Scala2.11.8 + Sbt + Maven + IntelliJ Idea + Spark2.0开发环境搭建备忘
已有hadoop yarn 和 spark 集群部署、运行在分布式环境中,程序开发编码在PC上,由于逐渐增多scala编写spark2.0程序,入乡随俗使用sbt和IntelliJ Idea,顺便对PC上的Scala + sbt + maven + IntelliJ Idea一些要注意的开发环境配置细节进行记录,侧重于现在网上比较少总结又可能让人有些困扰的部分,目前这方面总结比较完整的文章好像还比较少(也可能是自己看的不够多),有些内容也是google国外和自己摸索的,在此进行记录,一方面方便跟可能有同样需求的程序猿们讨论交流,一方面给做个备忘记录。
整体上主要是以下几个步骤。
1. Java JDK 安装与配置
2. Scala2.11.8 安装与配置
3. maven 安装与配置设置文件
4. sbt 安装与配置sbt-lauch.jar包
5. 集成开发环境IDE IntelliJ Idea 安装与配置插件
6. 通过sbt依赖创建 Spark2.0 项目
1. Java JDK 安装与配置
官网下载对应操作系统的安装包,做好环境变量配置,命令行java 相关命令成功执行,网上很多参考文档,不多叙述。
2. Scala 安装与配置
官网下载对应操作系统的安装包,做好环境变量配置,命令行scala相关命令成功执行,网上很多参考文档,不多叙述。
3. maven 安装与配置设置文件
maven或sbt等开发管理软件的使用,在开发中能够较为系统的生成开发目录结构,管理依赖关系,帮开发人员节省时间,提高效率,当然具体使用与否还是看个人实际开发情况选择,没有maven或sbt等管理软件也可以照样开发。
官网下载对应操作系统的安装包,解压到自己设定的目录,成功执行mvn相关命令。
(1)由于国内连接默认maven仓库,网络状况和速度是个老大难问题,可以在maven目录下conf/settings.xml文件配置修改
(2)本地下载保存依赖的目录路径,默认是.m2下面(Linux用户家目录里面,Windows C盘用户目录里面),可以改为其他指定目录,修改conf/settings.xml文件,
(3)这时候没有安装IDE,可以通过mvn命令生成maven项目,修改pom.xml,管理项目依赖包,进行代码编写,编辑器自选。
4. sbt 安装与配置sbt-lauch.jar包
为了进行scala+spark的开发,入乡随俗使用sbt,官网下载对应操作系统的安装包,解压或安装到自己设定的目录,成功执行sbt相关命令。
(1)同样的,sbt国内连接默认仓库,网速老大难,下载过程极其缓慢,测速可低至0-2KB/S,典型小水管,还有可能中途连接被断开,所以同样需要做更改仓库镜像的尝试。
修改的方法有几种不同的方式,考虑到最终调用的是sbt路径下的bin/sbt-launch.jar,这里采用了直接修改sbt-launch.jar的方式。
先复制备份原有sbt-launch.jar文件,再打开当前修改编辑的sbt-launch.jar中的sbt/sbt.boot.properties,这里修改了[repositories]的local部分, maven-central没有改,添加了几个网上找的镜像源,都加上去了,也不一定是最快的,速度目前在个人可接受范围内。
aliyun-nexus: http://maven.aliyun.com/nexus/content/groups/public/
ibiblio-maven: http://maven.ibiblio.org/maven2/
typesafe-ivy: https://dl.bintray.com/typesafe/ivy-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]
uk-repository: http://uk.maven.org/maven2/
jboss-repository: http://repository.jboss.org/nexus/content/groups/public/
(2)sbt使用了ivy,默认将依赖包保存在家目录或C盘用户目录.ivy下面,如果觉得默认路径不合适,可以把sbt.boot.properties文件的[boot]和[ivy]目录修改为指定目录,比如ivy-home是cache依赖包路径,打比方可以改为/home/user/.../ivy-home/ 或者 F:\...\ivy-home\,然后指定路径下生成的cache目录将具体存储sbt项目依赖包。
(3)使用sbt命令生成项目模板,可以编写build.sbt,进行依赖管理。
5. 集成开发环境IDE IntelliJ Idea 安装与配置插件
上面的开发环境配置完成,已可以进行项目开发,个人觉得没有结合IDE使用来的方便,scala、java开发IDE选择见仁见智,IntelliJ Idea比较适合本人口味。
官网下载对应操作系统的安装包,对比免费和付费版本功能,免费的community版一般够用了,解压或安装到指定路径。
(1)打开IntelliJ Idea,在弹出的启动界面中,先进行默认的项目配置(注意是default project配置,以后每个生成的当前项目current project都会先采用该默认配置),包括插件安装、参数配置等。打开可见目前安装的版本属于2016.2,截图界面中,选择configure中的settings。

(2) 左侧选择plugins,默认已自带maven插件,在browse repositories输入scala,查找并下载安装scala插件,同样完成sbt插件安装。IDE下载这些插件的作用通常是用于连接IDE和对应的软件,比如上面已装好的scala,sbt,maven,通过插件方便在IDE调用已装软件的命令和功能,有效地进行开发。
(3)插件安装完成后,点击左侧Build, Execution, Deployment,在Build Tools里面分别maven和sbt插件进行设置,确保插件调用的不是idea默认下载的maven和sbt软件,而是上述自己手动安装的比较新的maven和sbt。
maven的设置,首先看到界面右上角,确认是有一行小字“For default project”,表明是做默认项目配置,如果项目生成后,同样此处的配置界面,将是"For current project",表示只为当前项目做独立设置。然后对界面上maven home目录进行选择,选取上面自己下载的maven目录;设置文件选择maven下的conf/settings.xml,override打勾替换默认的文件;local 仓库位置选择前面设置好的maven本地仓库路径。

