深度学习(五)——DRN, Bi-directional RNN, Attention, seq2seq, DMN
https://antkillerfarm.github.io/
神经元激活函数进阶
ReLU的缺点(续)
为了解决上述问题,人们提出了Leaky ReLU、PReLU、RReLU、ELU、Maxout等ReLU的变种。
参考:
https://zhuanlan.zhihu.com/p/22142013
深度学习中的激活函数导引
http://blog.csdn.net/u012328159/article/details/69898137
几种常见的激活函数
https://mp.weixin.qq.com/s/Hic01RxwWT_YwnErsJaipQ
什么是激活函数?
其他激活函数
hard tanh

soft sign
Deep Residual Network
无论采用何种方法,可训练的神经网络的层数都不可能无限深。有的时候,即使没有梯度消失,也存在训练退化(即深层网络的效果还不如浅层网络)的问题。
最终2015年,微软亚洲研究院的何恺明等人,使用残差网络ResNet参加了当年的ILSVRC,在图像分类、目标检测等任务中的表现大幅超越前一年的比赛的性能水准,并最终取得冠军。
注:何恺明,清华本科+香港中文大学博士(2011)。先后在MS和Facebook担任研究员。
个人主页:http://kaiminghe.com/
残差网络的明显特征是有着相当深的深度,从32层到152层,其深度远远超过了之前提出的深度网络结构,而后又针对小数据设计了1001层的网络结构。
其简化版的结构图如下所示:

简单的说,就是把前面的层跨几层直接接到后面去,以使误差梯度能够传的更远一些。
DRN的基本思想倒不是什么新东西了,在2003年Bengio提出的词向量模型中,就已经采用了这样的思路。
参考:
https://zhuanlan.zhihu.com/p/22447440
深度残差网络
https://www.leiphone.com/news/201608/vhqwt5eWmUsLBcnv.html
何恺明的深度残差网络PPT
https://mp.weixin.qq.com/s/kcTQVesjUIPNcz2YTxVUBQ
ResNet 6大变体:何恺明,孙剑,颜水成引领计算机视觉这两年
https://mp.weixin.qq.com/s/5M3QiUVoA8QDIZsHjX5hRw
一文弄懂ResNet有多大威力?最近又有了哪些变体?
http://www.jianshu.com/p/b724411571ab
ResNet到底深不深?
Bi-directional RNN
众所周知,RNN在处理长距离依赖关系时会出现问题。LSTM虽然改进了一些,但也只能缓解问题,而不能解决该问题。
研究人员发现将原文倒序(将其倒序输入编码器)产生了显著改善的结果,因为从解码器到编码器对应部分的路径被缩短了。同样,两次输入同一个序列似乎也有助于网络更好地记忆。
基于这样的实验结果,1997年Mike Schuster提出了Bi-directional RNN模型。
注:Mike Schuster,杜伊斯堡大学硕士(1993)+奈良科技大学博士。语音识别专家,尤其是日语、韩语方面。Google研究员。
论文:
《Bidirectional Recurrent Neural Networks》
下图是Bi-directional RNN的结构示意图:

从图中可以看出,Bi-directional RNN有两个隐层,分别处理前向和后向的时序信息。
除了原始的Bi-directional RNN之外,后来还出现了Deep Bi-directional RNN。
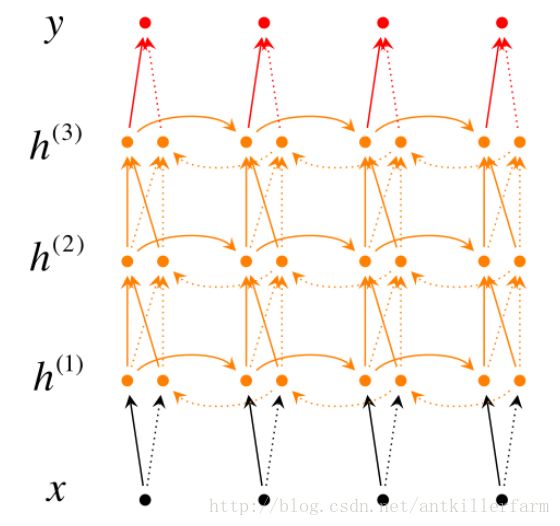
上图是包含3个隐层的Deep Bi-directional RNN。
参见:
https://mp.weixin.qq.com/s/_CENjzEK1kjsFpvX0H5gpQ
结合堆叠与深度转换的新型神经翻译架构:爱丁堡大学提出BiDeep RNN
Attention
倒序句子这种方法属于“hack”手段。它属于被实践证明有效的方法,而不是有理论依据的解决方法。
大多数翻译的基准都是用法语、德语等语种,它们和英语非常相似(即使汉语的词序与英语也极其相似)。但是有些语种(像日语)句子的最后一个词语在英语译文中对第一个词语有高度预言性。那么,倒序输入将使得结果更糟糕。
还有其它办法吗?那就是Attention机制。

