银行数据仓库体系实践(5)--数据转换
数据转换作业主要是指在数据仓库内的结构化数据批量加工,对于非结构化数据以及在线查询接口、数据流的开发主要是遵循代码开发规范以及各中间件的开发规范,如使用java来开发遵守java开发规范,使用Kafka需要遵循Kafka的使用和设计规范。同时做好组件的设计,提高复用程度和开发效率。这里就不再赘述,那对于批量加工数据各平台也有相应的开发规范,对于不同的平台有不同的规范,用来提高代码的运行效率和可维护性,以下是一些共性的设计规范。
1、常见算法及选择
数据转换作业从开发上可以分为两个步骤,一是数据映射,即每个字段的来源即计算方式,比如 目标表D字段是来自于源表S字段,计算方式是SUM(S)。二是目标表加工的算法,比如delete/insert,upsert等,它是将增量数据如何和历史数据融合转化为全量数据的常用处理方式,以下是在数据仓库中经常使用的一些算法:
(1)delete all/insert:先删除目标表当前所有数据,再插入全量最新数据,此算法适用于数据量较小且不需要保留历史数据的表。如代码表、参数表。例如:
Delete from D ;
insert D select * from A;
(2) Append:增量追加:将当前源表数据直接追加到目标表中。此算法需要源表数据以增量提供。这种算法一般在事件表(交易流水表)和总账表中使用较多,用来记录所有的历史交易记录,记录每天的交易以及总账的切片数据。
delete from D where trans_date=current_date ;
insert into A select * from S wheretrans_date=current_date ;
(3)UPSERT:使用源表数据更新目标表。如果新来的源数据已经在目标表中存在,则使用新来的源数据更新目标表中的相应数据,如果新来的源数据在目标表中不存在,则直接将其加入目标表中。针对此算法,源表选择全量或增量方式提供数据均可以。此算法适应于不保留历史的当前表。如集市区的账户或客户基本信息当前表。简要步骤如下:
步骤1:根据映射关系生成临时目标表T,已有目标表为D;
步骤2:update D set D.C1=T.C1 … where D.key in ( select T.key from T);
步骤3:insert D select * from T whereT.key not in (select key from D);
(4)标准历史拉链:由于数据仓库的一个特点就是保留历史数据,因此在主数据区的数据表基本都保留历史数据,那历史数据保留的算法除了Append方式就是历史拉链链方式。即在目标表中增加start_date(开始时间)和end_date(结束时间)字段,用来保存数据的历史变化。相对于Append算法堆加方式,此方法可以减少历史数据存储的空间要求并方便对历史数据的访问。适用于部分字段发生变化的表,如客户主表、账户主表等,针对此算法,源表选择全量或增量方式提供数据均可以。标准历史拉链的算法的举例和加工流程如下图所示:
