Storm-1.2.2介绍及完全分布式安装
目录
1 Storm是什么
2 Storm的核心概念
3 Storm原理架构
4 Storm集群安装部署
4.1 下载Storm 1.2.2
4.2 解压,更改配置文件
4.3 将配置好的节点分发到两个从节点上
5 启动storm集群及web监控
1 Storm是什么
Apache Storm是一个分布式的、可靠的、容错的实时数据流处理框架。Storm是Twitter开源的分布式实时大数据处理框架,最早开源于github,从0.9.1版本之后,归于Apache社区,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。

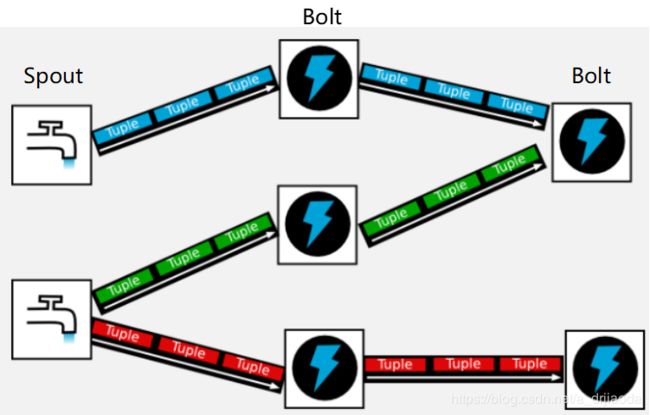
Storm的处理流程类似工业上的生产线,如上图,取水口就相当于Storm的数据源口Spout,经历一系列的处理阶段Bolt,最终送给用户(即数据落地),构成一个拓扑结构。
它与Spark Streaming的最大区别在于它是逐个处理流式数据事件,而Spark Streaming是微批次处理,因此,它比Spark Streaming更实时。但相比新的实时流处理框架Flink来说,Flink提供了DataSet 和 DataStream两个接口实现可批可流的处理机制,并且提供了Exactly-once语义,因此被越来越多的公司使用。如果非得给流处理框架排个序,小厨认为:Flink>Storm>Storm Trident>Spark Streaming。至于优先程度主要还得看具体的业务场景,例如某公司已经搭建了一个Spark平台,并且对数据的实时性可以接受为分钟级别,那么可能Spark Streaming是最适合的。
2 Storm的核心概念
- nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
- Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理其本身所有Worker,一个Supervisor节点中包含多个Worker进程。
- worker:工作进程,每个工作进程中都有多个Task。
- Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。
- Topology:DAG有向无环图的实现。计算拓扑,Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。
- Stream:从Spout中源源不断传递数据给Bolt、以及上一个Bolt传递数据给下一个Bolt,所形成的这些数据通道即叫做Stream。可以根据StreamId绑定上下游的Bolt.
- Tuple:Stream中最小数据组成单元。(如下图:多个Tuple构成一个Stream通道)

- Spout:数据源(Spout)是拓扑中数据流的来源。一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中。根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。一个可靠的 Spout 能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;相对应的,不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理。一个 Spout 可以发送多个数据流。
- Bolt:拓扑中所有的数据处理均是由 Bolt 完成的。通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求。一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
数据流处理图如下图所示:
3 Storm原理架构
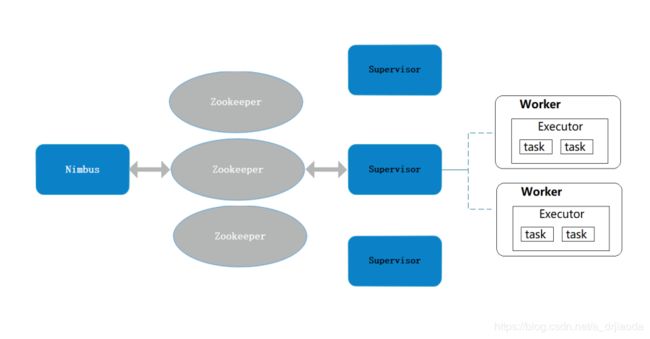
Storm架构图如上图所示。
整个结构非常类似于Hadoop的架构,其中
- Nimbus:主控节点,用于提交任务,负责资源分配和认为调度,相当于Hadoop的JobManager;
- Supervisor:接受Nimbus分配的任务,管理worker进程,相当于Hadoop的TaskManager;
- Zookeeper:协调,存放集群的公共数据(心跳、集群状态、配置信息等),Nimbus分配给supervisor的任务
Supervisor节点与Nimbus节点通信是依靠心跳机制,而Zookeeper对整个集群统一进行协调管理。Topo处理如下图所示:

4 Storm集群安装部署
主机信息如下表:
| 主机名 |
操作系统版本 |
IP地址 |
安装软件 |
| master |
Centos 6.5 |
192.168.83.131 |
JDK 1.8、 zookeeper-3.4.10、apache-storm-1.2.2 |
| slave1 |
Centos 6.5
|
192.168.83.130 |
JDK 1.8、 zookeeper-3.4.10、apache-storm-1.2.2
|
| slave3 |
Centos 6.5
|
192.168.83.133 |
JDK 1.8、 zookeeper-3.4.10、apache-storm-1.2.2
|
安装Storm之前首先保证之前安装的Zookeeper服务正常运行,包括配置hosts映射,主机名修改,防火墙都已经设置完好
4.1 下载Storm 1.2.2
http://storm.apache.org/downloads.html。保存到windows下之后,在linux系统中创建Storm目录,mkdir /usr/storm 使用Winscp传输到linux系统该文件夹内,如下:

4.2 解压,更改配置文件
Linux 系统下解压即安装: tar -zvxf apache-storm-1.2.2.tar.gz
![]()
切换到conf目录下,创建storm-local目录,更改storm.yaml文件。1、首先配置Zookeeper的主机名,也可用IP地址代替;2、指定Storm-Local的文件夹位置,Nimbus和Supervisor守护进程需要本地磁盘上的目录来存储少量状态(如jar,confs和类似的东西);3、用于配置主控节点的地址,可以配置多个;4、配置每个 Supervisor 机器能够运行的工作进程(worker)数。每个 worker 都需要一个单独的端口来接收消息。添加以下内容:
########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- "master"
- "slave1"
- "slave3"
#
storm.local.dir: "/usr/storm/apache-storm-1.2.2/storm-local"
nimbus.seeds: ["master"]
supervisor.slots.ports:
- 6701
- 6702
- 6703
- 6704
- 6705
- 6706更改完的配置文件如下图所示,此处设置了6个Slots端口,可根据实际情况设定。

本文省略了将Storm配置到环境变量一步,步骤很简单。vi /etc/profile 添加以下内容,再执行 source /etc/profile即可:
export STORM_HOME=/usr/storm/apache-storm-1.2.2/
export PATH=$PATH:$STORM_HOME/bin4.3 将配置好的节点分发到两个从节点上
scp -r /usr/storm/apache-storm-1.2.2/ root@slave1: /usr/storm
scp -r /usr/storm/apache-storm-1.2.2/ root@slave3: /usr/storm
5 启动storm集群及web监控
启动Storm集群之前,我们首先需要在三台虚机上启动ZooKeeper进程
cd /usr/zookeeper/zookeeper-3.4.10/bin
./zkServer.sh start在三台机器启动zookeeper进程之后,可以分别查看机器状态,./zkServer.sh status。至此,开始分别启动storm集群
启动nimbus进程在master机器上执行启动命令,两种方式:
- 前台启动:./storm nimbus 这种方式启动之后,进程信息会一直占用界面,从而导致需要重新开启窗口进行相关操作

- 后台启动:./storm nimbus 1>/dev/null 2>&1 这种启动方式所有的提示信息均在后台,用户不可直观看见,但是可以在本界面输入其他命令,进行集群操作。推荐此种方法

启动Supervisor进程,在两台slave机器上执行启动命令,方式也如nimbus启动一样
./storm supervisor
或者
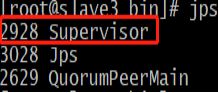
./storm supervisor 1>/dev/null 2>&1 &至此,nimbus和supervisor均已启动成功,可使用jps查看相关进程是否启动成功,本例查看slave3上的相关进程:
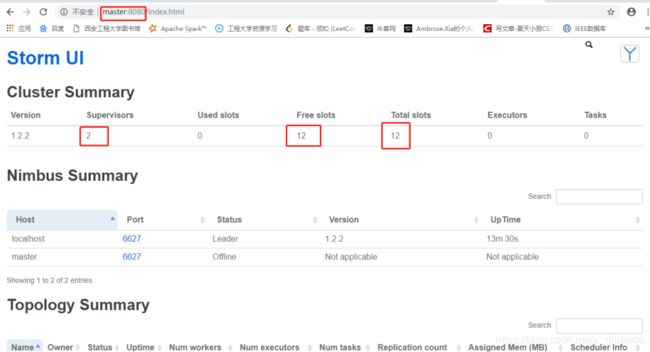
启动UI页面,进行相关监控,包括solts数量、目前正在运行的topo
在master节点上,输入以下命令,启动方式如nimbus:
./storm ui
或者
./storm ui 1>/dev/null 2>&1 &访问ui页面: master:8080/ 或者 192.168.83.131:8080
在master上查看相关进程,如下图:
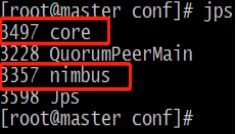
至此,storm集群已经搭建成功。