上图是Attention机制的结构图。y是编码器生成的译文词语,x是原文的词语。上图使用了双向递归网络,但这并不是重点,你先忽略反向的路径吧。重点在于现在每个解码器输出的词语 yt 取决于所有输入状态的一个权重组合,而不只是最后一个状态。a是决定每个输入状态对输出状态的权重贡献。因此,如果 a3,2 的值很大,这意味着解码器在生成译文的第三个词语时,会更关注于原文句子的第二个状态。a求和的结果通常归一化到1(因此它是输入状态的一个分布)。
Attention机制的一个主要优势是它让我们能够解释并可视化整个模型。举个例子,通过对attention权重矩阵a的可视化,我们能够理解模型翻译的过程。
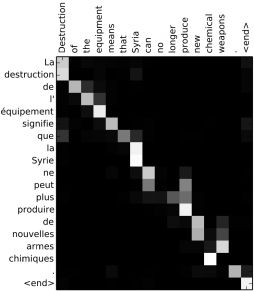
我们注意到当从法语译为英语时,网络模型顺序地关注每个输入状态,但有时输出一个词语时会关注两个原文的词语,比如将“la Syrie”翻译为“Syria”。
如果再仔细观察attention的等式,我们会发现attention机制有一定的成本。我们需要为每个输入输出组合分别计算attention值。50个单词的输入序列和50个单词的输出序列需要计算2500个attention值。这还不算太糟糕,但如果你做字符级别的计算,而且字符序列长达几百个字符,那么attention机制将会变得代价昂贵。
attention机制解决的根本问题是允许网络返回到输入序列,而不是把所有信息编码成固定长度的向量。正如我在上面提到,我认为使用attention有点儿用词不当。换句话说,attention机制只是简单地让网络模型访问它的内部存储器,也就是编码器的隐藏状态。在这种解释中,网络选择从记忆中检索东西,而不是选择“注意”什么。不同于典型的内存,这里的内存访问机制是弹性的,也就是说模型检索到的是所有内存位置的加权组合,而不是某个独立离散位置的值。弹性的内存访问机制好处在于我们可以很容易地用反向传播算法端到端地训练网络模型(虽然有non-fuzzy的方法,其中的梯度使用抽样方法计算,而不是反向传播)。
论文:
《Learning to combine foveal glimpses with a third-order Boltzmann machine》
《Learning where to Attend with Deep Architectures for Image Tracking》
《Neural Machine Translation by Jointly Learning to Align and Translate》
参考:
http://blog.csdn.net/malefactor/article/details/50550211
自然语言处理中的Attention Model
https://yq.aliyun.com/articles/65356
图文结合详解深度学习Memory & Attention
http://www.cosmosshadow.com/ml/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/2016/03/08/Attention.html
Attention
http://geek.csdn.net/news/detail/50558
深度学习和自然语言处理中的attention和memory机制
https://zhuanlan.zhihu.com/p/25928551
用深度学习(CNN RNN Attention)解决大规模文本分类问题-综述和实践
http://blog.csdn.net/leo_xu06/article/details/53491400
视觉注意力的循环神经网络模型
https://mp.weixin.qq.com/s/xr_1ZYbvADMMwgxLEAflCw
如何在语言翻译中理解Attention Mechanism?
https://mp.weixin.qq.com/s/Nyq_36aFmQYRWdpgbgxpuA
将注意力机制引入RNN,解决5大应用领域的序列预测问题
seq2seq
seq2seq最早用于Neural Machine Translation领域(与之相对应的有Statistical Machine Translation)。训练后的seq2seq模型,可以根据输入语句,自动生成翻译后的输出语句。

上图是seq2seq的结构图。可以看出seq2seq实际上是一种Encoder-Decoder结构。
在Encoder阶段,RNN依次读入输入序列。但由于这时,没有输出序列与之对应,因此这仅仅相当于一个对隐层的编码过程,即将句子的语义编码为隐层的状态向量。
从中发现一个问题:状态向量的维数决定了存储的语义的内容上限(显然不能指望,一个200维的向量,能够表示一部百科全书。)因此,seq2seq通常只用于短文本的翻译。
在Decoder阶段,我们根据输出序列,反向修正RNN的参数,以达到训练神经网络的目的。
参考:
https://github.com/ematvey/tensorflow-seq2seq-tutorials
一步步的seq2seq教程
http://blog.csdn.net/sunlylorn/article/details/50607376
seq2seq模型
http://datartisan.com/article/detail/120.html
Seq2Seq的DIY简介
http://www.cnblogs.com/Determined22/p/6650373.html
DL4NLP——seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)
http://blog.csdn.net/young_gy/article/details/73412285
基于RNN的语言模型与机器翻译NMT
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
The Unreasonable Effectiveness of Recurrent Neural Networks
https://mp.weixin.qq.com/s/8u3v9XzECkwcNn5Ay-kYQQ
基于Depthwise Separable Convolutions的Seq2Seq模型_SliceNet原理解析
https://mp.weixin.qq.com/s/H6eYxS7rXGDH_B8Znrxqsg
seq2seq中的beam search算法过程
https://mp.weixin.qq.com/s/U1yHIc5Zq0yKCezRm185VA
Attentive Sequence to Sequence Networks
https://mp.weixin.qq.com/s/cGXANj7BB2ktTdPAL4ZEWA
图解神经网络机器翻译原理:LSTM、seq2seq到Zero-Shot
DMN
Question answering是自然语言处理领域的一个复杂问题。它需要对文本的理解力和推理能力。大部分NLP问题都可以转化为一个QA问题。Dynamic Memory Networks可以用来处理QA问题。DMN的输入包含事实输入,问题输入,经过内部处理形成片段记忆,最终产生问题的答案。
DMN可进行端到端的训练,并在多种任务上取得了state-of-the-art的效果:包括QA(Facebook 的 bAbI 数据集),情感分析文本分类(Stanford Sentiment Treebank)和词性标注(WSJ-PTB)。

参考:
http://blog.csdn.net/javafreely/article/details/71994247
动态记忆网络