初识Spark 1.6.0
1、 Spark发展背景
Spark由加州大学伯克利分校AMP实验室(Algorithms,Machines,andPeopleLab)以Matei为主的小团队使用Scala语言所开发,后期成立spark商业公司databricks,CEOAli,CTO Matei,后期愿景是实现databrickscloud。Spark是新一代基于内存迭代计算的、开源的、分布式的、并行的计算框架,抛去繁琐的IO读写,目的是让数据分析更加快速。
2、 Spark和mapreduce的区别
1)、MR作业的资源管控是通过yarn进行的,spark可以通过yarn进行资源管控,也可以不使用yarn,但是多个组件合设时,建议还是使用yarn;
2)、spark是基于内存计算的,计算的中间结果存放在内存,可以进行反复迭代计算;而MR计算的中间结果是要落磁盘的,所以一个job会涉及到反复读写磁盘,这也是性能比不上spark的主要原因;
3)、MR的一个task就要对应一个container,container的每次启动都要耗费不少时间,而spark是基于线程池来实现的,资源的分配会更快一些。
3、 Spark系统架构图
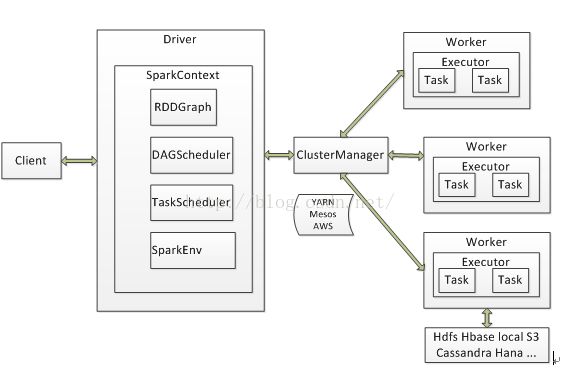
Spark架构中的基本组件:
ClusterManager:在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为资源管理器。
Worker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。
Driver:运行Application的main()函数并创建SparkContext。
Executor:执行器,在workernode上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
SparkContext:整个应用的上下文,控制应用的生命周期。
RDD:Spark的基本计算单元,一组RDD可形成执行的有向无环图RDDGraph。
DAGScheduler:根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。
TaskScheduler:将任务(Task)分发给Executor执行。
SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。
SparkEnv内创建并包含如下一些重要组件的引用。
MapOutPutTracker:负责Shuffle元信息的存储。
BroadcastManager:负责广播变量的控制与元信息的存储。
BlockManager:负责存储管理、创建和查找块。
MetricsSystem:监控运行时性能指标信息。
SparkConf:负责存储配置信息。
Spark的整体流程为:Client提交应用,Master找到一个Worker启动Driver,Driver向Master或者资源管理器申请资源,之后将应用转化为RDDGraph,再由DAGScheduler将RDDGraph转化为Stage的有向无环图提交给TaskScheduler,由TaskScheduler提交任务给Executor执行。在任务执行的过程中,其他组件协同工作,确保整个应用顺利执行。
4、 Spark任务调度流程
作业执行流程描述:
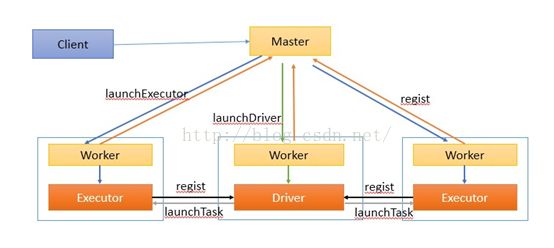
客户端提交作业给Master,Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。另外Master还会让其余Worker启动Exeuctor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序,生成执行计划,并调度执行。对于每个stage的task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报的时候把TaskScheduler中的task调度到ExecutorBackend执行。所有stage都完成后作业结束。
5、 什么是RDD?
