elasticsearch教程--中文分词器作用和使用
目录
-
概述
-
环境准备
-
认识中文分词器
- 常用的中文分词器
- IK Analyzer
- hanlp中文分词器
-
彩蛋
概述
上一篇博文记录了elasticsearch插件安装和管理, 在地大物博的祖国使用es,不得不考虑中文分词器,es内置的分词器对中文分词的支持用惨不忍睹来形容不为过,看这篇博文之前,建议先看一下博文elasticsearch分词器,对分词器有个初步理解。本文将记录一下项目中如何使用选用和使用中文分词器的,希望能够帮助到即将来踩坑的小伙伴们,欢迎批评指正
本文都是基于elasticsearch安装教程 中的elasticsearch安装目录(/opt/environment/elasticsearch-6.4.0)为范例
环境准备
- 全新最小化安装的centos 7.5
- elasticsearch 6.4.0
认识中文分词器
在博文elasticsearch分词器中提到elasticsearch能够快速的通过搜索词检索出对应的文章归功于倒排索引,下面通过中文举例看看倒排索引。
中文分词器作用以及效果
中文分词器是做什么的呢? what? 通过名字就知道了啊,为什么还要问。。。下面通过三个文档示例,看看它是如何分词的
文档1: 我爱伟大的祖国
文档2: 祝福祖国强大繁盛
文档3: 我爱蓝天白云
经过中文分词器,以上文档均会根据分词规则,将文档进行分词后的结果如下:
注意:不同的分词规则,分词结果不一样,选择根据分词器提供的分词规则找到适合的分词规则
文档1分词结果: [我,爱,伟大,的,祖国]
文档2分词结果: [祝福,祖国,强大,繁盛]
文档3分词结果: [我,爱,蓝天白云,蓝天,白云]
通过上面的分词结果,发现拆分的每个词都是我们熟知的词语, 但是如果不使用中文分词,就会发现上面的文档把每个字拆分成了一个词,对我们中文检索很不友好。
再看倒排索引
看到上面中文分词器结果,就会有新的疑问,使用中文分词器那样分词效果有什么好处呢? 答案就是根据分词建立词汇与文档关系的倒排索引。这步都是es帮我们做的,下面通过"我","爱","祖国"三个词看看倒排索引,如下图:
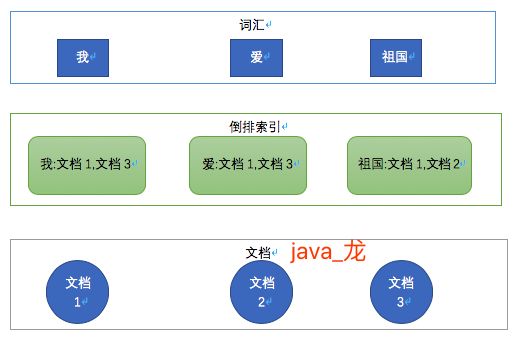
通过上图中的倒排索引,我们搜索"祖国"时,es通过倒排索引可以快速的检索出文档1和文档3。如果没有中文分词器,搜索"祖国"就会被拆分"祖""国"两个词的倒排索引, 就会把包含"祖"的文档都检索出来,很明显就会和我们想要的结果大相径庭。
常用的中文分词器
Smart Chinese Analysis: 官方提供的中文分词器,
IKAnalyzer: 免费开源的java分词器,目前比较流行的中文分词器之一,简单,稳定,想要特别好的效果,需要自行维护词库,支持自定义词典
结巴分词: 开源的python分词器,github有对应的java版本,有自行识别新词的功能,支持自定义词典
Ansj中文分词: 基于n-Gram+CRF+HMM的中文分词的java实现,免费开源,支持应用自然语言处理
hanlp: 免费开源,国人自然处理语言牛人无私风险的
个人对以上分词器进行了一个粗略对比,如下图:

截止到目前为止,他们的分词准确性从高到低依次是:
hanlp> ansj >结巴>IK>Smart Chinese Analysis
结合准确性来看,选用中文分词器基于以下考虑:
官方的Smart Chinese Analysis直接可以不考虑了
对搜索要求不高的建议选用 IK 学习成本低,使用教程多,还支持远程词典
对新词识别要求高的选用结巴分词
Ansj和hanlp均基于自然处理语言,分词准确度高,活跃度来讲hanlp略胜一筹
博主选用的hanlp分词器,目前线上运行结果来看准确性满足需求
下面就写一下博主对IKAnalyzer 和 hanlp分词器的使用
IK Analyzer
截止目前,IK分词器插件的优势是支持自定义热更新远程词典。
安装ik分词器插件
es插件安装教程参考这里
ik的es插件地址: https://github.com/medcl/elasticsearch-analysis-ik/releases
博主使用的es版本是6.4.0,下载时要注意对应es版本
在线安装ik es插件 命令:
# /opt/apps/elasticsearch-6.4.0/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.0/elasticsearch-analysis-ik-6.4.0.zip查看插件安装列表
# sudo /opt/apps/elasticsearch-6.4.0/bin/elasticsearch-plugin list![]()
IK配置
ik安装完毕后配置文件在 {ES_HOME}/config目录下, 本例目录是 /opt/apps/elasticsearch-6.4.0/config/analysis-ik/IKAnalyzer.cfg.xml
IK Analyzer 扩展配置
words_location
words_location
IK自定义词典维护
文本词典
ik文本词典均是以dic结尾,换行符作为分隔,示例如下:
# sudo vim /opt/apps/elasticsearch-6.4.0/config/analysis-ik/custom/myDic.dic
修改ik配置文件,将自定义的词典添加到ik配置中
custom/myDic.dic 重启es,注意一定要重启es
通过前面教程中,我们发现短语"我爱祖国",会被分词为, "我","爱","祖国"三个词, 如果按照上面词典定义后, "我爱祖国"会被当成一个词语不被分词。
