spark/MLlib 协同过滤算法
http://www.cnblogs.com/zhangchaoyang/articles/2664366.html
Collaborative Filtering Recommendation 协同过滤推荐算法
向量之间的相似度
度量向量之间的相似度:距离的倒数、向量夹角、相关系数等。
皮尔森Pearson相关系数:
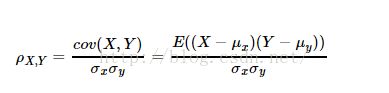 或
或 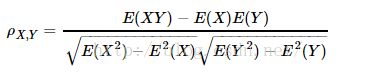
当两个变量的线性关系增强时,相关系数趋向于1或-1。Pearson相关系数在计算相关度(相似度)时忽略其平均值的影响。
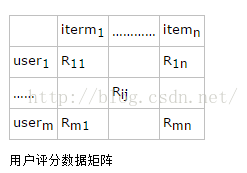
基于用户的协同过滤
1.如果用户i对商品j没有评过分,就找到与用户i最相似的K个邻居(采用Pearson相关系数)
2.然后用这K个邻居对商品j的评分的加权平均来预测用户i对商品j的评分

计算用户U1和U2的相似度时并不是去拿原始的评分向量去计算,而是只关注他们的评交集Ix,y,这是因为一个用户只对很少的物品有过评分,这样用户评分向量是个高度稀疏的向量,采用Pearson相关系数计算两个用户的相似度时很不准。
基于物品的协同过滤
1.如果用户i对项目j没有评过分,就把矩阵相应位置置为0.找到与物品j最相似的k个近邻(采用余弦距离)
2.然后用这k个邻居对项目j的评分的加权平均来预测用户i对项目j的评分

由于物品之间的相似度比较稳定,可以离线先算好,定期更新即可。
混合协同过滤
主体思路是基于用户的协同过滤,只是在计算两个用户的相似度时使用了item-based CF思想。

