语音识别系统结构——鸟瞰
语音识别概述
语音识别是指将语音信号转换为文字的过程。现在通行的语音识别系统框架如图: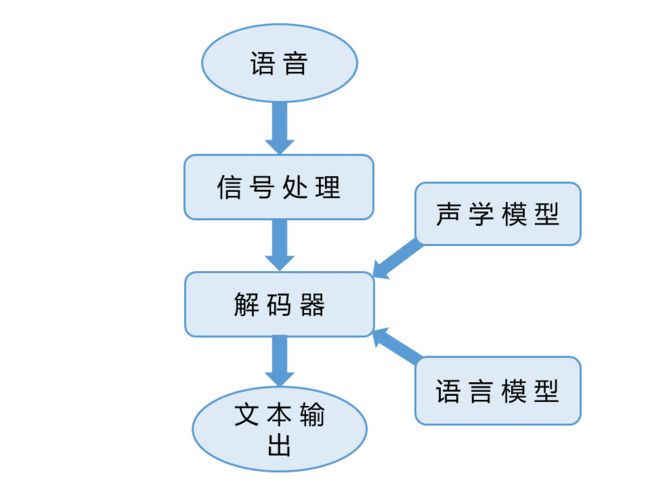
信号处理模块将根据人耳的听觉感知特点,抽取语音中最重要的特征,将语音信号转换为特征矢量序列。现行语音识别系统中常用的声学特征有线性预测编码(Linear Predictive Coding,LPC),梅尔频率倒谱系数(Mel-frequency Cepstrum Coefficients,MFCC),梅尔标度滤波器组(Mel-scale Filter Bank,FBank)等。
解码器(Decoder)根据声学模型和语言模型,将输入的语音特征矢量序列转化为字符序列。
声学模型是对声学、语音学、环境的变量,以及说话人性别、口音的差异等的知识表示。语言模型则是对一组字序列构成的知识表示。
模型的训练
现代的语音识别系统中声学模型和语言模型主要利用大量语料进行统计分析,进而建模得到。
声学模型
语音识别中的声学模型充分利用了声学、语音学、环境特性以及说话人性别口音等信息,对语音进行建模。目前的语音识别系统往往采用隐含马尔科夫模型(Hidden Markov Model,HMM)建模,表示某一语音特征矢量序列对某一状态序列的后验概率。隐含马尔科夫模型是一种概率图模型,可以用来表示序列之间的相关关系,常常被用来对时序数据建模。
隐含马尔科夫模型是一种带权有向图,图上每一个节点称为状态。每一时刻,隐含马尔科夫模型都有一定概率从一个状态跳转到另一个状态,并有一定概率发射一个观测符号,跳转的概率用边上的权重表示,如图所示, S0 和 S1 表示状态, a 和 b 是可能发射的观测符号。
隐含马尔科夫模型假定,每一次状态的转移,只和前一个状态有关,而与之前之后的其它状态无关,即马尔科夫假设;在每一个状态下发射的符号,只与当前状态有关,与其它状态和其它符号没有关系,即独立输出假设。
隐含马尔科夫模型一般用三元组 λ=(A,B,π) 表示,其中 A 为状态转移概率矩阵,表示在某一状态下转移到另一状态的概率;B 为符号概率矩阵,表示在某一状态下发射某一符号的概率;π 为初始状态概率矢量,表示初始时处在某一状态的概率。

隐含马尔科夫模型可以产生两个随机的序列,一个是状态序列,一个是观测符号序列,所以是一个双重随机过程,但外界只能观测到观测符号序列,不能观测到状态序列。可以利用维特比算法(Viterbi Algorithm)找出在给定观测符号序列的条件下,发生概率最大的状态序列。对于某一观测符号序列的概率,可以通过前向后向算法(Forward-Backward Algorithm)高效地求得。每一个状态的转移概率和观测符号发射概率可以通过鲍姆—韦尔奇算法(Baum-Welch Algorithm)计算得到。
语音识别中一般使用隐含马尔科夫模型对声学单元和语音特征序列之间的关系建模。一般来说,声学单元级别较小,其数量就少,但对上下文的敏感性则会大。大词汇量连续语音识别系统中一般采用子词(Sub-word)作为声学单元,如在英语中采用音素,汉语中采用声韵母等。
声学模型中隐含马尔科夫模型的拓扑结构一般采用从左向右的三状态结构,每一个状态上都有一个指向自身的弧,如图所示,表示利用三状态模型对音素 / t / 的建模 。

由于连续语音中具有协同发音的现象,故需要对前后三个音素共同考虑,称为三音子(Triphone)模型。引入三音子后,将引起隐含马尔科夫模型数量的急剧增加,所以一般会对状态进行聚类,聚类后的状态称为 Senone。
语音识别任务中的声学特征矢量取值是连续的,为了消除量化过程造成的误差,所以考虑使用连续概率密度函数来对特征矢量对状态的概率进行建模。混合高斯模型(Gaussian Mixture Models,GMM)可以对任意的概率密度函数进行逼近,所以成为了建模的首选。