热更新远程词典
热更新远程词典的优势是,修改词典后无需重启es。每分钟加载一次
修改IK配置文件如下:
location
location 其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
-
该 http 请求需要返回两个头部(header),一个是
Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。 -
该 http 请求返回的内容格式是一行一个分词,换行符用
\n即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
本文将远程词典存入数据库,示例如下:
@RequestMapping(value = "/getCustomDict")
public ResponseEntity getCustomDict(WebRequest webRequest) {
LOGGER.info("查询ik远程词典开始");
StringBuilder stringBuilder = new StringBuilder();
RemoteExtDictQuery query = new RemoteExtDictQuery();
query.setLastModifiedStart(new Date(1L));
query.setStatus(1);
final long[] lastModified = {1L};
// 这是从数据库查询字典,如果词语很多的话,可以分页查询
List remoteExtDictEntityList = remoteExtDictService.pageListRemoteExtDict(query);
if (remoteExtDictEntityList == null) {
remoteExtDictEntityList = new ArrayList<>();
}
remoteExtDictEntityList.stream().forEach((remoteExtDictEntity) -> {
if (remoteExtDictEntity != null) {
if (StringUtils.isNotBlank(remoteExtDictEntity.getWord())) {
stringBuilder.append(remoteExtDictEntity.getWord()).append("\n");
}
if (remoteExtDictEntity.getLastModified() != null) {
// 获取到最新一条的更新时间
long tempLastModified = remoteExtDictEntity.getLastModified().getTime();
if (Long.compare(lastModified[0], tempLastModified) < 0) {
lastModified[0] = tempLastModified;
}
}
}
});
// 使用总条数作为etag
String eTag = String.valueOf(remoteExtDictService.pageListRemoteExtDictCount(query));
if (webRequest.checkNotModified(eTag, lastModified[0])) {
// 检查etag和 lastModified,如果没有变化则返回空,远程词典不更新,否则返回最新词典
return null;
} else {
return ResponseEntity.ok().contentType(MediaType.parseMediaType("text/plain; charset=UTF-8"))
.body(stringBuilder.toString());
}
} hanlp 中文分词器
截止目前,hanlp词库是最大,分词效果是最好。使用hanlp分词插件之前,建议先点击此处学习一下hanlp
安装hanlp中文分词器插件
hanlp的elasticsearch插件众多,这里选用了这个,这个插件支持的分词模式要多一些,截止现在此插件最新支持6.3.2,由于插件中包含很大的词典文件,建议此插件采用离线安装
# cd /opt/packages
# sudo yum -y wget
## 因网络不通,可能需要很长时间
# sudo wget -c https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v6.3.2/elasticsearch-analysis-hanlp-6.3.2.zip
## 解压hanlp插件
# sudo unzip -n elasticsearch-analysis-hanlp-6.3.2.zip -d /opt/packages/elasticsearch-analysis-hanlp
# sudo mkdir -p /opt/apps/elasticsearch-6.4.0/analysis-hanlp/config
## 将插件配置放到{ES_HOME}/config 目录下
# sudo mv elasticsearch-analysis-hanlp/config/ /opt/apps/elasticsearch-6.4.0/analysis-hanlp/config
## 将插件放到{ES_HOME}/plugins 目录下
# sudo mv elasticsearch-analysis-hanlp /opt/apps/elasticsearch-6.4.0/plugins/analysis-hanlp查看插件安装列表
# sudo /opt/apps/elasticsearch-6.4.0/bin/elasticsearch-plugin list![]()
注意: 这里有一个hanlp的警告,es版本是6.4.0, 但是插件允许的es版本是6.3.2
