Python 中的DataFrame合并,删除指定列等基本操作
1. 两个dataframe的合并,看这个博客
https://blog.csdn.net/zutsoft/article/details/51498026
merge 通过键拼接列
这个很常用,类似于数据库中的方法。
merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
用于通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN。该函数的典型应用场景是,针对同一个主键存在两张包含不同字段的表,现在我们想把他们整合到一张表里。在此典型情况下,结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量。
on=None 用于显示指定列名(键名),如果该列在两个对象上的列名不同,则可以通过 left_on=None, right_on=None 来分别指定。或者想直接使用行索引作为连接键的话,就将 left_index=False, right_index=False 设为 True。
how='inner' 参数指的是当左右两个对象中存在不重合的键时,取结果的方式:inner 代表交集;outer 代表并集;left 和 right 分别为取一边。
suffixes=('_x','_y') 指的是当左右对象中存在除连接键外的同名列时,结果集中的区分方式,可以各加一个小尾巴。
对于多对多连接,结果采用的是行的笛卡尔积。
参数说明:
left与right:两个不同的DataFrame
how:指的是合并(连接)的方式有inner(内连接),left(左外连接),right(右外连接),outer(全外连接);默认为inner
on : 指的是用于连接的列索引名称。必须存在右右两个DataFrame对象中,如果没有指定且其他参数也未指定则以两个DataFrame的列名交集做为连接键
left_on:左则DataFrame中用作连接键的列名;这个参数中左右列名不相同,但代表的含义相同时非常有用。
right_on:右则DataFrame中用作 连接键的列名
left_index:使用左则DataFrame中的行索引做为连接键
right_index:使用右则DataFrame中的行索引做为连接键
sort:默认为True,将合并的数据进行排序。在大多数情况下设置为False可以提高性能
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x','_y')
copy:默认为True,总是将数据复制到数据结构中;大多数情况下设置为False可以提高性能
indicator:在 0.17.0中还增加了一个显示合并数据中来源情况;如只来自己于左边(left_only)、两者(both)
all_features_1 = pd.merge(vce_static, ice_static, left_index=True, right_index=True, suffixes=('_Vce', '_Ice'))
all_features_2 = pd.merge(vge_static, vgsignal_static, left_index=True, right_index=True, suffixes=('_Vge', '_Vgsignal'))还有join 和 concat 之后用到了再写。
2.DataFrame删除行和列
https://blog.csdn.net/weiyongle1996/article/details/77984485?skintest=skin3-template-test#commentBox
.drop()方法如果不设置参数inplace=True,则只能在生成的新数据块中实现删除效果,而不能删除原有数据块的相应行。如果inplace=True则原有数据块的相应行被删除。
data = odata.drop([16,17])
odata删除列:
del 方法
del all_features['Uce_peak'], all_features['max_list_Vce'], all_features['min_list_Vce']
.pop()方法
.pop方法可以将所选列从原数据块中弹出,原数据块不再保留该列
spring = odata.pop('spring').drop()方法
drop方法既可以保留原数据块中的所选列,也可以删除,这取决于参数inplace
withoutSummer = odata.drop(['summer'],axis=1)当inplace=True时.drop()执行内部删除,不返回任何值,原数据发生改变
总结,不论是行删除还是列删除,也不论是原数据删除,还是输出新变量删除,.drop()的方法都能达到目的,为了方便好记,熟练操作,所以应该尽量多使用.drop()方法
3.DataFrame改变列名
https://www.cnblogs.com/hhh5460/p/5816774.html
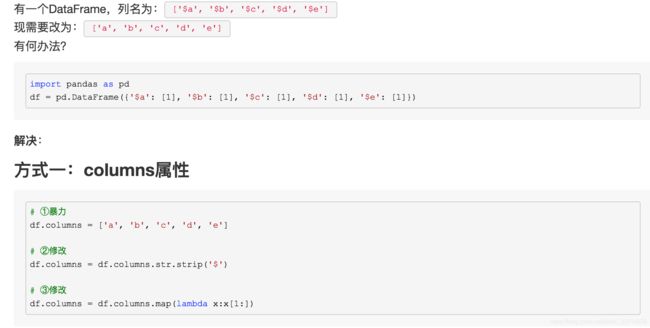

all_features.rename(columns = {'max': 'max_IceSteady', 'mean': 'mean_IceSteady',
'min': 'min_IceSteady', 'standard_diviation': 'standard_diviation_IceSteady',
'variance': 'variance_IceSteady'}, inplace = True)