深度学习---卷积神经网络+tensorflow实现
开了个新坑,想写很久了,就是一直没有整块的时间,今天终于。。。来来来,小手动起来~
磨刀不误砍柴工,先去复习一下传统的神经网络,https://blog.csdn.net/aBIT_Tu/article/details/82456016
目录
一、卷积 (Convolution)和它的小伙伴们
1. 卷积是谁
2. 好朋友padding
3. 好朋友Stride
4. 遇见漂亮的彩色小姐姐
5.我们的特色:局部连接,参数共享
二、池化(Poolong)
三、卷积神经网络(CNN)和实现
一、卷积 (Convolution)和它的小伙伴们
1. 卷积是谁
卷积运算是卷积神经网络的灵魂操作,卷积便于提取图像特征是促使卷积神经网络适合处理图像的关键所在。
通过一张图来了解一下什么是卷积操作,(图来自网络,侵删)
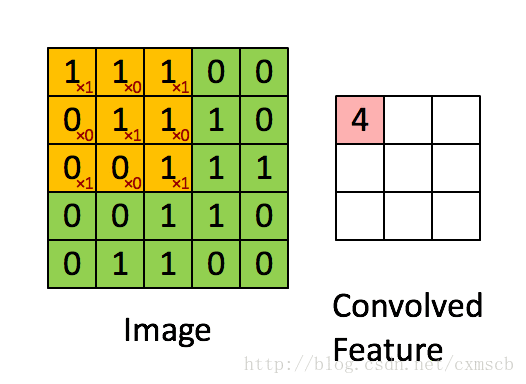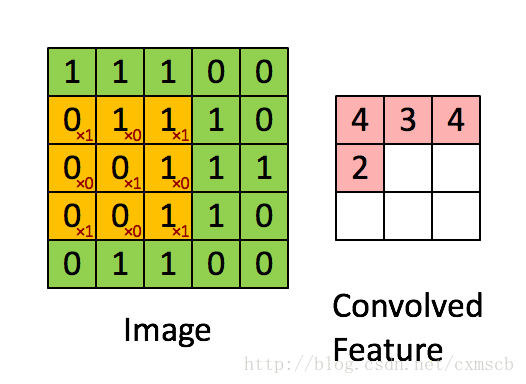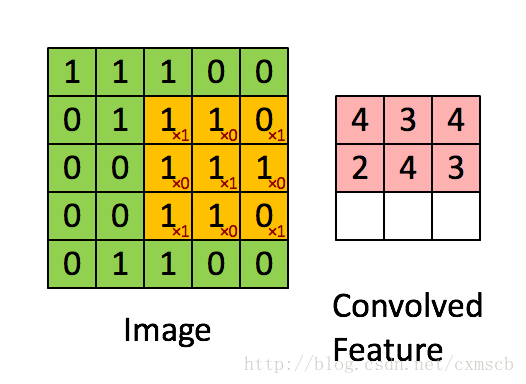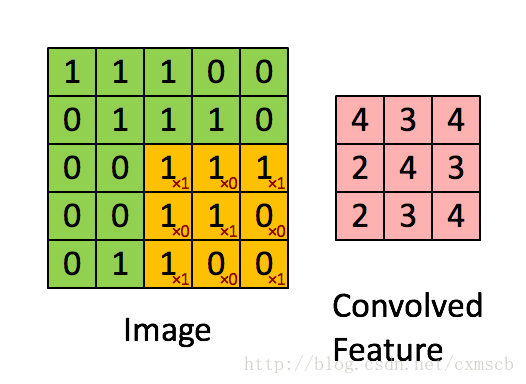
左侧绿色的矩阵是一个图像矩阵,每一个数值代表一个像素点的灰度值(如果是彩色图像就有RGB 3 个这样大小的矩阵);不断在移动的黄色矩阵称为卷积核(kernel),其实就是一个权重矩阵;被卷积核覆盖到的绿色区域叫做感受野(local receptive fields);粉色的矩阵是卷积运算得到的特征映射图(feature map ),每一个小格子叫做特征映射单元。
从数学角度看,卷积其实就是一种矩阵点乘(dot product)运算。试着运算一下,以下图为例,
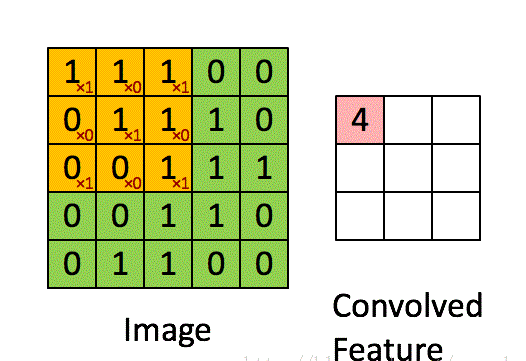
一次卷积运算的过程为:![]()
可是为什么卷积操作就可以提取到图像的特征呢?隔壁你王叔不服,
借助吴恩达老师的图片讲解一下,
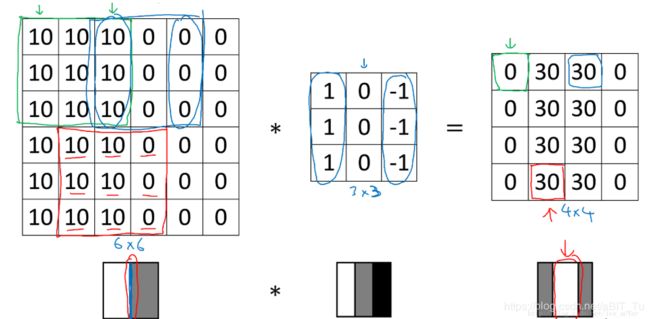
最左侧的图片是一个有着黑白分界的输入图像,现在我们希望检测一下它是否有竖直的边缘特征,选用中间这个矩阵作为我们的卷积核,一通操作之后,发现最右侧的矩阵只有中间两列数值非零,可视化为中间的为白色,这就说明输入图像拥有竖直的边缘且位于中间位置。
一个特定的卷积可以关注图片中某一些特定的特征,遇到了以后就会紧紧抓住它的手,这大概就是爱情吧,例如,水平边缘检测的卷积核,
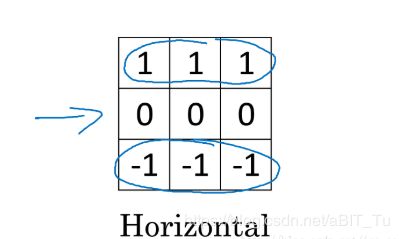 当然了,在CNN中卷积核的数值是需要根据目的被训练的,这就是命运(BP)的指引,哈哈哈。。。可以推荐一个一本正经写*文来解释这个原因的博客,https://blog.csdn.net/lcy7289786/article/details/68958662
当然了,在CNN中卷积核的数值是需要根据目的被训练的,这就是命运(BP)的指引,哈哈哈。。。可以推荐一个一本正经写*文来解释这个原因的博客,https://blog.csdn.net/lcy7289786/article/details/68958662
2. 好朋友padding
当我们了解了什么是卷积操作后,有没有发现,如果一直对一副图像进行卷积它会变得越来越小越来越小,直到变成柯南,那我们怎么样进行深层的训练呢?这时侯就需要卷积的好朋友服部平次,啊不,padding救场,padding 是一种填充0操作,
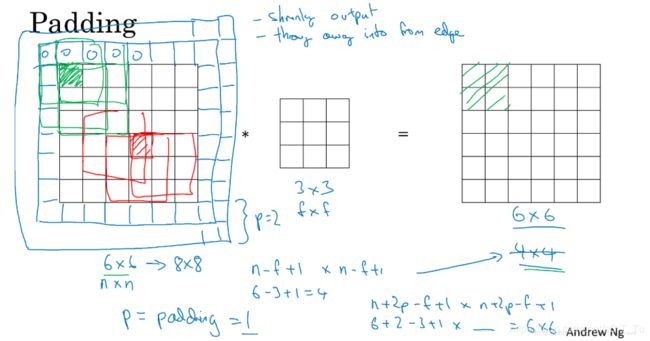
在原图像四周填充上p圈0元素,再进行卷积操作,就可以缓解这个问题,同时使得图像边缘的信息不再容易被卷积核忽略掉。 padding也有懒有勤,(1)对于填充好后,特征图与原图像一样大小的叫做same, ![]() ,
,![]() 是卷积核的大小,所以卷积核的大小经常是奇数的;(2)
是卷积核的大小,所以卷积核的大小经常是奇数的;(2)![]() 的padding ,叫做valid (no padding),特征矩阵的大小为
的padding ,叫做valid (no padding),特征矩阵的大小为![]() ,
, ![]() 是原图像的大小。
是原图像的大小。
3. 好朋友Stride
走路要靠脚,出门靠朋友,hello大家好,我是你们的朋友stride,主要负责卷积核的滑动距离,之前你们看到的都是我为1的时候,是时候展示真正的魅力了,当我为2时,
(1)第一次卷积
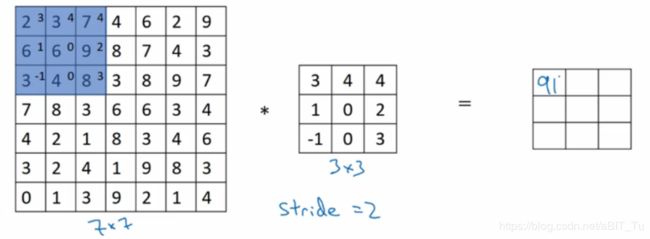
(2)第二次卷积
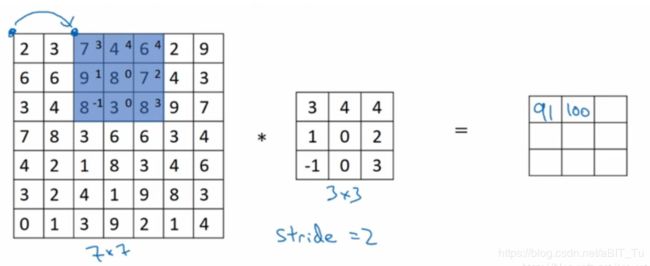
(3)第三次卷积
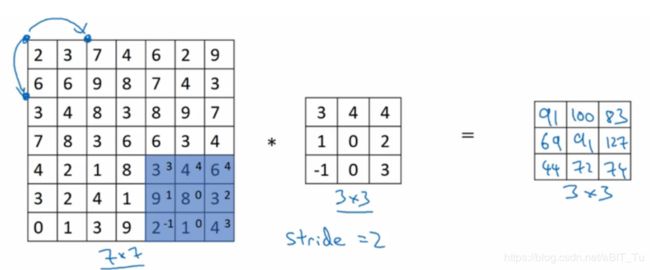
有了我以后就可以控制卷积核在输入图像上进行滑动,不同的步长得到的特征映射矩阵也不一样大,设![]()
特征映射图大小为![]()
![]()
4. 遇见漂亮的彩色小姐姐
色彩是丰富美丽的,卷积核也有自己的了解色彩一套,
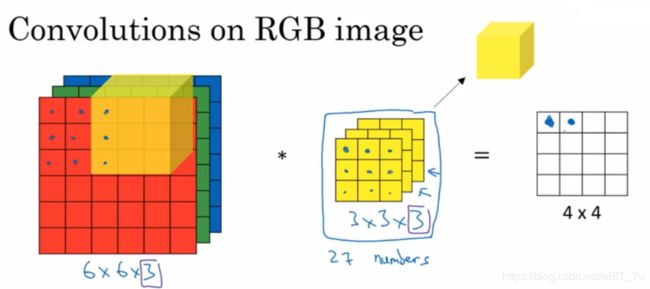
当遇见彩色图片(RGB)的时候卷积核就对应成![]() 的卷积核,最后一个3就是对彩色小姐姐的基本尊重,对应于RGB3个通道(channel),卷积运算时只需要将3个通道的运算结果进行累加,就又可以得到一个特征映射图。
的卷积核,最后一个3就是对彩色小姐姐的基本尊重,对应于RGB3个通道(channel),卷积运算时只需要将3个通道的运算结果进行累加,就又可以得到一个特征映射图。
漂亮的东西只有一个卷积核来欣赏肯定是不够的,各类卷积核都会拿着铲子锄头跑来,多卷积核的情况是怎么样的呢,
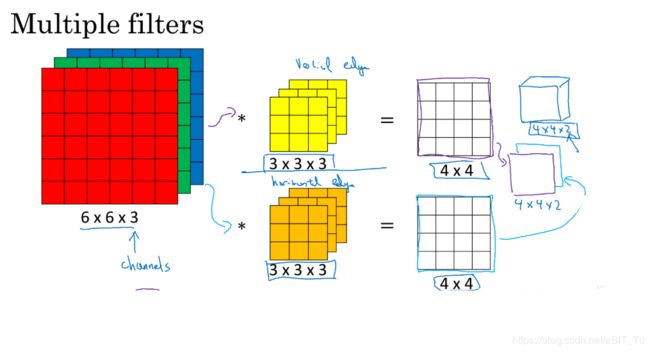
有m个卷积核,每个卷积核都来滑一遍RGB图像,得到了不同的特征映射矩阵,这些矩阵通通被保留下来得到了*m这样的立方体,形象的来看就是图片的长宽变小,厚度变大,像不像拿个放大镜扫了一遍。、

