Waterdrop:构建在Spark之上的简单高效数据处理系统
本文来自 Gary和RickyHuo,他们是Waterdrop开发者,从事大数据相关工作多年,熟悉Hadoop技术体系,参与过多个大数据开源项目,目前分别供职于一下科技和新浪。
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,我们在此与大家分享一下我们在简化Spark使用和编程以及加快Spark在生产环境落地上做的一些努力。

一个Spark Streaming读取Kafka的案例
以一个线上案例为例,介绍如何使用Spark Streaming统计Nginx后端日志中每个域名下每个状态码每分钟出现的次数,并将结果数据输出到外部数据源Elasticsearch中。其中原始数据已经通过Rsyslog传输到了Kafka中。
数据读取
从Kafka中每隔一段时间读取数据,生成DStream

具体方法参考Spark Streaming + Kafka Integration Guide。
数据清洗
日志案例
通过Split方法从非结构化的原始数据message中获取域名以及状态码字段,并组成方便聚合的结构化数据格式Map(key -> value)

数据聚合
利用Spark提供的reduceByKey方法对数据进行聚合计算,统计每分钟每个域名下的每个错误码出现的次数,其中mapRdd是在清洗数据阶段组成的RDD
![]()
数据输出
利用Spark提供的foreachRDD方法将结果数据reduceRdd输出到外部数据源Elasticsearch

问题
我们的确可以利用Spark提供的API对数据进行任意处理,但是整套逻辑的开发是个不小的工程,需要一定的Spark基础以及使用经验才能开发出稳定高效的Spark代码。除此之外,项目的编译、打包、部署以及测试都比较繁琐,会带来不少得时间成本和学习成本。
除了开发方面的问题,数据处理时可能还会遇到以下不可逃避的麻烦:
数据丢失与重复
任务堆积与延迟
吞吐量低
应用到生产环境周期长
缺少应用运行状态监控
因此我们开始尝试更加简单高效的Spark方案,并试着解决以上问题
一种简单高效的方式 -- Waterdrop
Waterdrop 是一个非常易用,高性能,能够应对海量数据的实时数据处理产品,构建于Apache Spark之上。
Waterdrop 项目地址:https://interestinglab.github.io/waterdrop
Spark固然是一个优秀的分布式数据处理工具,但是正如上文所表达的,Spark在我们的日常使用中还是存在不小的问题。因此我们也发现了我们的机会 —— 通过我们的努力让Spark的使用更简单,更高效,并将业界和我们使用Spark的优质经验固化到Waterdrop这个产品中,明显减少学习成本,加快分布式数据处理能力在生产环境落地
"Waterdrop" 的中文是“水滴”,来自中国当代科幻小说作家刘慈欣的《三体》系列,它是三体人制造的宇宙探测器,会反射几乎全部的电磁波, 表面绝对光滑,温度处于绝对零度,全部由被强互作用力紧密锁死的质子与中子构成,无坚不摧。 在末日之战中,仅一个水滴就摧毁了人类太空武装力量近2千艘战舰。
Waterdrop 的特性
简单易用,灵活配置,无需开发;可运行在单机、Spark Standalone集群、Yarn集群、Mesos集群之上。
实时流式处理, 高性能, 海量数据处理能力
模块化和插件化,易于扩展。Waterdrop的用户可根据实际的需要来扩展需要的插件,支持Java/Scala实现的Input、Filter、Output插件。
如果您对插件扩展感兴趣,可移步至Waterdrop插件开发支持利用SQL做数据处理和聚合
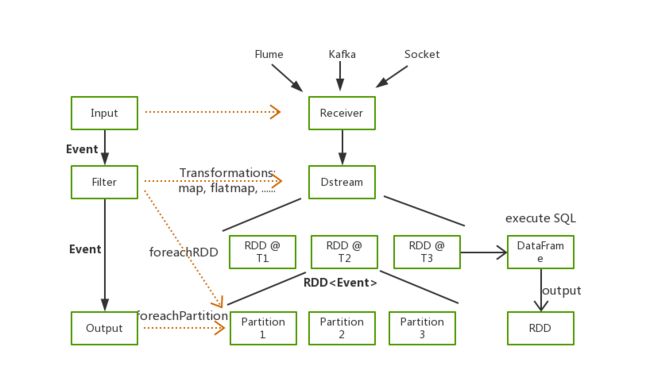
Waterdrop 的原理和工作流程
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
Waterdrop 利用了Spark的Streaming, SQL, DataFrame等技术,Java的反射机制、Service Loader等技术以及Antlr4的语法解析技术, 实现了一套完整的可插拔的数据处理工作流,如下:

