时间序列模型之相空间重构
一般的时间序列主要是在时间域中进行模型的研究,而对于混沌时间序列,无论是混沌不变量的计算,混沌模型的建立和预测都是在所谓的相空间中进行,因此相空间重构就是混沌时间序列处理中非常重要的一个步骤。所谓混沌序列,可以看作是考察混沌系统所得到的一组随着时间而变化的观察值。假设时间序列是 {x(i):i=1,⋅⋅⋅,n}, 那么吸引子的结构特性就包含在这个时间序列之中。为了从时间序列中提取出更多有用的信息,1980年Packard等人提出了时间序列重构相空间的两种方法:导数重构法和坐标延迟重构法。而后者的本质则是通过一维的时间序列 {x(i)} 的不同延迟时间 τ 来构建 d 维的相空间矢量
y(i)=(x(i),...,x(i+(d−1)τ)),1≤i≤n−(d−1)τ.
1981年Takens提出嵌入定理:对于无限长,无噪声的 d′ 维混沌吸引子的一维标量时间序列 {x(i):1≤i≤n} 都可以在拓扑不变的意义下找到一个 d 维的嵌入相空间,只要维数 d≥2d′+1. 根据Takens嵌入定理,我们可以从一维混沌时间序列中重构一个与原动力系统在拓扑意义下一样的相空间,混沌时间序列的判定,分析和预测都是在这个重构的相空间中进行的,因此相空间的重构就是混沌时间序列研究的关键。
1. 相空间重构
相空间重构技术有两个关键的参数:嵌入的维数 d 和延迟时间 τ. 在Takens嵌入定理中,嵌入维数和延迟时间都只是理论上证明了其存在性,并没有给出具体的表达式,而且实际应用中时间序列都是有噪声的有限序列,嵌入维数和时间延迟必须要根据实际的情况来选取合适的值。
关于嵌入维数 d 和延迟时间 τ 的取值,通常有两种观点:第一种观点认为 d 和 τ 是互不相关的,先求出延迟时间之后再根据它求出合适的嵌入维数。求出延迟时间 τ 比较常用的方法主要有自相关法,平均位移法,复自相关法和互信息法等,关键的地方就是使得原时间序列经过时间延迟之后可以作为独立的坐标来使用。同时寻找嵌入维数的方法主要是几何不变量方法,虚假最临近法(False Nearest Neighbors)和它改进之后的Cao方法等。第二种观点则是认为延迟时间和嵌入维数是相关的。1996年Kugiumtzis提出的时间窗长度则是综合考虑两者的重要参数。1999年,Kim等人提出了C-C方法,该方法使用关联积分同时估计出延迟时间和时间窗。
(1) 延迟时间 τ 的确定:
如果延迟时间 τ 太小,则相空间向量
y(i)=(x(i),⋅⋅⋅,x(i+(d−1)τ),1≤i≤n−(d−1)τ
中的两个坐标分量 x(i+jτ) 与 x(i+(j+1)τ) 在数值上非常接近,以至于无法相互区分,从而无法提供两个独立的坐标分量;但是如果延迟时间 τ 太大的话,则两个坐标分量又会出现一种完全独立的情况,混沌吸引子的轨迹在两个方向上的投影就毫无相关性可言。因此需要合适的方法来确定一个合适的延迟时间 τ, 从而在独立和相关两者之间达到一种平衡。
(1.1) 自相关系数法:
自相关函数是求延迟时间 τ 比较简单的一种方法,它的主要理念就是提取序列之间的线性相关性。对于混沌序列 x(1),x(2),⋅⋅⋅,x(n), 可以写出其自相关函数如下:
R(τ)=1n∑n−τi=1x(i)x(i+τ).
此时就可以使用已知的数据 x(1),⋅⋅⋅x(n) 来做出自相关函数 R(τ) 随着延迟时间 τ 变化的图像,当自相关函数下降到初始值 R(0) 的 1−e−1 时,i.e. R(τ)=(1−e−1)R(0), 所得到的时间 τ 也就是重构相空间的延迟时间。虽然自相关函数法是一种简便有效的计算延迟时间的方法,但是它仅仅能够提取时间序列的线性相关性。根据自相关函数法可以让 x(i),x(i+τ) 以及 x(i+τ),x(i+2τ) 之间不相关,但是 x(i),x(i+2τ) 之间的相关性可能会很强。这一点意味着这种方法并不能够有效的推广到高维的研究。而且选择下降系数 1−e−1 时,这一点可能有点主观性,需要根据具体的情况做适当的调整。因此再总结了自相关法的不足之后,下面介绍一种判断系统非线性关系性的一种方法:交互信息法。
(1.2) 交互信息法:
在考虑了以上方法的局限性之后,Fraser和Swinney提出了交互信息法(Mutual Information Method)。假设两个离散信息系统 {s1,⋅⋅⋅,sm},{q1,⋅⋅⋅,qn} 所构成的系统 S 和 Q 。通过信息论和遍历论的知识,从两个系统中获得的信息熵分别是:
H(S)=−∑mi=1PS(si)log2PS(si),
H(Q)=−∑nj=1PQ(qj)log2PQ(qj).
其中 PS(si),PQ(qi) 分别是 S 和 Q 中事件 si 和 qi 的概率。交互信息的计算公式是:
I(S,Q)=H(S)+H(Q)−H(S,Q),
其中 H(S,Q)=−∑mi=1∑nj=1PS,Q(si,qj)log2PS,Q(si,qj).
这里的 PS,Q(si,qj) 称为事件 si 和事件 qj 的联合分布概率。交互信息标准化就是
I(S,Q)=I(S,Q)/H(S)×H(Q)−−−−−−−−−−−√.
