Deep TextSpotter: An End-to-End Trainable Scene Text Localization and Recognition Framework
效果:
1、在ICDAR 2013 and ICDAR 2015的端到端识别中达到当时最好的精度
2、速度很快,检测+识别可达到10FPS.
本文特点:
是端到端的框架,同时检测和识别文本
贡献:
1、在单个框架中训练文本检测和文本识别,并证明了它的效果优于把两个最优的文本检测网络和文本识别网络相结合的方法
2、证明了最先进的目标检测方法可以用于扩展到文本检测和文本识别中
3、在ICDAR 2013 and ICDAR 2015的端到端识别中实现了最高精度和最快速度的效果,是之前方法的十倍快.
本文的旋转角度theta是连续参数,即可以360°,并且最佳的锚箱anchor boxes的尺寸是在训练集上找到的。
方法的流程图如下:
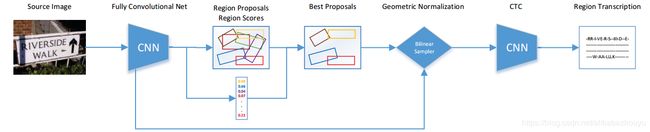
图 1
RPN生成text region proposals,然后置信度高的proposals被使用双线性采样Bilinear Sampler来归一化到相关的高度,最后使用CTC对这些proposals进行识别.
2.2.场景文本识别
shibaoguang的crnn方法无论它包含多少个字符,都将源图像的大小调整为100×32像素的固定大小的矩阵,并且由于使用了LSTM层而显着变慢。
本文使用YOLOv2框架因为其具有较低的复杂性,我们使用双线性采样产生可变宽度的张量来处理字符序列识别,我们采用不同的(并且明显更快)分类阶段。
3.本文方法
我们的模型在端到端训练的框架中联合优化文本定位和识别。
1.CNN
3.1。完全卷积网络
如图1所示的CNN,我们采用YOLOv2架构,因为它来比标准的VGG-16架构更准确并显着降低复杂性,因为完整的VGG-16架构需要300亿次操作才能处理224×224(0.05 Mpx)图像[22]。因此使用YOLOv2架构允许我们处理具有更高分辨率的图像,这是文本识别的关键能力 - 需要以更高分辨率处理,因为1Mpx场景图像可能包含文本只有10像素高[12],因此缩小源图像将使文本不可读。
所提出的方法使用来自YOLOv2架构的前18个卷积层和5个最大池池,它基于3×3卷积滤波器,使数量增加一倍每个池化步骤后添加1×1过滤器的通道压缩3×3滤波器之间的表示[22]。我们删除完全连接的层以构建网络完全卷积,所以我们的模型最终层的维度为
W/32*H/32*1024,其中W a H表示源图像的宽度和高度[22]。
区域建议
与faster R-CNN [23]和YOLOv2 [22]类似,我们使用区域提议网络(RPN)来生成区域提议,但我们添加了旋转rθ(faster rcnn和yolo-v2都没有角度),这对于成功的文本识别至关重要。在RPN的最后一个卷积层的每个位置,模型预测k个旋转的边界框,其中对于每个边界框r,我们预测6个特征 - 即位置rx,ry,其尺寸rw,rh,其旋转rθ及其文本置信度得分rp,rp捕获区域包含文本的概率。
使用逻辑激活函数来获得相对于预定义的锚框的边界框位置和尺寸,因此源图像中的实际边界框位置(x,y)和尺寸(w,h)给出为
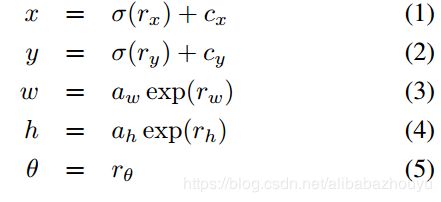
其中cx和cy表示最后一个卷积层中的网格的偏移量,aw和ah表示某个anchor boxe a预定义的高度和宽度。通过rθ直接预测边界框的旋转角度θ∈( - π2,π2).
