storm整合hdfs—将数据写到hdfs
最近由于业务需求,需要将数据经过storm实时处理加工之后,要转存到HDFS。小厨在实现业务之前首先写了一个测试用例,话不多说,直接上干货。。。
首先介绍一下用例业务中使用的软件版本:storm 1.1.0、 hadoop 2.6.5、zookeeper3.4.10;使用maven构建项目。再简单的介绍一下测试用例业务场景:发送手机名称,即通过产生随机数的方式在数组中源源不断的选取要发送的手机信号,通过两个Bolt之后将手机型号变换成大写并添加时间后缀,最后通过hdfsBolt将数据写到hdfs文件中。
pom.xml文件添加
本文只给出添加dependency依赖包代码
junit
junit
4.12
test
org.apache.storm
storm-core
1.1.0
org.apache.hadoop
hadoop-common
2.6.5
org.apache.hadoop
hadoop-hdfs
2.6.5
org.apache.hadoop
hadoop-client
2.6.5
org.apache.storm
storm-hdfs
1.1.0
org.apache.hadoop
hadoop-client
org.apache.hadoop
hadoop-hdfs
整合代码1:编写spout逻辑,不断发送消息给下一级bolt
package com.bigdata;
import java.util.Map;
import java.util.Random;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
/**
* spout组件是整个topology的源组件
* 读取数据源
* @author xiaxing
*
*/
public class phoneSpout extends BaseRichSpout{
//声明一个成员变量 将open里面的SpoutOutputCollector对象的发送方法 能传递给nextTuple()方法使用
private SpoutOutputCollector collect ;
//模拟数据
String[] phones = {"iphone","xiaomi","sumsun","huawei","matepd","motopd","chuizi","oppopd","vivopd"};
/**
* 消息的处理方法 不断的往后续流程发送消息 调用一次发送一个消息脱了
* 会连续不断的被worker进程的executor线程调用
*/
public void nextTuple() {
// TODO Auto-generated method stub
int index = new Random().nextInt(phones.length);
String phone = phones[index];
//通过emit方法将phone发送出去
collect.emit(new Values(phone));
System.out.println("phone-name: "+phone);
Utils.sleep(1000);
}
/**
* open方法是组件的初始化方法。类似于MapReduce里面的mapper里面的setup方法
*/
public void open(Map config, TopologyContext context, SpoutOutputCollector collect) {
// TODO Auto-generated method stub
this.collect = collect;
}
/**
* 声明定义本组件发出的tuple的schema
* 即发送的几个字段 每段字段的名称
*/
public void declareOutputFields(OutputFieldsDeclarer declare) {
// TODO Auto-generated method stub
declare.declare(new Fields("phone-name"));
}
}
整合代码2:编写upperBolt逻辑
package com.bigdata;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 将spout发过来的手机名称转为大写
* @author xiaxing
*
*/
public class UpperBolt extends BaseRichBolt{
private OutputCollector collect;
/**
* 是bolt组件的业务处理方法 不断地被worker的executor线程调用
* 没收到一个消息tuple 就会调用一次
* Tuple tuple 上一个组件发过来的消息
* BasicOutputCollector collect 用来发送数据
*/
public void execute(Tuple tuple) {
// TODO Auto-generated method stub
String phone = tuple.getStringByField("phone-name");
//添加业务逻辑
String upperCasePhone = phone.toUpperCase();
//封装消息发送
collect.emit(new Values(upperCasePhone));
}
public void prepare(Map config, TopologyContext context, OutputCollector collect) {
// TODO Auto-generated method stub
this.collect = collect;
}
public void declareOutputFields(OutputFieldsDeclarer declare) {
// TODO Auto-generated method stub
declare.declare(new Fields("upper-phone-name"));
}
}
整合代码3:编写suffix逻辑,添加时间后缀
package com.bigdata;
import java.text.SimpleDateFormat;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 接收上一级bolt在phone-name添加格式化日期后缀
* @author xiaxing
*
*/
public class SuffixBolt extends BaseRichBolt{
private OutputCollector collector;
//创建一个时间对象
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//声明一个成员变量 调用emit方法
public void execute(Tuple tuple) {
// TODO Auto-generated method stub
String upperName = tuple.getStringByField("upper-phone-name");
//业务处理, 把upperName 加上日期后缀
String result = upperName + "is "+df.format(System.currentTimeMillis());
collector.emit(new Values(result));
}
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this.collector = collector;
}
//声明
public void declareOutputFields(OutputFieldsDeclarer declare) {