RDD,全称为Resilient DistributedDatasets(弹性分布式数据集),是一个只读的、有容错机制的、并行的、分布式的数据集合。RDD可以全部缓存在内存中,可以迭代计算,RDD是Spark最核心的东西。同时,RDD还提供了一组丰富的操作来操作这些数据。在这些操作中,诸如map、flatMap、filter等转换操作实现了monad模式,很好地契合了Scala的集合操作。除此之外,RDD还提供了诸如join、groupBy、reduceByKey等更为方便的操作(注意,reduceByKey是action,而非transformation),以支持常见的数据运算。
通常来讲,针对数据处理有几种常见模型,包括:IterativeAlgorithms,RelationalQueries,MapReduce,StreamProcessing。例如HadoopMapReduce采用了MapReduces模型,Storm则采用了StreamProcessing模型。RDD混合了这四种模型,使得Spark可以应用于各种大数据处理场景。
RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以相互依赖。如果RDD的每个分区最多只能被一个ChildRDD的一个分区使用,则称之为narrowdependency;若多个ChildRDD分区都可以依赖,则称之为widedependency。不同的操作依据其特性,可能会产生不同的依赖。例如map操作会产生narrowdependency,而join操作则产生widedependency。
Spark之所以将依赖分为narrow与wide,基于两点原因:
首先,narrowdependencies可以支持在同一个clusternode上以管道形式执行多条命令,例如在执行了map后,紧接着执行filter。相反,widedependencies需要所有的父分区都是可用的,可能还需要调用类似MapReduce之类的操作进行跨节点传递。
其次,则是从失败恢复的角度考虑。narrowdependencies的失败恢复更有效,因为它只需要重新计算丢失的parentpartition即可,而且可以并行地在不同节点进行重计算。而widedependencies牵涉到RDD各级的多个ParentPartitions。下图说明了narrowdependencies与widedependencies之间的区别:
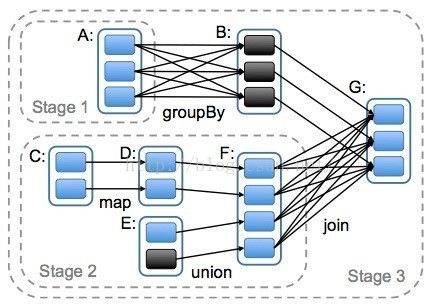
图中,一个box代表一个RDD,一个带阴影的矩形框代表一个partition。
RDD是Spark的核心,也是整个Spark的架构基础。它的特性可以总结如下:
- 它是不变的数据结构存储
- 它是支持跨集群的分布式数据结构
- 可以根据数据记录的key对结构进行分区
- 提供了粗粒度的操作,且这些操作都支持分区
- 它将数据存储在内存中,从而提供了低延迟性
6、 什么是DAG?
DAG(Directed AcyclicalGraphs)有向无环图,它是一个简单的使用DAG实现容错的方法。在作业失败的情况下,你可以很容易地通过图形走回头路,甚至在计算的中间阶段,你也可以重新执行任何失败的任务。图的执行顺序总是可以让你从图中的任何节点走到最终结束的节点。
7、 Why Scala?
1、spark和scala真的是非常完美的配搭,RDD的很多思想与scala类似,如完全相同概念List的map、filter等高阶算子,很短的代码就可以实现java很多行的功能;类似于fp中的不可变及惰性计算,使得分布式的内存对象rdd可以实现,同时可以实现pipeline;
2、scala善于借力,如设计初衷就包含对于jvm的支持,所以可以很完美的借java的生态力量;spark一样,很多东西不要自己写,直接使用、借鉴,如直接部署在yarn、mesos、ec2,使用hdfs、s3,借用hive中的sql解析部分;
3、还有Scala方便开发高效的网络通讯
8、Spark Release1.6.0新特性
这是spark发布的第七版,这一版本主要的新特性包括以下几方面:
1). Dataset API
目前Spark有两大类API:RDD API(SparkCore),DataFrame API(SparkSQL)
RDD API非常灵活,但是某些情况下执行计划很难被优化。
DataFrame API便于优化,但是操作UDF(UerDefineFunction)就比较麻烦。
DatasetAPI诞生在这样的背景下,需要兼顾以上两者的优点,既能使用户能够简洁清晰的描述UDF,又能够便于底层catalyst对执行计划的优化,
2).SessionManagement
集群可以被共享给多个拥有不同配置及临时表的用户,在1个SparkContext中可以有多个SparkSQL的session。之前在使用1.4的时候发现很多SQL下到底层最后都是顺序执行,而且SQL到SQLContext的调度是自己写线程池去处理的,
加入Session管理会给使用提供更大的方便,尤其在处理多并发时。
3).Per-operatorMetricsforSQLExecution
Spark的metrics已经详细到task及stage上,在上面可以看到很多任务运行的指标,如任务耗时,处理的数据量,等等,之前通过Metrics提供的信息发现了任务运行时间长的原因。新的特性是在SparkSQL运行时,为每个操作单位提供内存使用量和溢出(这里应该是指在磁盘和内存上交换的)数据大小的统计显示,这对于开发者了解资源,发现问题,做出调整很有帮助
4).SQLQueriesonFiles
SQL可以直接在符合数据规则的文件上进行查询,不再像以前需要先将文件注册成临时表
5.Readingnon-standardJSONfiles
Spark在处理JSON时使用的Jackson包,这次将Jackson包的以下选项开放给使用者
ALLOW_COMMENTS
ALLOW_UNQUOTED_FIELD_NAMES
ALLOW_SINGLE_QUOTES
ALLOW_NUMERIC_LEADING_ZEROS
ALLOW_NON_NUMERIC_NUMBERS
6).AdvancedLayoutofCachedData
在对内存表进行扫描时,存储分区和排序方案,同时在DataFrame中添加了根据指定列进行分发和本地排序的API
7).AllprimitiveinjsoncanbeinfertoStrings
通过设置primitivesAsString为true,可以将JSON中的所有原语在Dataframe中指定为字符串类型,即JSON中的数据在Dataframe中统一为字符串