我们遵循Redmon等人的方法 [22]并通过聚合训练集上的kmeans聚类找到合适的锚箱尺度和宽高比。要求IOU具有至少60%的时候,得到k = 14个不同的anchor boxes尺寸(参见图3)
对于每个图像,RPN产生W/32*H/32*6k(错了吧,应该是W/32*H/32*k个吧)的盒子,其中k是每个位置的锚箱数量,6是预测参数的数量(x,y,w,h,θ和文本分数)。
在训练阶段,我们使用YOLOv2方法[22]通过采集源图像中的所有正样本和负样本??,其中每20个批次我们随机将输入维度大小更改为{352,416,480,544,608}中的一个。正样本是与地面实况结合最高的交叉点的区域,其他交叉区域是负样本。
在运行时,我们发现最好的方法是将得分rp高于特定阈值pmin的所有区域推迟,并在识别阶段后推迟非最大值抑制,因为具有非常相似的rp得分的区域可以产生非常不同的转录,因此在这个阶段选择具有最高rp的区域并不总是对应于正确的转录(例如,在某些情况下,包含字母“TALY”的区域可能具有比包含完整单词“ITALY”的区域略高的分数rp。我们凭经验发现值pmin = 0.1是精度和速度之间的合理权衡。
3.双线性采样
在前一阶段中检测到的每个区域具有不同的尺寸和旋转角度,因此有必要将特征映射到规范尺寸的张量,这可以用于识别。
Faster R-CNN [23]使用了Girshick [3]的RoI pooling方法,其中w×h×C的区域映射到固定大小的W'×H'×C的网格(例如faster rcnn的是7×7×1024),其中每个单元格是原来池化前的w/W×h/H这么大的区域的最大池化。
在我们的模型中,我们使用双线性采样[9,11]将来自源图像的w×h×C区域映射到固定高度wH'/h×H'×C的张量(本文的H '= 32,即固定高度为32)。与标准RoI方法相比,此特征表示具有关键优势,因为它允许网络规范化旋转和缩放,但同时保持单个字符的宽高比和位置,这对于文本识别准确性至关重要(参见第3.4节)。
给定检测到的区域特征![]() ,它们通过一下公式被映射到固定高度张量
,它们通过一下公式被映射到固定高度张量![]()
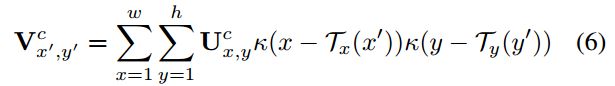
这应该就是双线性插值的公式吧?
3.4文本识别
给定来自源图像的归一化区域,每个区域与字符序列相关联,或者在下面的过程中作为非文本被拒绝。在该步骤中必须解决的主要问题是,不同大小的文本区域必须被映射到不同长度的字符序列。我们的模型利用了一个新的全卷积网络(见表1),它采用可变宽度特征张量W×H? ×C作为输入(W = wH h?)并输出矩阵W4×| A | ,其中A是字母表(例如所有英文字符)。矩阵高度是固定的(它是字符类的数量),但它的宽度随着源区域的宽度而增加,因此随着预期字符序列的长度而增长。
该模型使用连接主义时间分类(CTC)[5,24]将可变宽度特征张量转换为标签序列上的条件概率分布。然后使用该分布为文本区域选择最可能的标记序列(参见图4)。令y = y1,y2,...,yn表示从用空白符号“ - ”扩展的字母A中的长度为n的网络输出的矢量。然后给出路径π的概率为
让我们进一步定义多对一映射B:A n→A≤n,其中A≤n是长度更短或相等的所有序列的集合。映射B删除所有空白和重复标签,这对应于每次标签预测改变时输出新标签。例如,B(-ww-al-k)= B(wwaaa -l-k-)=步行
B(-f - oo - o - -d)= B(ffoo - ooo - d)=食物然后给出观察输出序列w的条件概率
p(w | y)=? π:B(π)= w p(π| y),w∈A≤n(8)
在训练中,使用最大化目标标记p(w | y)的对数似然的目标函数[5]。在每个训练步骤中,使用类似于HMM训练的前向算法[20]有效地计算小批量中每个文本区域的概率p(wgt | y),并且使用目标函数导数来更新网络权重,使用标准反向传播算法(wgt表示文本区域的基本真实转录)。
在测试时,分类输出w *应该由最可能的路径p(w | y)给出,遗憾的是它不易处理,因此我们采用最可能的标记的近似方法[5]
w *≈B?argmax p(π| y)? (9)
在此过程结束时,图像中的每个文本区域都具有字符序列形式的关联内容,或者当所有标签都为空白时,它被拒绝为非文本。
该模型通常为图像中的单个文本区域生成许多不同的框,因此我们通过基于文本识别置信度的标准非极大值抑制算法来抑制重叠框,这是由文本标准化的p(w * | y)长度。
所提出的模型在IC13的主要限制是单个字符或数字和字符的短片段(参见图7),这可能部分地由于这样的示例在训练集中不是非常频繁的事实引起。在IC15的限制是在模糊和噪声文本的检测识别上,
结论
提出了一种新的场景文本定位和识别框架。该模型在单一训练框架中训练文本检测和识别。所提出的模型在两个标准数据集(ICDAR 2013和ICDAR 2015)上实现了端到端文本识别的最先进准确度,同时比以前的方法快一个数量级 - 整体
管道在NVidia K80 GPU上以每秒10帧的速度运行。我们的模型表明,最先进的物体检测方法[22,23]可以扩展用于文本检测和识别,考虑到文本的细节,并且仍然保持低计算复杂度。我们还证明了端到端任务联合训练的优势,通过优于现有技术的本地化和最先进的识别方法[6,4,8]的特殊组合,同时利用相同的训练数据。
最后但并非最不重要的是,我们发现在人类注释的边界框上优化定位精度可能无法提高端到端系统的性能,因为方法与人类创建的边界框的匹配程度之间没有明确的联系。注释器以及方法读取文本的程度。未来的工作包括扩展训练集,使其具有更逼真的效果,例如包括单个字符和数字的数据集。