Spark MLlib
MLlib支持基于模型的系统过滤,使用能够预测缺省值得一个隐藏因素集合来表示用户和产品。MLlib使用ALS学习隐藏因子。
算法参数:
rank 模型中隐藏因子数
iterations 算法迭代次数
lambda ALS中的正则化参数
numBlocks 并行计算的block数
implicitRrefs 使用显式反馈ALS变量或隐式反馈
alpha ALS隐式反馈变化率
数据格式:
user product rate
//加载数据
val data=sc.textFile("")
//解析数据格式
val ratings = data.map(_.split("::") match { case Array(user,item,rate,ts) =>
Rating(user.toInt, item.toInt ,rate.toDouble)
}).cache()
//统计输入的用户和商品数量
val users=ratings.map(_.user).distinct()
val products=ratings.map(_.product).distinct()
val rates=ratings.count()
//划分数据集为训练集和测试集
val splits = ratings.randomSplit( Array( 0.8,0.2),seed =111L )
val training=splits(0).repartition(numPartitions)
val test=splits(1).repartition(numPartitions)
//训练模型
val rank=12
val lambda=0.01
val numIterations=5 //迭代次数太大需要的内存很多
val model=ALS.train(ratings,rank,numIterations,lambda)
//模型中用户和商品特征向量
model.userFeatures
model.productFeatures
//评分数据中的(用户,产品)列表
val usersProducts=ratings.map{ case Rating(user,product,rate) =>
(user,product)
}
//使用模型对用户商品进行预测评分
var predictions = model.predict(usersProducts).map{ case Rating (user,product,rate) =>
((user,product),rate)
}
//将真实评分数据和预测评分数据合并
val ratesAndPreds=ratings.map { case Rating(user,product,rate) =>
((user,product),rate)
}.join(predictions)
//模型指标
val rmse= math.sqrt (ratesAndPreds.map { case ( (user,product) ,(r1 , r2)) =>
val err=(r1-r2)
err*err
}.mean())
println(s"RMSE= $rmse")
//保存评分结果
rateAndPreds.sortByKey().repartition(1).sortBy(_._1).map({
case ( (user,product) ,(rate,pred)) =>(user+","+product+","+rate+","+pred)
}).saveAsTextFile("")
//给用户推荐商品
val topKRecs = model.recommendProducts(userId,K)
println(topKRecs.mkString("\n"))
//查看用户的评分记录
val goodsForUser = ratings.keyBy(_.user).lookup(userId)
//查看一个用户对一个商品的实际评分和预测评分
//实际评分
val actualRating=goodsForUser.take(1)(0)
//预测评分
val predictedRating=model.predict(userId,actualRating.product)
//方差
val squaredError = math.pow(predictedRating-actualRating.rating,2.0)
//批量推荐
获得评分记录中的所有用户然后依次给每个用户推荐
val users=ratings.map(_.user).distinct()
users.collect.flatMap( user =>
model.recommendProducts(user,10)
)
//保存和加载推荐模型
model.save(model:MatrixFactorizationModel , path:String)
MatrixFactorizationModel.load(sc,path)
model中的userFeatures和productFeatures也能保存起来。
model.userFeatures.map{ case (id,vec) =>id+"\t"+vec.mkString(",")}.saveAsTextFile(outputDir +"/userFeatures")
model.productFeatures.map{ case (id,vec) =>id+"\t"+vec.mkString(",")}.saveAsTextFile(outputDir +"/productFeatures")
MLlib ALS算法
ALS,交替最小二乘法。
ALS假设:打分矩阵是近似低秩的,即
, ,
可以把打分矩阵A看成是用户喜好矩阵U和产品特征矩阵V的乘积。
量化目标
量化的目标就是通过U,V重构A所产生的误差。使用Frobenius范数, ,就是每个元素的重构误差的平方和。但是我们只能观察到部分打分,重构误差中包含未知数的,再次简化为对已知打分进行重构误差,目标函数变为 ,这里的R是观察到的评分。问题转换为了目标函数的优化问题。
使用交替最小二乘解决这个优化问题。ALS的目标函数不是凸函数,而是变量互相耦合在一起。我们把用户特征矩阵U和产品特这矩阵V固定其一,问题就变成了凸优化问题。
固定U,目标函数变为
%E3%80%82%E5%85%B6%E4%B8%AD%E5%85%B3%E4%BA%8E%E6%AF%8F%E4%B8%AA%E4%BA%A7%E5%93%81%E7%89%B9%E5%BE%81!%5B%5D(http://img.ptcms.csdn.net/article/201505/07/554b6a207b96d.jpg)%E7%9A%84%E9%83%A8%E5%88%86%E6%98%AF%E7%8B%AC%E7%AB%8B%E7%9A%84%EF%BC%8C%E4%B9%9F%E5%B0%B1%E6%98%AF%E8%AF%B4%E5%9B%BA%E5%AE%9AU%E6%B1%82!%5B%5D(http://img.ptcms.csdn.net/article/201505/07/554b6a555325d.jpg)%E6%88%91%E4%BB%AC%E5%8F%AA%E9%9C%80%E8%A6%81%E6%9C%80%E5%B0%8F%E5%8C%96!%5B%5D(http://img.ptcms.csdn.net/article/201505/07/554b6a77e08c7_middle.jpg?_=48481)%E5%B0%B1%E5%A5%BD%E4%BA%86%EF%BC%8C%E8%BF%99%E4%B8%AA%E9%97%AE%E9%A2%98%E5%B0%B1%E6%98%AF%E7%BB%8F%E5%85%B8%E7%9A%84%E6%9C%80%E5%B0%8F%E4%BA%8C%E4%B9%98%E9%97%AE%E9%A2%98%E3%80%82%E6%89%80%E8%B0%93%E2%80%9C%E4%BA%A4%E6%9B%BF%E2%80%9D%EF%BC%8C%E5%B0%B1%E6%98%AF%E6%8C%87%E6%88%91%E4%BB%AC%E5%85%88%E9%9A%8F%E6%9C%BA%E7%94%9F%E6%88%90!%5B%5D(http://img.ptcms.csdn.net/article/201505/07/554b6ac97a0be.jpg)%E7%84%B6%E5%90%8E%E5%9B%BA%E5%AE%9A%E5%AE%83%E6%B1%82%E8%A7%A3!%5B%5D(http://img.ptcms.csdn.net/article/201505/07/554b6aeb5b406.jpg)%EF%BC%8C%E5%86%8D%E5%9B%BA%E5%AE%9A!%5B%5D(http://img.ptcms.csdn.net/article/201505/07/554b6b007da66.jpg)%E6%B1%82%E8%A7%A3!%5B%5D(http://img.ptcms.csdn.net/article/201505/07/554b6b2734f68.jpg) ,交替进行,每步迭代都会降低重构误差,并且误差是有下界的,所以ALS一定收敛。但由于问题是非凸的,ALS并不保证会收敛到全局最优解。
,交替进行,每步迭代都会降低重构误差,并且误差是有下界的,所以ALS一定收敛。但由于问题是非凸的,ALS并不保证会收敛到全局最优解。
,交替进行,每步迭代都会降低重构误差,并且误差是有下界的,所以ALS一定收敛。但由于问题是非凸的,ALS并不保证会收敛到全局最优解。
ALS对初始点不是很敏感,对最后结果影响不大。