+----------+----------+
3 rows in set (0.00 sec)
MySQL [westos]> insert into userlist values ('uwer5','555');
Query OK, 1 row affected (0.36 sec)
MySQL [westos]> insert into userlist values ('uwer6','666');
Query OK, 1 row affected (0.39 sec)
MySQL [westos]> server1测试:
mysql> use westos
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from userlist;
+----------+----------+
| username | password |
+----------+----------+
| user2 | 12345 |
| user3 | 3333 |
| user4 | 4444 |
| uwer5 | 555 |
| uwer6 | 666 |
+----------+----------+
5 rows in set (0.00 sec)
mysql>