目标检测中的评估指标mAP等
评价指标:
准确率 (Accuracy),混淆矩阵 (Confusion Matrix),精确率(Precision),召回率(Recall),平均正确率(AP),mean Average Precision(mAP),交除并(IoU)
1.交并比IoU
目前目标检测领域主要使用IoU来衡量两个检测框的相似度,顾名思义,IoU表示两个集合的交集占其并集的比例。
公式中,和分别表示预测框和真实标记框,IoU取值范围在之间,0表示两个包围框没有任何重叠部分,1表示两个包围框完全重合,IoU值越大,表示预测结果与真实标记框相似度越高,也意味着定位精度越精确,IoU超过一定阈值才会被认为检测正确。IoU的概念类似于数学领域的Jaccard指数。
2.混淆矩阵
混淆矩阵中的横轴是模型预测的类别数量统计,纵轴是数据真实标签的数量统计。对角线,表示模型预测和数据标签一致的数目,所以对角线之和除以测试集总数就是准确率。对角线上数字越大越好,在可视化结果中颜色越深,说明模型在该类的预测准确率越高。如果按行来看,每行不在对角线位置的就是错误预测的类别。总的来说,我们希望对角线越高越好,非对角线越低越好。
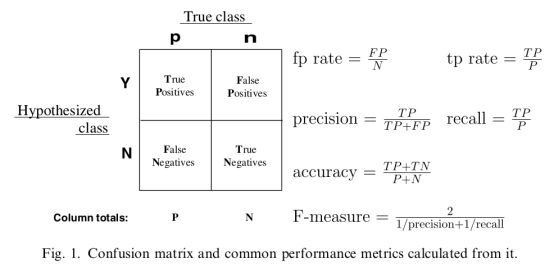
一些相关的定义。假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,假设系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
True positives : 正样本被正确识别为正样本,飞机的图片被正确的识别成了飞机。
True negatives: 负样本被正确识别为负样本,大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives: 假的正样本,即负样本被错误识别为正样本,大雁的图片被错误地识别成了飞机。
False negatives: 假的负样本,即正样本被错误识别为负样本,飞机的图片没有被识别出来,系统错误地认为它们是大雁。
FP Rate(FPR):false positive占整个negative的比例,就是说原本是negative 预测为positive的比例,越小越好
TP Rate(TPR): true positive 占整个positive 的比例
精确率Precision其实就是在识别出来的图片中,True positives所占的比率。也就是本假设中,所有被识别出来的飞机中,真正的飞机所占的比例。
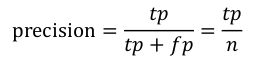
准确率Accuracy是预测正确的样本数占全部样本数的比例,将对角线元素加和得到所有预测正确的个数,除以总样本数就得到了准确率
accuracy = (TP+TN) / (TP+TN+FP+FN)
召回率Recall 是测试集中所有正样本样例中,被正确识别为正样本的比例。也就是本假设中,被正确识别出来的飞机个数与测试集中所有真实飞机的个数的比值。

Precision-recall 曲线:横坐标是recall,纵坐标是precosion,改变识别阈值,使得系统依次能够识别前K张图片,阈值的变化同时会导致Precision与Recall值发生变化,从而得到曲线。
如果一个模型的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的模型可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出模型在Precision与Recall之间的权衡。
3.平均精度(mAP)
mAP是每个类别AP的平均值,AP是PR曲线下的面积。单纯地用Precision和Recall来评价整个检测器并合理,因为有的检测任务要求更高的Recall,错检几个影响不大;有的检测任务则要求更高Precision,漏检几个影响不大。因此需要对Precision和Recall做一个整体的评估,而这个评估就是AP(Average Precision),其定义非常简单,对排序好的检测结果进行“截取”,依次观察检测结果的前1个(也就是只有第一个结果)、前2个、...、前N个,每次观察都能够得到一个对应的P和R,随着观察数量的增大,R一定会变大或不变。因此可以以R为横轴,P为纵轴,将每次的“截取”观察到的P和R画成一个点(R,P)。值得注意的是,当“截取”到的新结果为FP时,因为R没有变化所以并不会有新的(R,P)点产生。最后利用这些(R,P)点绘制成P-R曲线,定义:
通俗地讲,AP就是这个P-R曲线下的面积。AP计算了不同Recall下的Precision,综合性地评价了检测器,并不会对P和R有任何偏好,同时,检测分数越高的结果对AP的影响越大,分数越低的对AP的影响越小。
实际中在计算AP时,都要对P-R曲线做一次修正,将P值修正为当R>R0时最大的P(R0即为该点对应的R),即
下图即为修正前P-R曲线和修正后P-R曲线。
如上图,蓝色实曲线为原始P-R曲线、橘色虚曲线为修正后P-R曲线。因为评价检测性能时,更应该关心当R大于某个值时,能达到的最高的P是多少、而不是当R等于某个值时,此时的P是多少。
计算出每个类别的AP,对所有类别求平均即可得到该数据集的mAP(mAP是针对某一个数据集的计算指标),
4.mmAP
第3点的mAP是Pascal VOC数据集的评估方式,只有一个IoU阈值(thresh=0.5),只要检测结果框与真实框之间的IoU大于0.5将被认为检测正确,在某些场景评估结果可能不够精细。
在MSCOCO数据集中,设置一组IOU阈值,这组阈值为 (0.5, 0.55, 0.6, ..., 0.9, 0.95),一共10个阈值,如果检测结果框与真实框的IOU超过阈值,则视作检测成功。这样每给定一个阈值就可以计算出一个性能(也就是mAP),然后对这些性能取平均(也就是mmAP)。mmAP将更能体现整个检测模型的性能,尤其是高精度的性能(即在阈值较大情况下的mAP)。
5. 代码参考
VOC数据集map的计算方式分为07和10两个版本,gluoncv的实现方式https://github.com/dmlc/gluon-cv/blob/master/gluoncv/utils/metrics/voc_detection.py
COCO数据集的map计算方式有点复杂,一般是直接使用COCOAPI计算。gluoncv的例子参考https://github.com/dmlc/gluon-cv/blob/master/gluoncv/utils/metrics/coco_detection.py
参考
- M. Everingham, S. M. Eslami, Van Gool L, et al. The Pascal Visual Object Classes Challenge: A Retrospective[J]. International Journal of Computer Vision, 2015, 111(1): 98-136
- M. Everingham, L. Van Gool, C. K. Williams, et al. The Pascal Visual Object Classes (VOC) Challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338
- T. Lin, M. Maire, S. Belongie, et al. Microsoft coco: Common objects in context[C]. European conference on computer vision, 2014: 740-755
- https://zhuanlan.zhihu.com/p/55575423
- https://www.zhihu.com/question/53405779/answer/419532990