在TensorFlow中保存已经训练好的神经网络模型
通常,训练一个具有一定实用价值的深度神经网络是非常消耗计算时间的。所以在使用时,最好的方法是导入已经训练好的模型,重用它,而不是每次都重新训练。
如果要在TensorFlow中保存已经训练好的神经网络模型,所需的核心方法就是Saver.save,它位于Saver类中:
- Saver类提供了向checkpoints文件保存和从checkpoints文件中恢复变量的相关方法。Checkpoints文件是一个二进制文件,它把变量名映射到对应的tensor值 。
- 只要提供一个计数器,当计数器触发时,Saver类可以自动的生成checkpoint文件。这让我们可以在训练过程中保存多个中间结果。例如,我们可以保存每一步训练的结果。
- 为了避免填满整个磁盘,Saver可以自动的管理Checkpoints文件。例如,我们可以指定保存最近的N个Checkpoints文件。
将训练好的模型参数保存起来,以便以后进行验证或测试,这是我们经常要做的事情。模型保存,先要创建一个Saver对象,如:
saver=tf.train.Saver()saver=tf.train.Saver(max_to_keep=0)但是这样做除了多占用硬盘,并没有实际多大的用处,因此不推荐。
当然,如果你只想保存最后一代的模型,则只需要将max_to_keep设置为1即可,即
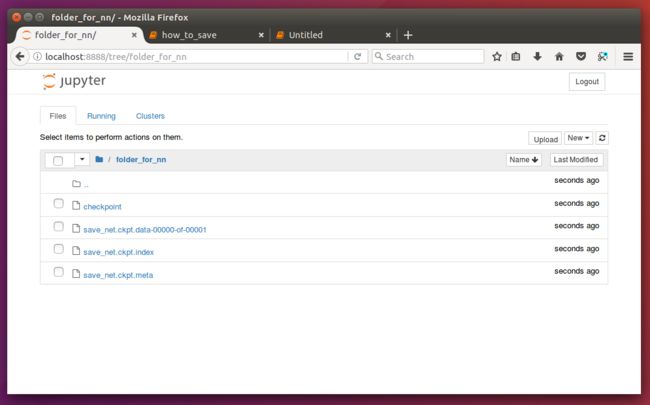
saver=tf.train.Saver(max_to_keep=1)saver.save(sess,'folder_for_nn/save_net.ckpt',global_step=step)第一个参数sess,这个就不用说了。第二个参数设定保存的路径和名字,第三个参数将训练的次数作为后缀加入到模型名字中。
saver.save(sess, 'my-model', global_step=0) ==> filename: 'my-model-0'
...
saver.save(sess, 'my-model', global_step=1000) ==> filename: 'my-model-1000'
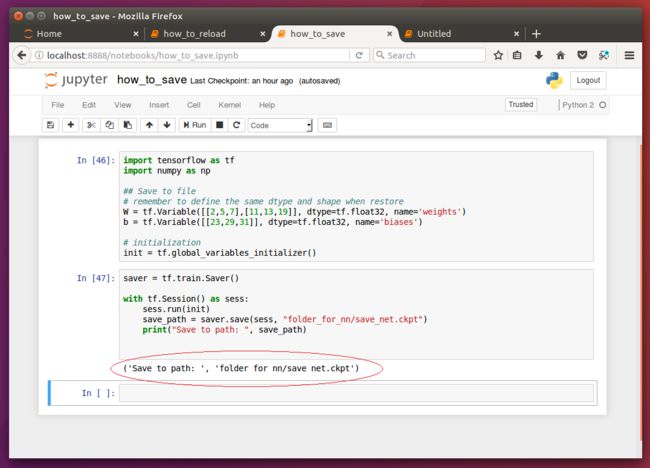
来看一段简单的示例代码:
import tensorflow as tf
import numpy as np
## Save to file
# remember to define the same dtype and shape when restore
W = tf.Variable([[2,5,7],[11,13,19]], dtype=tf.float32, name='weights')
b = tf.Variable([[23,29,31]], dtype=tf.float32, name='biases')
# initialization
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
save_path = saver.save(sess, "folder_for_nn/save_net.ckpt")
print("Save to path: ", save_path)
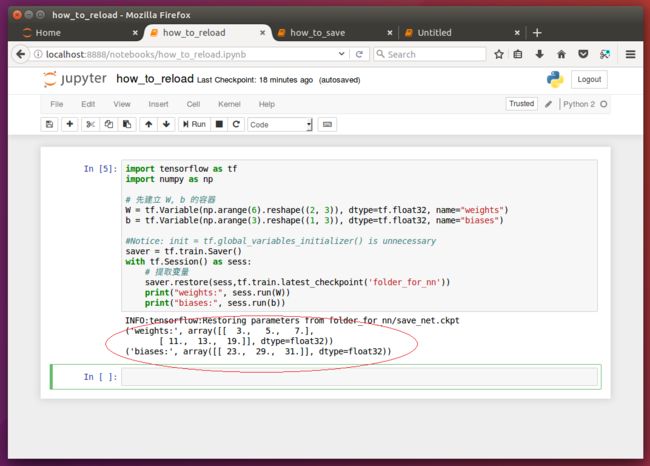
import tensorflow as tf
import numpy as np
# 先建立 W, b 的容器
W = tf.Variable(np.arange(6).reshape((2, 3)), dtype=tf.float32, name="weights")
b = tf.Variable(np.arange(3).reshape((1, 3)), dtype=tf.float32, name="biases")
#Notice: init = tf.global_variables_initializer() is unnecessary
saver = tf.train.Saver()
with tf.Session() as sess:
# 提取变量
saver.restore(sess,tf.train.latest_checkpoint('folder_for_nn'))
print("weights:", sess.run(W))
print("biases:", sess.run(b))最开始我们的为模型参数变量灌入的值,在读取文件成功后,已经被替换成了之前存储的模型产生。如下面的执行结果所示。
参考文献及推荐阅读材料:
http://www.cnblogs.com/denny402/p/6940134.html
(本文完)