R-CNN系列比较
RCNN可以看作是RegionProposal+CNN这一框架的开山之作,
RCNN的主要缺点是重复计算,后来MSRA的kaiming组的SPPNET做了相应的加速。
传统的detection主流方法是DPM(Deformable parts models), 在VOC2007上能到43%的mAP,CNN流行之后,Szegedy做过将detection问题作为回归问题的尝试(Deep Neural Networks for Object Detection),但是效果差强人意,在VOC2007上mAP只有30.5%。既然回归方法效果不好,而CNN在分类问题上效果很好,那么为什么不把detection问题转化为分类问题呢?RBG的RCNN使用region proposal来得到有可能是object的若干(大概10^3量级)图像局部区域,然后把这些区域分别输入到CNN中,得到区域的feature,再在feature上加上分类器,判断feature对应的区域是属于具体某类object还是背景。当然,RBG还用了区域对应的feature做了针对boundingbox的回归,用来修正预测的boundingbox的位置。RCNN在VOC2007上的mAP是58%左右。
检测微调
RCNN存在着重复计算的问题(proposal的region有几千个,多数都是互相重叠,重叠部分会被多次重复提取feature),于是RBG借鉴Kaiming He的SPP-net的思路单枪匹马搞出了Fast-RCNN,跟RCNN最大区别就是Fast-RCNN将proposal的region映射到CNN的最后一层conv layer的feature map上,这样一张图片只需要提取一次feature,大大提高了速度,也由于流程的整合以及其他原因,在VOC2007上的mAP也提高到了68%。
探索是无止境的。Fast-RCNN的速度瓶颈在Region proposal上,于是RBG和Kaiming He一帮人将Region proposal也交给CNN来做,提出了Faster-RCNN。Fater-RCNN中的region proposal netwrok实质是一个Fast-RCNN,这个Fast-RCNN输入的region proposal的是固定的(把一张图片划分成n*n个区域,每个区域给出9个不同ratio和scale的proposal),输出的是对输入的固定proposal是属于背景还是前景的判断和对齐位置的修正(regression)。Region proposal network的输出再输入第二个Fast-RCNN做更精细的分类和Boundingbox的位置修正。Fater-RCNN速度更快了,而且用VGG net作为feature extractor时在VOC2007上mAP能到73%。
个人觉得制约RCNN框架内的方法精度提升的瓶颈是将dectection问题转化成了对图片局部区域的分类问题后,不能充分利用图片局部object在整个图片中的context信息。可能RBG也意识到了这一点,所以
他最新的一篇文章YOLO(
http://
arxiv.org/abs/1506.0264
0
)又回到了regression的方法下,这个方法效果很好,在VOC2007上mAP能到63.4%,而且速度非常快,能达到对视频的实时处理。
Fast R-CNN
Fast R-CNN采用了多项创新来提高训练和测试速度同时也提高检测精度。Fast R-CNN训练非常深的VGG16网络比R-CNN快9倍,测试时间快213倍,并在PASCAL VOC上得到更高的精度。与SPPnet相比,fast R-CNN训练VGG16网络比他快3倍,测试速度快10倍,并且更准确。
与图像分类相比,目标检测是一个更具挑战性的任务,需要更复杂的方法来解决。由于这种复杂性,当前的方法主要是采用多级流水线的方式训练模型,这种方法既慢而且精度又不高。复杂性的产生是因为检测需要目标的精确定位,这就导致两个主要的难点。首先,必须处理大量候选目标位置框(通常称为“提案”)。 第二,这些候选框仅提供粗略定位,其必须被精细化以实现精确定位。 这些问题的解决方案经常会影响速度,准确性或简单性。
这篇文章简化了最先进的基于卷积网络的目标检测器的训练过程。提出一个单阶段训练算法,把候选框分类的学习和修正他们的空间位置结合在一起。
R-CNN与SPPnet
基于区域的卷积网络方法(RCNN)通过使用深度卷积网络来分类目标候选框,获得了很高的目标检测精度。然而,R-CNN具有显着的缺点:
- 训练过程是多级流水线。R-CNN首先在目标候选框上使用log损失函数微调一个卷积网络。然后,它将卷积神经网络得到的特征送入SVM。 这些SVM作为目标检测器,通过微调后替代softmax分类器。 在第三个训练阶段,学习边界框回归。
- 训练在时间和空间上是的开销很大。对于SVM和边界框回归训练,从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,这个过程在单个GPU上需要2.5天(VOC07 trainval上的5k个图像)。这些特征需要数百GB的存储空间。