邓力等将深度学习引入语音识别的声学建模中,用深度神经网络对声学特征矢量和状态的关系进行建模 ,极大地提升了语音识别的准确率,此后深度学习在语音识别声学建模上的应用开始蓬勃发展,如利用声学特征矢量上下文关系的循环神经网络(Recurrent Neural Networks,RNN)及其特殊情况长短时记忆网络(Long Short-term Memory,LSTM)等。
语言模型
语言模型可以表示某一字序列发生的概率。语音识别中常用的语言模型是 N 元文法(N-Gram),即统计前后 N 个字出现的概率。N 元文法假定某一个字出现的概率仅与前面 N-1 个字出现的概率有关系。
设现在有一字序列 W=(w1,w2,w3,⋯,wU) ,则其发生概率可以被分解为如下形式:
但是,这样的概率无法统计。根据马尔科夫假设,则只需考虑前 N 个字符发生条件下的概率即可。假设 N=2 则有
再根据贝叶斯公式,可以得出某一个字在另一个字的条件下发生的概率
由此,在大量的语料中统计出相邻的字发生的概率,再统计出单个字出现的概率,即可。
由于必然会有一些生僻词组在语料中未曾出现,但其也存在着发生的概率,所以需要算法生成这些生僻词组的概率,即平滑。常用的平滑方式有古德-图灵平滑(Good-Turing Soothing)和卡茨平滑(Katz Smoothing)等。
基于加权有限状态转换器的解码
语音识别中的“解码”问题可以表示为如下过程:对于一个长度为T的给定的声学观测
(acoustic observation)序列 X=(x1,x2,x3,⋯,xT) ,求出一个长度为U的对应的字( word )序列 W=(w1,w2,w3,⋯,wU) ,使得后验概率 P(W|X) 最大化,即求得字序列 W ,有
后验概率 P(W│X) 不易直接求得。根据贝叶斯公式可得:
由于声学观测序列已经给定,所以声学观测的概率是常数,故可以归约为如下形式:
目前一般采用的大词汇量语音识别技术,会将声学、语音学以及语言学的知识引入进系统中去。用 H 表示隐含马尔科夫模型的状态序列,C 表示上下文相关的音素序列,L 表示音素序列,并假设声学特征序列、隐含马尔科夫模型的状态序列、音素序列、字序列之间是独立的,可以将式子展开,得:
式 子中, P(X|H) 称为声学模型,表示声学特征序列对隐马尔科夫状态序列的后验概率; P(H│C) 、 P(C│L) 和 P(L│W) 分别表示状态序列对上下文相关的音素序列、上下文相关的音素序列对音素序列,以及音素序列对字序列的后验概率; P(W) 表示句子发生的概率,称为语言模型。这些概率都是由前面的“训练”过程得到的。
目前,语音识别的解码一般基于加权有限状态转换器(Weighted Finite State Transducer)进行。
加权有限状态转换器是一种赋权有向图,其每一个节点表示一个“状态”,当接受到一个输入符号以后,就会由对应的弧跳转到另一个“状态”,并“发射”一个输出符号,弧上还可以赋予权值。其形式化描述如下:
半环K上的加权有限状态转换器T是一个八元组 T=(Σ,Δ,Q,I,F,E,λ,ρ) ,其中 Σ 为输入符号集合, Δ 为输出符号集合, Q 为状态集合, I , Q 为初始状态集合, F , Q 为终止状态集合,五元关系 E⊆Q×(Σ∪ϵ)×(Δ∪ϵ)×K×Q 表示转移函数,映射 λ:I→K 表示初始状态的权值,映射 ρ:F→K 表示终止状态的权值 。
为了扩大加权有限转换器的适用范围,将“权重”的含义推广到更一般的代数结构——半环上去。给定集合K及其上的两种运算 ⊕ 和 ⊗ ,如果 (K,⊕,0¯) 为带有单位元 0¯ 的交换幺半群, (K,⊗,1¯) 为带有单位元 1¯ 的幺半群,且 ⊕ 运算对于 ⊗ 运算具有分配性, 0¯ 对于 ⊗ 运算为零化子,即对于任意的 a⊆K 有 a⊗0¯=0¯⊗a=0¯ 。于是,由首状态到末状态“路径”上各个弧的总权重,可以由 ⊗ 运算求“积”得到,而多条路径的总权重,则可以由 ⊕ 求和得到。下图表示了一个简单的加权有限状态转换器。其输入符号集为 {a,b,c} ,在图中表示为弧上冒号前的符号,输出符号集为 {x,y,z} ,在图中表示为弧上冒号后的符号,半环为实数域,在图中表示为斜线后的数,双圆圈表示终止状态。

在语音识别中,路径的总权重可以看作在输入序列的条件下,输出序列的联合概率,又因为马尔科夫链的无后效性假设,所以总权重可以看作路径上权重的乘积。由于计算机运算,需要防止浮点数的下溢,这些概率常常取对数,即表 中对数半环,其中 ⊕log 运算的定义为 x⊕logy=−log(e−x+e−y) ;又由于语音识别中常需要在加权有限状态转换器上寻找权值最优的路径,故定义了热带半环。
| 半环 | 集合 | ⊕ | ⊗ | 0¯ | 1¯ |
|---|---|---|---|---|---|
| 对数半环(Log) | R∪{−∞,+∞} | ⊕log | + | +∞ | 0 |
| 热带半环(Tropical) | R∪{−∞,+∞} | Min | + | +∞ | 0 |
可以利用加权有限状态转换器的组合(composition)操作,将不同层次的加权有限状态转换器合并起来。比如,在实际的语音识别系统中,一般会构建四个加权有限状态转换器:表示隐含马尔科夫模型状态序列到上下文相关音素序列映射的H,表示上下文相关音素序列到音素序列映射的C,表示音素序列到字序列的L,以及语言模型G,将此四个加权有限状态转换器组合,形成HCLG,其对应着语音学和语言学的知识,其上弧的权重,可以看作输入隐含马尔科夫模型状态,输出对应的字发生的概率。
声学模型P(X|H) 根据训练得出。将一句语音输入训练好的网络前馈以后,得到一个矩阵,其列表示帧数,行表示此帧对隐含马尔科夫模型状态的概率分布,即一个某帧对某隐含马尔科夫状态的概率查询表。
于是,语音识别的解码问题可以归结为在加权有限状态转换器 HCLG 的最优路径搜索问题,只是路径的总权值除了要考虑 HCLG 弧上的权值以外,还要考虑声学模型的权值,令总权值最大化。
根据带权有向无环图单源最短路径算法 ,考虑到事实“对于图的最短路径上的某一节点u,若其在此路径上的前驱为σ,则σ必然在源点到u的最短路径(之一)上”,可以使用由源点开始,逐层构建最短路径树的方法进行。实际系统中,由于搜索图的庞大,为了减少对计算机内存的消耗,常使用启发式的波束搜索(Beam Search)技术,即设定一个阈值,在搜索树中保留阈值范围内的路径,裁剪掉阈值范围以外的路径。加权有限状态转换器上的解码过程可以用伪代码简略地描述为
foreach frame:
foreach token:
if token->cost > cut_off:
foreach arc:
if arc.weight > cut_off:
add arc to token
else:
delete token其中,token表示保存路径的数据结构,其每一个节点可以保存弧,以及当前这条路径的总代价。
在实际的语音识别系统中,最优路径不一定与实际字序列匹配,我们一般希望能够得到得分最靠前的多条候选路径,即N-best。为了紧凑地保存候选路径,防止占用过多内存空间,我们一般采用词格(Lattice)来保存识别的候选序列。词格没有一般的定义,常用的方法是利用有限状态自动机的数据结构来构建词格。
后记:这是我学习语音识别的一个小结,也是我毕设的一个章节。拿出来给大家看看,有错误的地方希望大家不吝赐教。
参考文献
- Huang X, Acero A, Hon H, et al. Spoken Language Processing[J]., 2000.
- Rabiner L R. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Proceedings of the IEEE, 1989, 77(2): 257-286.
- Mohri M, Pereira F C, Riley M, et al. Weighted Finite-state Transducers in Speech Recognition[J]. Computer Speech & Language, 2002, 16(1): 69-88.