hadoop2.6.5 linux安装
hadoop linux安装流程
今天在自己的阿里云上安装了hadoop,安装过程中遇到了一些问题,特此做下笔记记录下。
1、下载安装包(下载地址)
http://mirror.bit.edu.cn/apache/hadoop/common/
在安装hadoop之前先配置下SSH免密码登录
查看ssh版本,通过命令ssh -version 进行验证,如果出现与下图相似的信息就代表已经安装了SSH了.
![]()
下面开始看看如何配置SSH免密码登录吧。
首先输入ssh localhost,验证在为配置前是无法通过ssh连接本机的

下面在用户目录下(笔者使用的是root用户,所以是/root目录,普通用户的文件夹是在/home,目录下与用户名相同的目录)ls -a ,可以看见有一个隐藏的文件夹.ssh,如果没有的话可以自行创建。然后输入一下命令,出现如下图示:
ssh-keygen -t dsa -P'' -f /root/.ssh/id_dsa
下一步将id_dsa.pub追加到授权的key中,键入一下命令:
cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys
此时,免密码登录本机就配置完成了,下面再次输入ssh localhost进行验证,出现下图所示信息代表配置成功了
2、开始安装hadoop
tar -zxvf hadoop-2.6.5.tar.gz
安装版本 2.6.5
重命名文件目录为hadoop
mv hadoop-2.6.5 hadoop
修改配置文件,路径
/data/soft/hadoop/etc/hadoop
修改环节变量 vi /etv/profile
export JAVA_HOME=/data/develop/jdk1.7.0_67
export JRE_HOME=/data/develop/jdk1.7.0_67/jre
export HADOOP_HOME=/data/soft/hadoop
export PATH=$PATH:/data/develop/jdk1.7.0_67/bin:$HADOOP_HOME$/bin
export CLASSPATH=./:/data/develop/jdk1.7.0_67/lib:/data/develop/jdk1.7.0_67/jre/lib
1:core-site.xml修改为
hadoop.tmp.dir
file:/data/soft/hadoop/tmp
Abase for Ardo hadoop.
fs.defaultFS
hdfs://localhost:9000
2:修改hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
file:/data/soft/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/data/soft/hadoop/tmp/dfs/data
/data/soft/hadoop/sbin目录下执行
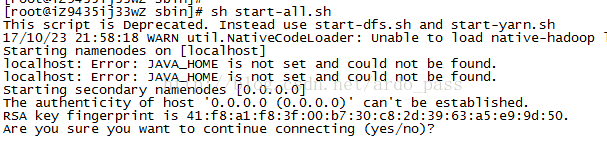
启动时报Error: JAVA_HOME is not set and could not be found.
解决办法:
修改/etc/hadoop/hadoop-env.sh中设JAVA_HOME。
应当使用绝对路径。
export JAVA_HOME=${JAVA_HOME} //文档原来的(错误)
export JAVA_HOME=/usr/java/jdk1.6.0_45 //正确,应该这么改
echo $JAVA_HOME$
然后改成:/data/develop/jdk1.7.0_67
改好后再到sbin目录下执行 sh start-all.sh

启动中报了很多Name or service not known的错误,这个并不是 ssh 的问题,可通过设置 Hadoop 环境变量来解决。首先按键盘的 ctrl + c 中断启动,修改配置:
cd /data/soft/hadoop/etc/hadoop
vi hadoop-env.sh
然后再次执行sh start-all.sh,启动后通过jps查看多了进程

--修改配置文件mapred-site.xml,以备启动YARN
/data/soft/hadoop/etc/hadoop目录下执行修改命令:
mv mapred-site.xml.template mapred-site.xml
修改配置文件vi mapred-site.xml
mapreduce.framework.name
yarn
接着修改vi yarn-site.xml
然后就可以启动YARN了,需要先执行过sh start-dfs.sh
接着sh start-yarn.sh

开启历史服务器,才能在web中查看任务运行情况,执行如下命令:
sh mr-jobhistory-daemon.sh start historyserver
开启后通过 jps 查看,可以看到多了 NodeManager 和 ResourceManager 两个后台进程

在浏览器中输入URL : http://120.76.xxx.xx:8088/cluster
