12月9日上午接到销售人员电话,说某客户的数据故障,业务都停了,让我去处理一下。急忙从公司赶往客户那边,好在离公司不太远,6站地铁就到了。到了客户那边,赶紧与那边的DBA简单地沟通了一下,了解到他们的库是运行在WINDOW 2008 标准版上的Oracle 11gR1,已经配置了DG,出问题的是主库,早上上班的时候发现业务系统无法连接到数据库,监听也hang死。
我到那边的时候,他们的DBA已经对库执行过了shutdown并重启过了,但是发现业务系统仍然无法正常使用,查看监听状态,并没有实例的服务被注册到监听,并且SQLPLUS连接数据库提示权限不足。查看后发现,原来是因为Windows上Oracle实例的服务没有启动(默认为手动启动方式),启动数据库后就能顺利进入SQLPLUS了,服务也被PMON进程注册到监听了。至此,业务系统其实也就正常了,能通过监听访问数据库了。
仅重启下数据库,无法访问数据库的问题就解决了?到底是什么原因造成的呢?通过分析alert日志,发现主要是再凌晨1点12分开始报error的:
Tue Dec 09 01:12:50 2014
kkjcre1p: unable to spawn jobq slave process
Errors in file d:\oracle\diag\rdbms\msa\msa\trace\msa_cjq0_5336.trc:
略…
Tue Dec 09 01:24:09 2014
Timed out trying to start process m001.
Tue Dec 09 01:26:14 2014
kkjcre1p: unable to spawn jobq slave process
Errors in file d:\oracle\diag\rdbms\msa\msa\trace\msa_cjq0_5336.trc:
略…
Tue Dec 09 01:39:27 2014
Timed out trying to start process m000.
Suspending MMON action 'DDE MMON action to schedule async action slaves' for 82800 seconds
略…
Tue Dec 09 08:47:55 2014
kkjcre1p: unable to spawn jobq slave process
Errors in file d:\oracle\diag\rdbms\msa\msa\trace\msa_cjq0_5336.trc:
Tue Dec 09 08:49:17 2014
Stopping background process SMCO
Tue Dec 09 08:49:48 2014
Background process SMCO not dead after 30 seconds
Killing background process SMCO
Stopping background process FBDA
Shutting down instance: further logons disabled
Stopping background process QMNC
Stopping background process MMNL
Stopping background process MMON
Shutting down instance (immediate)
License high water mark = 565
All dispatchers and shared servers shutdown
Tue Dec 09 08:49:58 2014
kkjcre1p: unable to spawn jobq slave process, slot 0, error 1089
Stopping background process CJQ0
Tue Dec 09 08:50:24 2014 --执行关闭数据库的时间
ALTER DATABASE CLOSE NORMAL
Tue Dec 09 08:50:24 2014
SMON: disabling tx recovery
SMON: disabling cache recovery
Tue Dec 09 08:50:25 2014
Shutting down archive processes
Archiving is disabled
Tue Dec 09 08:50:25 2014
ARCH shutting down
ARC2: Archival stopped
Tue Dec 09 08:50:25 2014
ARCH shutting down
Tue Dec 09 08:50:25 2014
ARCH shutting down
ARC1: Archival stopped
ARC3: Archival stopped
Thread 1 closed at log sequence 39723
Successful close of redo thread 1
Completed: ALTER DATABASE CLOSE NORMAL
ALTER DATABASE DISMOUNT
Completed: ALTER DATABASE DISMOUNT
ARCH: Archival disabled due to shutdown: 1089
Shutting down archive processes
Archiving is disabled
Archive process shutdown avoided: 0 active
ARCH: Archival disabled due to shutdown: 1089
Shutting down archive processes
Archiving is disabled
Archive process shutdown avoided: 0 active
Tue Dec 09 08:50:30 2014
Stopping background process VKTM:
System State dumped to trace file d:\oracle\diag\rdbms\msa\msa\trace\msa_ora_5912.trc
略…
Tue Dec 09 10:55:07 2014 --重新启动数据库的时间
Starting ORACLE instance (normal)
根据提示信息:kkjcre1p: unable to spawn jobq slave process ,可以了解到是系统无法生成job相关的进程而出错的,有几种可能:
1、参数job_queue_processes(设置过小)
2、参数session和processes(设置的会话数及连接数不能满足业务需求)
3、参数pga_aggregate_target(被耗尽)
4、OS资源被耗尽,如virtual memory
通常默认安装数据库,给的process值是150,而实际的业务环境可能需要的值远比这个要高。因此,需要调整该参数。通常还会伴随“ORA-00020: maximum number of processes (150) exceeded”的错误一起出现。重启数据库后,暂时也没有继续报该错误,所以暂时没有调整该参数。
由于重启数据库后故障基本已经解决,于是顺便诊断一下数据库,看看有没有什么其他方面的隐患。客户的数据库运行在Windows 2008标准版上,物理内存其实是64G,但是只能被识别到32G,浪费了32G!微软还挺坑爹的啊!