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
多个Filter构建了数据处理的Pipeline,满足各种各样的数据处理需求,如果您熟悉SQL,也可以直接通过SQL构建数据处理的Pipeline,简单高效。 目前Waterdrop支持的Filter列表(数据处理插件), 仍然在不断扩充中。 您也可以开发自己的数据处理插件,整个系统是易于扩展的。通过下面的配置示例,你可以快速了解到这种工作流程:

spark是spark相关的配置,可配置的spark参数见: Spark Configuration, 其中master, deploy-mode两个参数不能在这里配置,需要在Waterdrop启动脚本中指定。
input可配置任意的input插件及其参数,具体参数随不同的input插件而变化。input支持包括File, Hdfs, Kafka, S3, Socket等插件。
filter可配置任意的filter插件及其参数,具体参数随不同的filter插件而变化。filter支持包括Date, Json, Split, Sql, Table, Repartition等40+个插件。filter中的多个插件按配置顺序形成了数据处理的pipeline, 上一个filter的输出是下一个filter的输入。
output可配置任意的output插件及其参数,具体参数随不同的output插件而变化。
filter处理完的数据,会发送给output中配置的每个插件。output支持包括Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, S3等插件。
如何使用 Waterdrop
Step 1 : 使用 Waterdrop前请先准备好Spark和Java运行环境。
Step 2 : 下载Waterdrop安装包 并解压:

Step 3 : 配置 Waterdrop(从kafka消费数据,做字符串分割,输出到终端), 编辑 config/application.conf

Step 4 : 启动 Waterdrop
![]()
更详细的使用方法见Waterdrop Quick Start
Waterdrop 未来发展路线
Waterdrop 会分为3条路线,详细展开:
提供更多Input, Filter, Output插件,提高易用性、可靠性、数据一致性。
支持Apache Flink / Apache Beam,支持Spark以外的分布式数据计算模型。
支持流式机器学习,能够通过简单的Pipeline和配置,完成常用流式机器学习模型的训练。
Waterdrop 项目由Interesting Lab开源。Interesting Lab (https://github.com/InterestingLab), 中文译名有趣实验室。成立于2016年,致力于让大数据变得更简单有价值。
猜你喜欢
欢迎关注本公众号:iteblog_hadoop:
0、回复 电子书 获取 本站所有可下载的电子书
1、三种恢复 HDFS 上删除文件的方法
2、流计算框架 Flink 与 Storm 的性能对比
3、盘点2017年晋升为Apache TLP的大数据相关项目
4、干货 | Spark SQL:过去,现在以及未来
5、Apache Spark 黑名单(Blacklist)机制介绍
6、Apache Hadoop 3.0.0 GA版正式发布,可以部署到线上
7、干货 | Apache Spark最佳实践
8、NodeManager节点自身健康状态检测机制
9、[干货]大规模数据处理的演变(2003-2017)
10、Apache Flink 1.3.0正式发布及其新功能介绍
11、更多大数据文章欢迎访问https://www.iteblog.com及本公众号(iteblog_hadoop) 12、Flink中文文档:http://flink.iteblog.com
点击下面阅读原文进入Waterdrop项目页面立即体验。