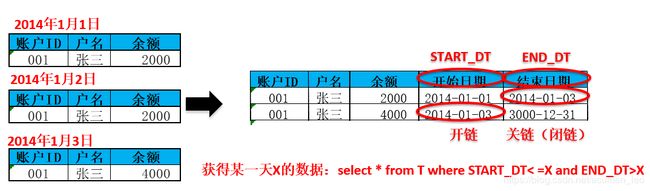
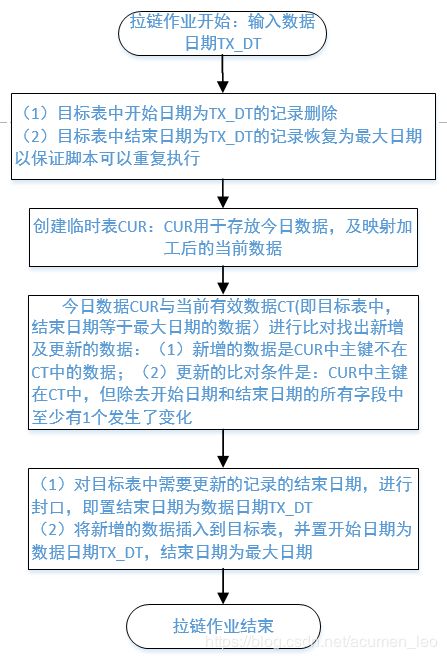
那对于不同的情况如存在删除数据情况下,在标准历史拉链的基础上又演变出了几种拉链算法,以下是几种变形算法:
(5)经济型历史拉链:在“标准历史拉链”算法的基础上,对PK外属性字段为0、’’等情况下的记录做关链处理。处于节约空间的考虑。允许断链存在,不影响金额统计的正确性。比如将协议金额历史表中余额为0的记录不放到目标表。一般较少使用到。
(6)全量数据的历史拉链:在“标准历史拉链”算法的基础上,对源数据中已经删除的记录打标记,并修改目标表中end_date来关闭该数据当前的时间链。此算法要求源表提供全量数据或能表示出删除数据的增量数据。适用于源系统表存在删除的情况;
(7)全主键历史拉链:“标准历史拉链”算法的变种,特点是表中全部字段(除了开始和结束日期外)都是拉链主键,没有属性。比如协议当事人关系表中,借据和担保人是多对多的关系,需要同时做PK。
(8)自拉链:对保留历史状态的源表进行历史拉链,如果源表已经保留了历史状态信息,但没有使用历史拉链(start_date/end_date)的方式,则通过对该源表进行自连接,将源表的数据以历史拉链的形式保存到目标表中。源表数据可能是保存了一段时间的历史数据。
2、作业设计规范
(1)作业划分及拆分
数据转换作业名一般以目标表作为一个加工作业,可以参考以下规则来命名:
目标表名[_顺序号](例如T01_PARTY、RMRT_AGREEMENT_001)
其中T01_PARTY、T03_AGREEMENT是目标表名,不同的数据区域会有不同的命名规范,如RMRT表示是零售集市数据区,T01表示主模型的PARTY主题表;顺序标识如001可省略。
顺序标识主要是因为同一个目标表可能需要通过几个独立的作业来实现,则需要使用顺序标识来区分,比如在整合模型区的T01_PARTY 表需要从核心、公贷、理财系统数据进行加工,但是核心系统数据提供比较晚,公贷和理财源系统数据提供比较早,为了提高后续作业效率,避免不必要的等待,可以按照源系统数据的到达时间进行分组,让到达时间相近的源系统在一个加载任务中,如公贷和理财系统数据入T01_PARTY作为1组,核心数据入T01_PARTY 为第2组。
(2)支持重跑
数据加工作业也需要支持重跑,方便作业异常重新发起,而不需要先手工清洗数据,因此在作业设计事需要
1)第1步就是需要恢复数据,比如历史拉链表加工T日数据第一步是将数据恢复到T-1日批后状态(参考标准历史拉链算法流程)。
2)使用临时表,将当天数据在临时表先加工完成,只在最后一次性更新目标表或者在最后直接以临时表作为最终的目标表。
3)最后更新目标表时需要使用事务,避免中间异常无法回退数据;
(3)支持历史数据处理;