再看一下数据库内存分配情况,即使OS能用到32G内存,而MEMORY_MAX_TARGET和MEMORY_TARGET只给了6G,由于采用了11g的新特性AMM,那么自然SGA也最多只有6G了,而当SGA占用了全部分配的内存,PGA不就分配不到内存了么?于是对调整之前的2个参数值为10G,调整完的值如下:
SQL> set line 130
SQL> col component for a25
SQL> select component,current_size,max_size,user_specified_size from v$memory_dynamic_component
COMPONENT CURRENT_SIZE MAX_SIZE USER_SPECIFIED_SIZE
------------------------- ------------ ---------- -------------------
shared pool 2013265920 2013265920 0
large pool 67108864 67108864 0
java pool 402653184 402653184 0
streams pool 0 0 0
SGA Target 6710886400 6710886400 0
DEFAULT buffer cache 4093640704 4227858432 0
KEEP buffer cache 0 0 0
RECYCLE buffer cache 0 0 0
DEFAULT 2K buffer cache 0 0 0
DEFAULT 4K buffer cache 0 0 0
DEFAULT 8K buffer cache 0 0 0
DEFAULT 16K buffer cache 0 0 0
DEFAULT 32K buffer cache 0 0 0
Shared IO Pool 0 0 0
PGA Target 4026531840 4294967296 0
ASM Buffer Cache 0 0 0
16 rows selected.
SGA达到了6G左右,db buffer cache与shared pool的比值也差不多达到了2:1,PGA也分配到了4G左右
SQL> show parameter sga
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 10G
sga_target big integer 0
SQL> show parameter pga
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
_pga_max_size big integer 432520K
pga_aggregate_target big integer 0
SQL> show parameter memory
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
hi_shared_memory_address integer 0
memory_max_target big integer 10G
memory_target big integer 10G
shared_memory_address integer 0
SGA_TARGET=0为禁用SGA自动内存管理
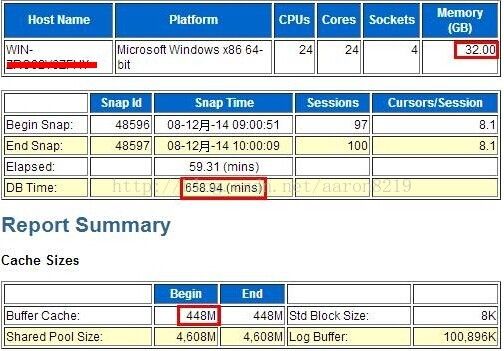
之前的AWR报告中db buffer cache只给分配了450M左右,而shared pool则有4G左右,11g的AMM的副作用是:可能会使shared pool越来越大,而db buffer cache可用内存则减少(总SGA不变的情况下)
6G左右的SGA中,很大一部分都分配给了shared pool,db buffer cache只得到了448M
修改MEMORY_MAX_SIZE和MEMROY_TARGET为10G后:
由于之前MEMORY_MAX_SIZE和MEMORY_SIZE只给了6G,即采用AMM管理SGA和PGA,那么当SGA接近6G时,PGA基本上就只能获得非常少了,也就符合了之前第3条,PGA耗尽时造成了之前的“unable to spawn...”的错误。调整了SGA后与客户的DBA沟通了一下,让他后续要观察db buffer cache和shared pool这2个参数的值,尤其是注意之前的现象是否会重现(shared pool一直变大,db buffer cache一直变小),否则就要禁用掉AMM,即设置MEMORY_TARGET=0,然后手动设置这2个内存池的大小,把它们固定死。其实对于OS为32G内存而言,MEMORY_TARGET给10G已经算是保守的了,给一半(16G)其实也不过分,具体还是看业务需求,如果没有因SGA内存过少引起的性能瓶颈出现,那么就无需调整。
故障解决完之后,顺便查看了一下DG配置是否正常时,发现主库归档能顺利传递到备库,在主库切几次归档,也都能传过去,但是备库的归档却没有自动应用,而此时MRP进程是启动的。直接执行alter database recover managed standby database cancel;就直接hang在那里。只有把备库关闭并重启,并重新启动redo apply后,归档才顺利应用。这个问题也挺奇葩的,之前用shutdown immediate楞是卡在那里半天,备库也关不了。由于备库本来就是同步主库归档,并且一般是不会open的,于是直接用了shutdown abort来关闭,才片刻把备库关闭掉了。
另外,在检查数据库时还发现,客户这里的库居然只配置了DG而已,连RMAN备份策略都没做,实在有点说不过去啊,核心业务库怎么能只做个DG就完事了呢,容灾平台固然重要,但基本的备份恢复策略也不应该丢嘛。于是直接和他们的DBA说了,应该尽快部署RMAN备份策略,这样才能保障数据库的安全性,数据丢了能及时恢复回来。