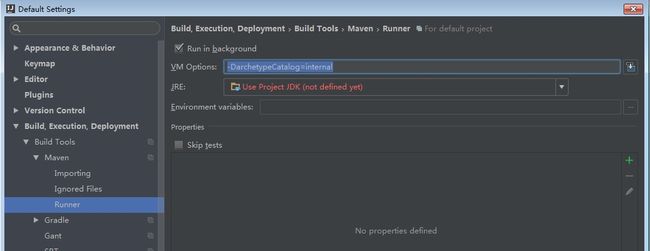
由于maven下载默认仓库依赖时,会下载一个模板文件archetype-catalog.xml,网速慢情况下过于耗时,可能导致下载界面卡住停滞,可以在界面的maven-->runner中设置运行参数,在VM Options写上参数:-DarchetypeCatalog=internal,表示用本地的archetype-catalog.xml,跳过自动网络下载卡住的步骤,然后手动http连接web网页,在maven镜像或中央仓库通过下载路径 org\apache\maven\archetype\archetype-catalog\相应版本号\,下载archetype-catalog.xml,放置在本地maven仓库路径的 org\apache\maven\archetype\archetype-catalog\相应版本号\ 的对应目录位置里面。这样maven插件基本设置完了。
类似的,点击sbt插件,在设置界面将sbt软件由idea打包的bundled选项改为custom,选择上面安装sbt软件的已经修改好的bin/sbt-launch.jar。

接下来还需要在设置界面左侧other settings--->SBT中,去掉Use IDE Settings选项,配置使用自己安装的sbt包和参数,包括下方的SBT laucher JAR file,需要明确地选择自己的sbt软件包,sbt插件才能在idea中按照期望正确地工作。

这个时候回到原来启动界面,选择创建生成新项目,maven或sbt项目,或者直接的java、scala项目,通常已经可以正常工作了,过程不做叙述,网上有很多参考。
6. 通过sbt依赖创建Spark2.0项目
首先在创建的sbt项目中,修改build.sbt,下载spark2.0依赖包,scala编写spark程序,生成jar包放到spark2.0研发的分布式集群运行测试。
(1) 在创建新项目界面中,选择scala--->sbt,在生成的界面中设置项目名称和保存位置,程序根目录。

(2)选择finish,sbt插件将自动调用上述本地安装sbt软件,下载默认依赖包,生成sbt项目结构目录,这里第一次创建需要耐心等待一段时间,等待项目依赖包都下好,sbt代码木结构才能生成。

(3)在生成的sbt项目中,编辑build.sbt,在scalaVersion后面添加spark依赖,注意格式要求,每行之间还要空一行。spark依赖有两种编写方式。
一种是不明确指定spark库的版本,在依赖包的组织部分 "org.apache.spark" 后面加两个%号,让sbt自己去仓库源里面根据scala版本匹配,例如
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.0.0" 。
另一种是明确指明spark库版本,依赖包组织部分 "org.apache.spark" 后面只加一个%号,例如
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.0.0" libraryDependencies += "org.apache.spark" % "spark-mllib_2.11" % "2.0.0" libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.0.0" libraryDependencies += "org.apache.spark" % "spark-sql_2.11" % "2.0.0" libraryDependencies += "org.apache.spark" % "spark-graphx_2.11" % "2.0.0"编写好build.sbt,保存刷新,将下载spark依赖,正常情况下等待下载完,依赖添加成功,可以通过spark API编写程序。
但是有时候由于与源仓库的网速太慢等原因,依赖库的下载未必顺利,导致build.sbt文件总是显示unresolved dependencies,就是指下载库没有下载完整,或配置文件没有记录完整, 比如网络慢导致spark的某些包没下下来,也没什么好办法,只能在idea sbt插件窗口继续刷新下载,如果刷新后sbt下载不正常工作,可以将sbt配置的本地下载库路径cache里相关依赖包目录删除,比如org.apache.spark,然后将本地下载库路径下面与cache目录平行的几个生成配置文件删除(做了测试,有时候spark依赖包已全部下载完成,但不知什么原因,这几个配置文件可能没有相应更新,导致idea中sbt插件仍然显示unresolved dependencies,删除配置文件后再刷新sbt,不再显示错误,添加成功),重新刷新和下载,正常情况下可以完成依赖,build.sbt文件不会报错unresolved dependencies。
如果更换了硬盘或重装了系统,原来Idea仍可使用,如果build.sbt添加库以后依赖解析报错,类似invalid ivy2 cache找不到,可以在Idea的Build下SBT配置 JVM Options,原来的VM Parameters为-XX:MaxPermSize=384M,继续添加-Dsbt.ivy.home=.../ivy-home,-Dsbt.boot.directory=.../sbt-dir/boot,指明cache库所在路径,该路径应与使用的sbt插件中相关路径一致。
(4)接下来可以写个简单的hello spark程序,import spark的一些基础包,试试是否可以正常通过sbt编译和打包,放到集群运行。由于程序很简单,只是打印了sparkcontext的类名,setMaster使用local参数,表示让Spark运行在单机单线程上而不用连接到spark集群,可以直接在idea里面run一下直接查看结果。如果有条件,spark程序开发,建议打包在研发测试集群上运行,分布式程序编写环境和运行环境尽量分开,如果有问题,在运行集群里面去查看日志,对比程序,查找定位问题,不用什么都在IDE里完成,个人认为IDE作用是有利于方便编写代码这个步骤。在研发集群多方面测试通过,再部署到生产环境集群当中。