上面的警告需要修改一下插件配置, 本方法仅限于博主对应的版本哟,其他版本没去试验
# sudo vim /opt/apps/elasticsearch-6.4.0/plugins/analysis-hanlp/plugin-descriptor.properties将 elasticsearch.version=6.3.2 修改为 elasticsearch.version=6.4.0,再次查看插件列表
![]()
ok,安装成功,安装完毕后必须重启es哟必须重启es哟必须重启es哟
hanlp配置
# 词典目录,本文保持默认
root=plugins/analysis-hanlp/
# 核心词典目录,本文保持默认,多个词典使用分号分隔
CoreDictionaryPath=data/dictionary/CoreNatureDictionary.txt
# Bigram词典目录,本文保持默认,多个词典使用分号分隔
BiGramDictionaryPath=data/dictionary/CoreNatureDictionary.ngram.txt
# 核心停用词词典目录,本文保持默认,多个词典使用分号分隔
CoreStopWordDictionaryPath=data/dictionary/stopwords.txt
# 核心同义词词典目录,本文保持默认,多个词典使用分号分隔
CoreSynonymDictionaryDictionaryPath=data/dictionary/synonym/CoreSynonym.txt
# 人名词典目录,本文保持默认,多个词典使用分号分隔
PersonDictionaryPath=data/dictionary/person/nr.txt
# 人名词典tr目录,本文保持默认,多个词典使用分号分隔
PersonDictionaryTrPath=data/dictionary/person/nr.tr.txt
# tc词典目录,本文保持默认,多个词典使用分号分隔
tcDictionaryRoot=data/dictionary/tc
# 自定义词典目录,根据最新词典设置,多个词典使用分号分隔
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; SearchCustomDictionary.txt; 现代汉语补充词库.txt; 全国地名大全.txt ns; 人名词典.txt; 机构名词典.txt; 上海地名.txt ns;data/dictionary/person/nrf.txt nrf;
# CRF segment model path
#CRFSegmentModelPath=data/model/segment/CRFSegmentModel.txt
# HMM segment model path
#HMMSegmentModelPath=data/model/segment/HMMSegmentModel.bin
# True of false show term nature
#ShowTermNature=true
# IO Adapter
##IOAdapter=com.hankcs.hanlp.corpus.io.FileIOAdapter
hanlp自定义词典
hanlp语料库词典
hanlp语料库地址为: https://github.com/hankcs/HanLP/releases, 本文截止目前最新版本为1.6.8
- 下载数据包 hanlp.linrunsoft.com/release/data-for-1.6.8.zip
- 解压到配置文件中key为root的值对应目录下
- 根据词典名调整hanlp配置中的词典配置,尤其注意CustomDictionaryPath的配置,以前采用的应用名,现在采用的中文名称
- 删除二进制缓存文件 rm -r /opt/apps/elasticsearch-6.4.0/plugins/analysis-hanlp/data/dictionary/custom/CustomDictionary.txt.bin, 如果自定义词典变更了,一点要执行这一步,否则词典不生效
- 一定要重启es!!!一定要重启es!!!一定要重启es!!!
hanlp自定义热更新词典
- 在配置文件中key为root的值对应目录下找到目录custom,进入此目录
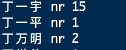
- 创建一个txt文件,示例: myDic.txt
- 在myDic.txt文件中添加词,分隔符为换行符, 词典格式为: [单词] [词性A] [A的频次] ,如图:
- 删除二进制缓存文件 rm -r /opt/apps/elasticsearch-6.4.0/plugins/analysis-hanlp/data/dictionary/custom/CustomDictionary.txt.bin, 如果自定义词典变更了,一点要执行这一步,否则词典不生效
- 一定要重启es!!!一定要重启es!!!一定要重启es!!!
彩蛋
本文写完了中文分词器的作用和使用,下一篇将记录es客户端在项目中如何使用