作业支持重跑一般只支持当日数据重跑,对于T-N(N>1)日的历史数据重新跑到T日的话,除了APPEND及delete all/insert算法,一般需要手动先恢复到T-N日批后数据,再逐日跑数到T日,因此作业设计时也要考虑到这种情况,特别是在作业上线时会需要追数,因此在设计时需要对于存储历史数据的源表使用时需要使用作业参数中的数据日期(tx_date)来获得当日的数据,比如对于历史拉链表作为源表,使用时用tx_date来获得tx_date当日数据:
select * from T01_PARTY_H where start_dt<=tx_date and end_dt>tx_date
(3)作业监控
数据转换作业设计时,需要确保每一步加工的信息在日志输出,包括执行的sql语句,SQL执行的结果比如更新记录多少条、错误信息等,以便错误时快速查找原因,在调度系统集成中也需要能快速查看转换作业的日志。
(4)代码转换公共作业
在主数据区需要进行代码标准化,即将源系统的代码转换为数据仓库中定义的代码,这和个也是数据标准在数据仓库实施的一部分,因此会经常使用到代码转换,可以设计一张代码转换表,以源系统表名、源系统字段、源系统字段代码值为主键:
![]()
在转换作业中可以通过统一的方法即通过关联代码转换表获取对应的映射字段,不仅可以规范代码映射方法,也可以通过维护代码转换表获得数据仓库的代码标准和代码转换视图;
(5)表所属数据库或SCHEMA配置化
由于生产环境和测试环境可能不同,一套物理测试环境可能分开发、SIT和UAT环境,对于各表的所属schema或数据库需要可配置化(参数化),以便脚本在测试环境中运行,同时也需要做好生产脚本参数和测试环境参数的代码管理。
3、脚本开发自动化
由于算法相对固定,字段映射不同,因此可以针对不同的算法做好模板,再根据字都映射规则产生SQL填充到模板,这样可以节省代码开发量,同时提高数据转换作业的可维护性,以下时转换作业自动生成代码的关键信息
(1)基本信息描述:如物理表名称及表说明、开发人员及修改日期、表的主键字段
(2)任务信息描述:包括作业名称、作业执行频率(日、周、月、季、年)、ETL算法(第1部分提到的算法)。ETL算法如果是UPSERT算法,需要填写比较的字段、更新的字段。如果为拉链算法,需要填写比较的主键以及开始日期和结束日期字段。
(3)字段映射:字段映射主要包括如下字段映射、映射规则以及表关联:
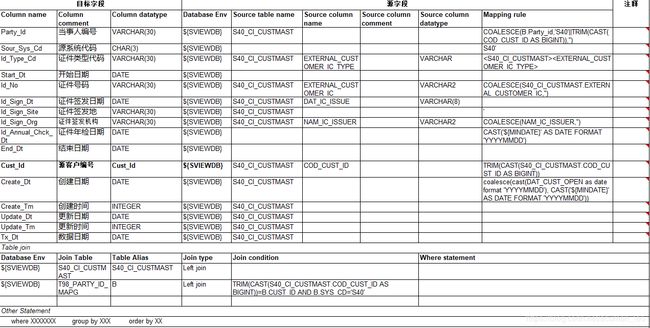
由于一个ETL作业可能有很多组映射组成,即有许多源表到目标表的映射加工,所以也需要标识组别,每一组在映射加工脚本前后还需要有自定义的SQL脚本,也可以每组映射只有自定义脚本,以方便SQL加工前处理数据或者适应无法用MAPPING描述的规则。
在填写配置信息时,需要将需求中的字段映射关系备注也放到配置文件中,对于自定义的SQL也需要做好备注,这些备注也会自动显示在脚本的注释中。增加配置信息及最终生成的脚本的可读性。
基于以上的信息以及目标表和源表的字段信息,已经具有自动化生成脚本的所有信息,可以根据这些信息自动化产生脚本,配置信息结构以及脚本生成主要步骤如下:
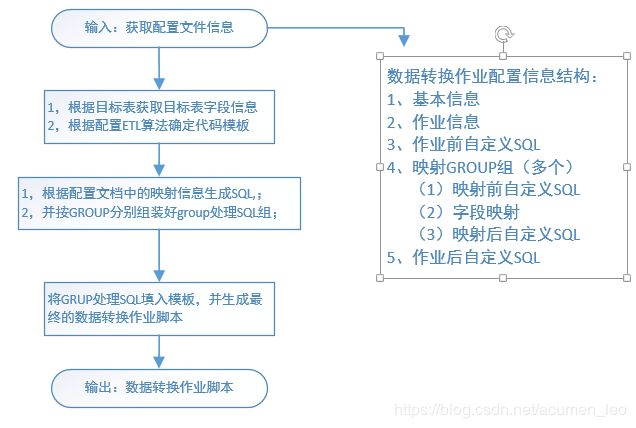
接下来将介绍数据仓库模型设计方法论,欢迎关注: