强者联盟——Python语言结合Spark框架
引言:Spark由AMPLab实验室开发,其本质是基于内存的快速迭代框架,“迭代”是机器学习最大的特点,因此非常适合做机器学习。得益于在数据科学中强大的表现,Python语言的粉丝遍布天下,如今又遇上强大的分布式内存计算框架Spark,两个领域的强者走到一起,自然能碰出更加强大的火花(Spark可以翻译为火花),因此本文主要讲述了PySpark。
本文选自《全栈数据之门》。
全栈框架
Spark由AMPLab实验室开发,其本质是基于内存的快速迭代框架,“迭代”是机器学习最大的特点,因此非常适合做机器学习。
框架由Scala语言开发,原生提供4种API,Scala、Java、Python以及最近版本开始支持的R。Python不是Spark的“亲儿子”,在支持上要略差一些,但基本上常用的接口都支持。得益于在数据科学中强大的表现,Python语言的粉丝遍布天下,如今又遇上强大的分布式内存计算框架Spark,两个领域的强者走到一起,自然能碰出更加强大的火花(Spark可以翻译为火花),因此PySpark是本节的主角。
在Hadoop发行版中,CDH5和HDP2都已经集成了Spark,只是集成的版本比官方的版本要略低一些。当前最新的HDP2.4已经集成了1.6.1(官方最新为2.0),可以看出,Hortonworks的更新速度非常快,紧跟上游的步伐。
除Hadoop的Map-Reduce计算框架之外,Spark能异军突起,而且慢慢地建立自己的全栈生态,那还真得了解下Spark到底提供了哪些全栈的技术。Spark目前主要提供了以下6大功能。
- Spark Core: RDD及其算子。
- Spark-SQL: DataFrame与SQL。
- Spark ML(MLlib): 机器学习框架。
- Spark Streaming: 实时计算框架。
- Spark GraphX: 图计算框架。
- PySpark(SparkR): Spark之上的Python与R框架。
从RDD的离线计算到Streaming的实时计算;从DataFrame及SQL的支持,到MLlib机器学习框架;从GraphX的图计算到对统计学家最爱的R的支持,可以看出Spark在构建自己的全栈数据生态。从当前学术界与工业界的反馈来看,Spark也已经做到了。
环境搭建
是骡子是马,拉出来遛一遛就知道了。要尝试使用Spark是非常简单的事情,一台机器就可以做测试和开发了。
访问网站http://spark.apache.org/downloads.html,下载预编译好的版本,解压即可以使用。选择最新的稳定版本,注意选择“Pre-built”开头的版本,比如当前最新版本是1.6.1,通常下载spark-1.6.1-bin-hadoop2.6.tgz文件,文件名中带“-bin-”即是预编译好的版本,不需要另外安装Scala环境,也不需要编译,直接解压到某个目录即可。
假设解压到目录/opt/spark,那么在$HOME目录的.bashrc文件中添加一个PATH:
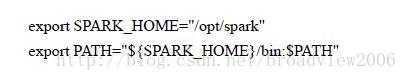
记得source一下.bashrc文件,让环境变量生效: 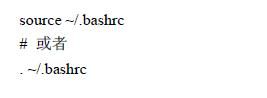
接着执行命令pyspark或者spark-shell,如果看到了Spark那帅帅的文本Logo和相应的命令行提示符>>>,则说明成功进入交互式界面,即配置成功。
pyspark与spark-shell都能支持交互式测试,此时便可以进行测试了。相比于Hadoop来说,基本上是零配置即可以开始测试。
spark-shell测试: 
pyspark测试: 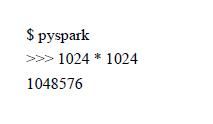
分布式部署
上面的环境测试成功,证明Spark的开发与测试环境已经配置好了。但是说好的分布式呢?我把别人的库都拖下来了,就是想尝试Spark的分布式环境,你就给我看这个啊?
上面说的是单机的环境部署,可用于开发与测试,只是Spark支持的部署方式的其中一种。这种是local方式,好处是用一台笔记本电脑就可以运行程序并在上面进行开发。虽然是单机,但有一个非常有用的特性,那就是可以实现多进程,比如8核的机器,只需要运行代码的时候指定–master local[],就可以用8个进程的方式运行程序。代表使用全部CPU核心,也可以使用如local[4],意为只使用4个核心。
单机的local模式写的代码,只需要做少量的修改即可运行在分布式环境中。Spark的分布式部署支持好几种方式,如下所示。
Standalone:本身自带的集群(方便测试和Spark本身框架的推广)。
Mesos:一个新的资源管理框架。
YARN:Hadoop上新生的资源与计算管理框架,可以理解为Hadoop的操作系统,
可以支持各种不同的计算框架。
EC2:亚马逊的机器环境的部署。
从难易程度上来说,Standalone分布式最简单,直接把解压好的包复制到各台机器上去,配置好master文件和slave文件,指示哪台机器做master,哪些机器做salve。然后在master机器上,通过自带的脚本启动集群即可。
从使用率上来说,应该是YARN被使用得最多,因为通常是直接使用发行版本中的Spark集成套件,CDH和HDP中都已经把Spark和YARN集成了,不用特别关注。
分布式的优势在于多CPU与更大的内存,从CPU的角度再来看Spark的三种方式。
- 本机单CPU:“local”,数据文件在本机。
- 本机多CPU:“local[4]”,数据文件在本机。
- Standalone集群多CPU:“spark://master-ip:7077”,需要每台机器都能访问数据文件。
YARN集群多CPU:使用“yarn-client”提交,需要每台机器都能访问到数据文件。
交互式环境的部署也与上面的部署有关系,直接使用spark-shell或者pyspark是local的方式启动,如果需要启动单机多核或者集群模式,需要指定–master参数,如下所示。

如果使用pyspark,并且习惯了IPython的交互式风格,还可以加上环境变量来启动IPython的交互式,或者使用IPython提供的Notebook:

IPython风格如下所示:

示例分析
环境部署是新手最头痛的问题,前面环境已经部署好了,接下来才是正题。因为Scala较Python复杂得多,因此先学习使用PySpark来写程序。
Spark有两个最基础的概念,sc与RDD。sc是SparkContext的缩写,顾名思义,就是Spark上下文语境,sc连接到集群并做相应的参数配置,后面所有的操作都在这个上下文语境中进行,是一切Spark的基础。在启动交互式界面的时候,注意有一句提示:
SparkContext available as sc, HiveContext available as sqlContext.
意思是,sc这个变量代表了SparkContext上下文,可以直接使用,在启动交互式的时候,已经初始化好了。
如果是非交互式环境,需要在自己的代码中进行初始化:

RDD是Resilient Distributed Datasets(弹性分布式数据集)的缩写,是Spark中最主要的数据处理对象。生成RDD的方式有很多种,其中最主要的一种是通过读取文件来生成:

读取joy.txt文件后,就是一个RDD,此时的RDD的内容就是一个字符串,包含了文件的全部内容。
还记得前面使用Python来编写的WordCount代码吗?通过Hadoop的Streaming接口提到Map-Reduce计算框架上执行,那段代码可不太好理解,现在简单的版本来了。
WordCount例子的代码如下所示: 
在上面的代码中,我个人喜欢用括号的闭合来进行分行,而不是在行尾加上续行符。
PySpark中大量使用了匿名函数lambda,因为通常都是非常简单的处理。核心代码解读如下。
- flatMap:对lines数据中的每行先选择map(映射)操作,即以空格分割成一系列单词形成一个列表。然后执行flat(展开)操作,将多行的列表展开,形成一个大列表。此时的数据结构为:[‘one’,’two’,’three’,…]。
- map:对列表中的每个元素生成一个key-value对,其中value为1。此时的数据结构为:[(‘one’, 1), (‘two’,1), (‘three’,1),…],其中的’one’、’two’、’three’这样的key,可能会出现重复。
- reduceByKey:将上面列表中的元素按key相同的值进行累加,其数据结构为:[(‘one’, 3), (‘two’, 8),
(‘three’, 1), …],其中’one’, ‘two’,’three’这样的key不会出现重复。
最后使用了wc.collect()函数,它告诉Spark需要取出所有wc中的数据,将取出的结果当成一个包含元组的列表来解析。
相比于用Python手动实现的版本,Spark实现的方式不仅简单,而且很优雅。
两类算子
Spark的基础上下文语境为sc,基础的数据集为RDD,剩下的就是对RDD所做的操作了。
对RDD所做的操作有transform与action,也称为RDD的两个基本算子。
transform是转换、变形的意思,即将RDD通过某种形式进行转换,得到另外一个RDD,比如对列表中的数据使用map转换,变成另外一个列表。
当然,Spark能在Hadoop的Map-Reduce模型中脱颖而出的一个重要因素就是其强大的算子。Spark并没有强制将其限定为Map和Reduce模型,而是提供了更加强大的变换能力,使得其代码简洁而优雅。
下面列出了一些常用的transform。
- map(): 映射,类似于Python的map函数。
- filter(): 过滤,类似于Python的filter函数。
- reduceByKey(): 按key进行合并。
- groupByKey(): 按key进行聚合。
RDD一个非常重要的特性是惰性(Lazy)原则。在一个RDD上执行一个transform后,并不立即运行,而是遇到action的时候,才去一层层构建运行的DAG图,DAG图也是Spark之所以快的原因。
- first(): 返回RDD里面的第一个值。
- take(n): 从RDD里面取出前n个值。
- collect(): 返回全部的RDD元素。
- sum(): 求和。
- count(): 求个数。
回到前面的WordCount例子,程序只有在遇到wc.collect()这个需要取全部数据的action时才执行前面RDD的各种transform,通过构建执行依赖的DAG图,也保证了运行效率。
map与reduce
初始的数据为一个列表,列表里面的每一个元素为一个元组,元组包含三个元素,分别代表id、name、age字段。RDD正是对这样的基础且又复杂的数据结构进行处理,因此可以使用pprint来打印结果,方便更好地理解数据结构,其代码如下:

parallelize这个算子将一个Python的数据结构序列化成一个RDD,其接受一个列表参数,还支持在序列化的时候将数据分成几个分区(partition)。分区是Spark运行时的最小粒度结构,多个分区会在集群中进行分布式并行计算。
使用Python的type方法打印数据类型,可知base为一个RDD。在此RDD之上,使用了一个map算子,将age增加3岁,其他值保持不变。map是一个高阶函数,其接受一个函数作为参数,将函数应用于每一个元素之上,返回应用函数用后的新元素。此处使用了匿名函数lambda,其本身接受一个参数v,将age字段v[2]增加3,其他字段原样返回。从结果来看,返回一个PipelineRDD,其继承自RDD,可以简单理解成是一个新的RDD结构。
要打印RDD的结构,必须用一个action算子来触发一个作业,此处使用了collect来获取其全部的数据。
接下来的操作,先使用map取出数据中的age字段v[2],接着使用一个reduce算子来计算所有的年龄之和。reduce的参数依然为一个函数,此函数必须接受两个参数,分别去迭代RDD中的元素,从而聚合出结果。效果与Python中的reduce相同,最后只返回一个元素,此处使用x+y计算其age之和,因此返回为一个数值,执行结果如下图所示。 
AMPLab的野心
AMPLab除了最著名的Spark外,他们还希望基于内存构建一套完整的数据分析生态系统,可以参考https://amplab.cs.berkeley.edu/software/上的介绍。
他们的目的就是BDAS(Berkeley Data Analytics Stack),基于内存的全栈大数据分析。前面介绍过的Mesos是集群资源管理器。还有Tachyon,是基于内存的分布式文件系统,类似于Hadoop的HDFS文件系统,而Spark Streaming则类似于Storm实时计算。
强大的全栈式Spark,撑起了大数据的半壁江山。
本文选自《全栈数据之门》,点此链接可在博文视点官网查看此书。