// TODO Auto-generated method stub
declare.declare(new Fields("final"));
}
}
整合代码4:编写submitter逻辑,main方法入口,编写hdfsbolt的配置、业务逻辑以及整个Topo的配置
package com.bigdata;
import org.apache.storm.hdfs.bolt.HdfsBolt;
import org.apache.storm.hdfs.bolt.format.DefaultFileNameFormat;
import org.apache.storm.hdfs.bolt.format.DelimitedRecordFormat;
import org.apache.storm.hdfs.bolt.format.FileNameFormat;
import org.apache.storm.hdfs.bolt.format.RecordFormat;
import org.apache.storm.hdfs.bolt.rotation.FileRotationPolicy;
import org.apache.storm.hdfs.bolt.rotation.FileSizeRotationPolicy;
import org.apache.storm.hdfs.bolt.sync.CountSyncPolicy;
import org.apache.storm.hdfs.bolt.sync.SyncPolicy;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
public class Submitter {
public static void main(String[] args) {
/**
* 定义出HDFS的Bolt
*/
//输出字段分隔符
RecordFormat format = new DelimitedRecordFormat().withFieldDelimiter("|");
//每10个tuple同步到HDFS上一次
SyncPolicy syncPolicy = new CountSyncPolicy(10);
//每个写出文件的大小为5M
FileRotationPolicy rotationPolicy = new FileSizeRotationPolicy(5.0f,FileSizeRotationPolicy.Units.MB);
//获取输出目录 从cli命令行上获取 此处使用本地测试,因此手动指定目录,集群将此换成args[0]即可。
FileNameFormat fileNameFormat = new DefaultFileNameFormat().withPath("/phoneStorm");
//执行HDFS地址,实测8020端口连接失败,9000端口可连接。可在hadoop中进行端口配置
HdfsBolt hdfsBolt = new HdfsBolt()
.withFsUrl("hdfs://192.168.83.131:9000")
.withFileNameFormat(fileNameFormat)
.withRecordFormat(format)
.withRotationPolicy(rotationPolicy)
.withSyncPolicy(syncPolicy);
//构建一个topo构建器
TopologyBuilder builder = new TopologyBuilder();
//指定topo所有的spout组件类
//参数1 spout的id 参数2 spout的实例对象 (并且可以设置并行度)
builder.setSpout("phone-spout", new phoneSpout());
//指定topo所用的第一个bolt组件,同时指定本bolt的消息流是从哪个组件流过来的
builder.setBolt("upper-bolt", new UpperBolt()).shuffleGrouping("phone-spout");
builder.setBolt("suffix-bolt", new SuffixBolt()).shuffleGrouping("upper-bolt");
builder.setBolt("hdfs-bolt", hdfsBolt).shuffleGrouping("suffix-bolt");
//使用builder来生成一个Topology的对象
StormTopology phoneTopo = builder.createTopology();
if(args.length > 0) {
try {
StormSubmitter.submitTopology("phoneTopology", new Config(), phoneTopo);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}else {
//本地测试
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("phone1-topo", new Config(), phoneTopo);
}
}
}
至此,所有的业务逻辑代码小厨都已倾情贴出,哈哈。下面的环节就是夏天小厨要为大家介绍怎么样做好集成storm和Hdfs这道菜以及做这道菜时应该要注意的点。
总结:
1、在将storm数据写到HDFS中时,要执行hadoop fs -chmod 777 /phoneStorm, 保证此文件能有RPC读写权限;
2、最终写到的hdfs文件名称是由创建HdfsBolt时Bolt的id决定,其准确的命名规则如下:默认使用提供的org.apache.storm.hdfs.format.DefaultFileNameFormat 将使用以下格式创建文件名:
{prefix}{componentId}-{taskId}-{rotationNum}-{timestamp}{extension}可通过实现FileNameFormat接口来控制文件的命名
public interface FileNameFormat extends Serializable {
void prepare(Map conf, TopologyContext topologyContext);
String getName(long rotation, long timeStamp);
String getPath();
}在本例中使用的是默认的DefaultFileNameFormat:“hdfs-bolt-2-XXXXXXXXX.txt”;
3、关于连接hdfs端口的问题,很多情况下RPC能够连接的端口是8020,但是有时候例如小厨设置的端口是9000,所以当出现hadoop connect refused 时 检查一下端口是否正确。可在hadoop的配置文件中找到。
结果分析:
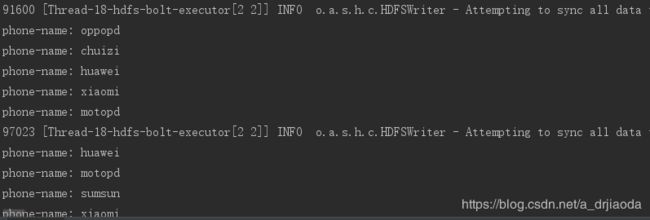
idea输出:向HDFS中写数据
去HDFS文件系统中即master:50070端口查看创建的目录,确保已经创建成功并且已经赋满权限。本例创建/phoneStorm

最终写到的hdfs文件名称是由其bolt id决定,本例使用hdfs-bolt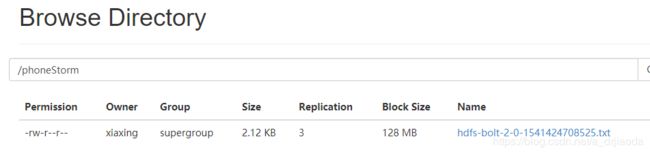
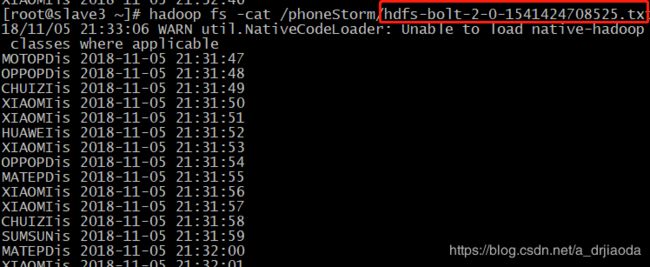
hadoop fs -cat 命令查看写入到hdfs文件的内容,cat出的内容符合我们预期。
至此,Happy ending
关于如何通过storm读取hdfs的数据,请看本博的下一篇文章《storm整合hdfs—从hdfs读取数据》