- 目标检测速度很慢。在测试时,从每个测试图像中的每个目标候选框提取特征。用VGG16网络检测目标每个图像需要47秒(在GPU上)。
R-CNN很慢是因为它为每个目标候选框都执行卷积神经网络正向传递,而不是共享计算。SPPnet 5
通过共享计算加速R-CNN。SPPnet5计算整个输入图像的卷积特征图(最后一层的特征图),然后使用从共享特征图(最后一层的特征图)提取的特征向量来对每个候选框进行分类。通过最大池化候选框内的特征图部分,提取固定大小的特征输出(例如,6X6)给每个候选框。多个输出大小被池化,然后连接成空间金字塔池7。SPPnet在测试时将R-CNN加速10到100倍。由于更快的候选框特征提取训练时间也减少3倍。
SPP网络也有显著的缺点。像R-CNN一样,训练过程是一个多级流水线,涉及提取特征,使用log损失对网络进行微调,训练SVM分类器,最后拟合检测框回归,特征也写入磁盘。
Fast RCNN方法有以下几个优点:
- 比R-CNN和SPPnet具有更高的目标检测精度(mAP)。
- 训练是使用多任务损失的单阶段训练。
- 训练可以更新所有网络层参数(R-CNN和SPPNet只能更新部分层的擦参数)。
- 不需要磁盘空间缓存特征。
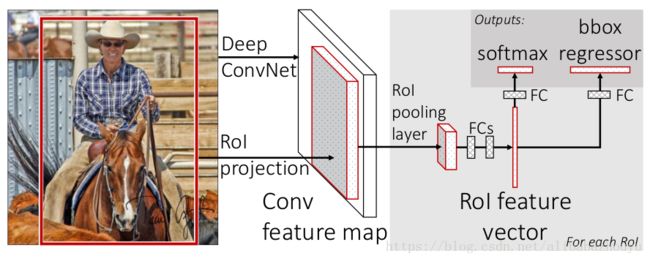
图1. Fast R-CNN架构。输入图像和多个感兴趣区域(RoI)被输入到全卷积网络中。每个RoI被池化到固定大小的特征图中,然后通过全连接层(FC)映射到特征向量。网络对于每个RoI具有两个输出向量:Softmax概率和每类检测框回归偏移量。该架构是使用多任务损失端到端训练的。
Fast R-CNN网络将整个图像和一组候选框作为输入。网络首先使用几个卷积层(conv)和最大池化层来处理整个图像,以产生卷积特征图。然后,对于每个候选框,RoI池化层从特征图中提取固定长度的特征向量。每个特征向量被送入一系列全连接(fc)层中,其最终分支成两个同级输出层 :一个输出KK个类别加上1个背景类别的Softmax概率估计,另一个为KK个类别的每一个类别输出四个实数值。每组4个值表示KK个类别的一个类别的检测框位置的修正。RoI池化层使用最大池化将任何有效的RoI内的特征图转换成具有H×W(例如,7×7)的固定空间范围的小特征图。
RoI最大池化通过将大小为h×w的RoI窗口分割成H×W个网格,子窗口大小约为h/H×w/W,然后对每个子窗口执行最大池化,并将输出合并到相应的输出网格单元中。同标准的最大池化一样,池化操作独立应用于每个特征图通道。RoI层只是SPPnets 5中使用的空间金字塔池层的特殊情况,其只有一个金字塔层。
从预训练网络初始化
实验了三个预训练的ImageNet 9
网络,每个网络有五个最大池化层和五到十三个卷积层(网络详细信息,请参见 实验配置
)。当预训练网络初始化fast R-CNN网络时,其经历三个变换。
首先,最后的最大池化层由RoI池层代替,其将H和W设置为与网络的第一个全连接层兼容的配置(例如,对于VGG16,H=W=7H=W=7)。
然后,网络的最后一格全连接层和Softmax(其被训练用于1000类ImageNet分类)被替换为前面描述的两个同级层(全连接层加上K+1个类别的Softmax以及特定类别的边界框回归)。
最后,网络被修改为采用两个数据输入:图像的列表和这些图像中的RoI的列表。
用反向传播训练所有网络权重是Fast R-CNN的重要能力。
在训练期间,图像以概率0.5水平翻转。不使用其他数据增强。
SGD超参数。
用于Softmax分类和检测框回归的全连接层的权重分别使用具有方差0.01和0.001的零均值高斯分布初始化。偏置初始化为0。当对VOC07或VOC12trainval训练时,运行SGD进行30k次小批量迭代,然后将学习率降低到0.0001,再训练10k次迭代。当训练更大的数据集,我们运行SGD更多的迭代, 使用0.9的动量和0.0005的参数衰减(权重和偏置)。
尺度不变性
我们探索两种实现尺度不变对象检测的方法:(1)通过“brute force”学习和(2)通过使用图像金字塔。 这些策略遵循 5中的两种方法。
使用截断的SVD来进行更快的检测
截断奇异值分解(Truncated singular value decomposition,TSVD)是一种矩阵因式分解(factorization)技术,将矩阵分解成,和。它与PCA很像,只是SVD分解是在数据矩阵上进行,而PCA是在数据的协方差矩阵上进行。通常,SVD用于发现矩阵的主成份。大的全连接层容易通过用截断的SVD压缩来加速。截断SVD。截断的SVD可以将检测时间减少30%以上,同时在mAP中只有很小(0.3个百分点)的下降,并且无需在模型压缩后执行额外的微调。
result
快速的训练和测试是我们的第二个主要成果。 Fast R-CNN还不需要数百GB的磁盘存储,因为它不缓存特征。如果在压缩之后再次微调,则可以在mAP中具有更小的下降的情况下进一步加速。
微调哪些层?