5.我们的特色:局部连接,参数共享
(1)局部连接(local field):每个隐含单元仅仅只能连接输入单元的一部分(每一次只是对符合卷积核的图像像素做卷积)。例如,每个隐含单元仅仅连接输入图像的一小片相邻区域。通过局部连接的方式避免了参数的爆炸式增长(对比全连接的方式). 通过下面的参数共享可以大大的缩减实际的参数量,为训练一个多层的CNN提供了可能。
(2)参数共享(Parameter Sharing):我们把同一深度的平面叫做深度切片(depth slice),同一个切片共享同一组权重和偏置。权重共享的意义在于:一方面,相同的权重能够对一类特征进行识别,而不考虑它在可视域中的位置。另一方面,权值共享极大的减少了需要学习的自由变量的个数,使得我们能更有效的进行特征抽取。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化能力。
更多的可以参考,https://blog.csdn.net/Gavin__Zhou/article/details/72723494,是卷积部分的延展。
二、池化(Poolong)
池化也叫做下采样(subsampling),进一步对卷积得到的feature map进行降维,减少参数,提高运算效率,防止过拟合。
实际操作中池化也是一种卷积运算,池化最常见的分为两类:
1. 最大池化(Max pooling):取最大池化卷积核覆盖下的feature map上的最大值。例如,s=2时
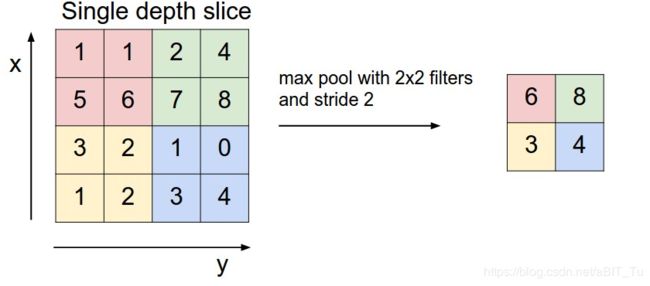
2. 平均池化(Average pooling):取平均池化卷积核覆盖下的feature map上的平均值。类似。
三、卷积神经网络(CNN)和实现
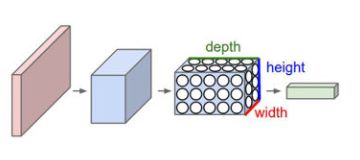
左侧是传统的神经网络,右侧是CNN网络,可以首先直观感受到的是CNN将图像变厚了,长宽变小了,其实这就是提取图片特征的过程。

比较流行的一种搭建结构是输入图片(image)、经过一层卷积层 (convolution)、池化(pooling)方式处理卷积的信息、重复几次同样的处理,把得到的第二次处理的信息传入两层全连接的神经层 (fully connected),最后接上一个分类器(classifier)进行分类预测。例如,
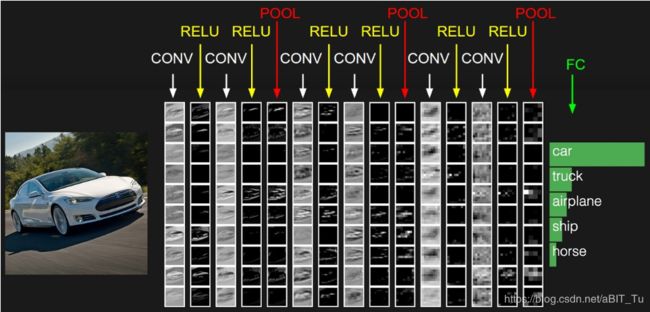
具体的,为了更细致的感受CNN的运作方式,我们借用http://xilinx.eetrend.com/article/10827中的图,画的确实太好了,

以上是一个图像分类的CNN网络结构,由:输入层、卷积层、池化层,(光栅化),全连接层,输出组成。
从输入层到第一个池化层结束是,
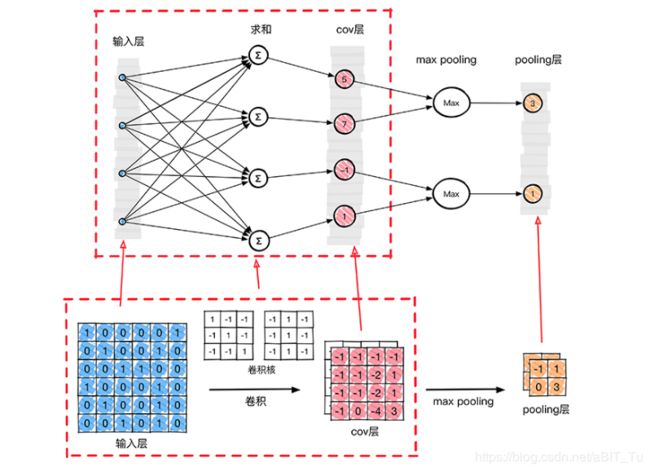
在每一个神经单元传播过程中仍旧遵守传统神经网络的规律,

基本上CNN就可以动手实现了,这里先放一个https://blog.csdn.net/program_developer/article/details/80369989中的代码,这个代码相对比较完整。后期会再上传一个简单实现的代码。
#coding:utf-8
# 导入本次需要的模块
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
def compute_accuracy(v_xs,v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs:v_xs, keep_prob:1})
correct_prediction = tf.equal(tf.argmax(y_pre, 1),tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs:v_xs,ys:v_ys,keep_prob:1})
return result
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
# stride[1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] =1
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding="SAME") # padding="SAME"用零填充边界
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME")
# #################处理图片##################################
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None,784]) # 28*28
ys = tf.placeholder(tf.float32, [None,10])
# 定义dropout的输入,解决过拟合问题
keep_prob = tf.placeholder(tf.float32)
# 处理xs,把xs的形状变成[-1,28,28,1]
# -1代表先不考虑输入的图片例子多少这个维度。
# 后面的1是channel的数量,因为我们输入的图片是黑白的,因此channel是1。如果是RGB图像,那么channel就是3.
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# print(x_image.shape) #[n_samples, 28,28,1]
# #################处理图片##################################
## convl layer ##
W_conv1 = weight_variable([5,5,1,32]) # kernel 5*5, channel is 1, out size 32
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1) # output size 28*28*32
h_pool1 = max_pool_2x2(h_conv1) # output size 14*14*32
## conv2 layer ##
W_conv2 = weight_variable([5,5,32,64]) # kernel 5*5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2) # output size 14*14*64
h_pool2 = max_pool_2x2(h_conv2) # output size 7*7*64
## funcl layer ##
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
# [n_samples,7,7,64]->>[n_samples, 7*7*64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
## func2 layer ##
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
# #################优化神经网络##################################
# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1])) #loss
train_step = tf.train.GradientDescentOptimizer(1e-4).minimize(cross_entropy)
# train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess =tf.Session()
# important step
sess.run(tf.initialize_all_variables())
# #################优化神经网络##################################
for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs:batch_xs,ys:batch_ys, keep_prob:0.5})
if i % 50 ==0:
# print(sess.run(prediction,feed_dict={xs:batch_xs}))
print(compute_accuracy(mnist.test.images,mnist.test.labels))相关链接:
【1】win10下python3.6+Anaconda3+tensorflow安装 https://blog.csdn.net/aBIT_Tu/article/details/88351644
【2】配置pycharm下的tensorflow环境 https://blog.csdn.net/aBIT_Tu/article/details/88363134