在较小的网络(S和M)中,我们发现conv1(第一个卷积层)是通用的和任务独立的(一个众所周知的事实 1
)。允许conv1学习或不学习,对mAP没有很有意义的影响。对于VGG16,我们发现只需要更新conv3_1及以上(13个卷积层中的9个)的层。这种观察是实用的:(1)从conv2_1更新使训练变慢1.3倍(12.5小时对比9.5小时)和(2)从conv1_1更新GPU内存不够用。当从conv2_1学习时mAP仅为增加0.3个点(表5,最后一列)。 所有Fast R-CNN在本文中结果都使用VGG16微调层conv3_1及以上的层,所有实验用模型S和M微调层conv2及以上的层。
多任务训练有用吗?
多任务训练是方便的,因为它避免管理顺序训练任务的流水线。但它也有可能改善结果,因为任务通过共享的表示(ConvNet) 18相互影响。
尺度不变性:暴力或精细?
我们比较两个策略实现尺度不变物体检测:暴力学习(单尺度)和图像金字塔(多尺度)。在任一情况下,我们将图像的尺度s定义为其最短边的长度。所有单尺度实验使用s=600像素,对于一些图像,s可以小于600,因为我们保持横纵比缩放图像,并限制其最长边为1000像素。在多尺度设置中,我们使用5中指定的相同的五个尺度(s∈{480,576,688,864,1200},由于单尺度处理提供速度和精度之间的最佳折衷,特别是对于非常深的模型,本小节以外的所有实验使用单尺度训练和测试,s=600s=600像素。
我们需要更过训练数据吗?
当提供更多的训练数据时,好的目标检测器应该会得到改善。
扩大训练集提高了VOC07测试的mAP,在这里我们增加VOC07 trainval训练集与VOC12 trainval训练集,大约增加到三倍的图像,从66.9%到70.0%。
SVM分类是否优于Softmax?
Fast R-CNN在微调期间使用softmax分类器学习,而不是如在R-CNN和SPPnet中训练线性SVM。
对于所有三个网络,Softmax略优于SVM,mAP分别提高了0.1和0.8个点。这种效应很小,但是它表明与先前的多级训练方法相比,“一次性”微调是足够的。我们注意到,Softmax,不像SVM那样,在分类RoI时引入类之间的竞争。
更多的候选区域更好吗?
存在(广义地)两种类型的目标检测器:使用候选区域的稀疏集合(例如,选择性搜索 21
)和使用密集集合(例如DPM 11
)。我们发现提案分类器级联也提高了Fast R-CNN的精度。使用选择性搜索的质量模式,我们扫描每个图像1k到10k个候选框,每次重新训练和重新测试模型M.如果候选框纯粹扮演计算的角色,增加每个图像的候选框数量不应该损害mAP。我们发现mAP上升,然后随着候选区域计数增加而略微下降(图3,实线蓝线)。这个实验表明,用更多的候选区域没有帮助,甚至稍微有点伤害准确性。
用于衡量候选区域质量的最先进的技术是平均召回率(AR),AR必须小心使用,由于更多的候选区域更高的AR并不意味着mAP会增加。幸运的是,使用模型M的训练和测试需要不到2.5小时。因此,Fast R-CNN能够高效地,直接地评估目标候选区域mAP,这优于代理度量。
目前显示的是密集产生候选框没有稀疏框好,未来可能会发现原因,或许密集产生候选框也能有很好的效果。如果发现了方法,可以加速目标检测。