现在,我们通过信息论的方法来计算延迟时间 τ. 定义 (S,Q)=(x(i),x(i+τ)),1≤i≤n−τ, 也就是 S 代表时间 x(i), Q 代表时间 x(i+τ). 那么 I(S,Q) 则是关于延迟时间 τ 的函数,可以写成 I(τ). I(τ) 的大小表示在已知系统 S ,也就是 x(i) 的情况下,系统 Q 也就是 x(i+τ) 的确定性的大小。 I(τ)=0 表示 x(i) 和 x(i+τ) 是完全不可预测的,也就是说两者完全不相关。而 I(τ) 的第一个极小值,则表示了 x(i) 和 x(i+τ) 是最大可能的不相关,重构时使用 I(τ) 的第一个极小值最为最优的延迟时间 τ.
交互信息法的关键在于怎么计算联合概率分布 PS,Q(si,qj) 以及 S 和 Q 系统的概率分布 PS(si) 和 PQ(qj). 这里采取的方法是等间距格子法,其方法简要概述如下。
令 (S,Q)=(x(i),x(i+τ)),1≤i≤n−τ, 在 (S,Q) 平面用一个矩形包含上面所有的点。将矩形 S 方向上等分成 M1 份, Q 方向等分成 M2 份(注: M1,M2 取值100~200之间即可)。那么在 S 方向上格子的长度就是 ϵ1, Q 方向上格子的长度就是 ϵ2. 假设 (a,b) 是 (S,Q) 平面矩形左下角的顶点坐标。
如果 (i−1)ϵ1≤s−a<iϵ1, 那么 s 在第 i 个格子中,对 Row[i] 做一次记录;
如果 (j−1)ϵ2≤s−b<jϵ2, 那么 q 在第 j 个格子中,对 Col[j] 做一次记录。 x(i) 和 x(i+τ) 序列的总数都是 n−τ, 那么
PS(i)=Row[i]/(n−τ),1≤i≤M1,
PQ(j)=Col[j]/(n−τ),1≤j≤M2.
如果 (i−1)ϵ1≤s−a<iϵ1 且 (j−1)ϵ2≤q−b<jϵ2, 则 (s,q) 在标号为 (i,j) 的格子中,对 Together[i][j] 做一次记录。那么
PS,Q(i,j)=Together[i][j]/(n−τ)2,1≤i≤M1,1≤j≤M2.
根据以上信息论的公式,可以得到:
H(S)=−∑M1i=1PS(i)log2PS(i),
H(Q)=−∑M2j=1PQ(j)log2PQ(j),
H(S,Q)=−∑M1i=1∑M2j=1PS,Q(i,j)log2PS,Q(i,j).
I(S,Q)=H(S)+H(Q)−H(S,Q),
I(S,Q)=I(S,Q)/H(S)×H(Q)−−−−−−−−−−−√.
交互信息曲线 I(τ)=I(S,Q) 第一次下降到极小值所对应的延迟时间 τ 则是最佳延时时间。
(2) 嵌入维数 d 的确定:
(2.1) 几何不变量法:
为了确定嵌入维数 d, 实际应用中通常的方法是计算吸引子的某些几何不变量(如关联维数,Lyapunov指数等)。选择好延迟时间 τ 之后逐渐增加维数 d, 直到他们停止变化为止。从Takens嵌入定理分析可知,这些几何不变量具有吸引子的几何性质,当维数 d 大于最小嵌入维数的时候,几何结构已经被完全打开,此时这些几何不变量与嵌入的维数无关。基于此理论,可以选择吸引子的几何不变量停止变化时的嵌入维数 d 作为重构的相空间维数。
(2.2) 虚假最临近点法:
从几何的观点来看,混沌时间序列是高维相空间混沌运动的轨迹在一维空间的投影,在这个投影的过程中,混沌运动的轨迹就会被扭曲。高维相空间并不相邻的两个点投影到一维空间上有的时候就会成为相邻的两点,也就是虚假邻点。重构相空间,实际上就是从混沌时间序列中恢复混沌运动的轨迹,随着嵌入维数的增大,混沌运动的轨道就会被打开,虚假邻点就会被逐渐剔除,从而整个混沌运动的轨迹得到恢复,这个思想就是虚假最临近点法的关键。
在 d 维相空间中,每一个矢量
yi(d)=(x(i),⋅⋅⋅,x(i+(d−1)τ),1≤i≤n−(d−1)τ
都有一个欧几里德距离的最邻近点 yn(i,d)(d),(n(i,d)≠i,1≤n(i,d)≤n−(d−1)τ) 其距离是
Ri(d)=||yi(d)−yn(i,d)(d)||2.
当相空间的维数从 d 变成 d+1 时,这两个点的距离就会发生变化,新的距离是 Ri(d+1), 并且
(Ri(d+1))2=(Ri(d))2+||x(i+dτ)−x(n(i,d)+dτ)||22.
如果 Ri(d+1) 比 Ri(d) 大很多,那么就可以认为这是由于高维混沌吸引子中两个不相邻得点投影到低维坐标上变成相邻的两点造成的,这样的临近点是虚假的,令
a1(i,d)=||x(i+dτ)−x(n(i,d)+dτ)||2/Rd(i).
如果 a1(i,d)>Rτ∈[10,50], 那么 yn(i,d)(d) 就是 yi(d) 的虚假最临近点。这里的 Rτ 是阀值。
对于实际的混沌时间序列,从嵌入维数的最小值2开始,计算虚假最临近点的比例,然后逐渐增加维数 d, 直到虚假最临近点的比例小于5%或者虚假最临近点的不再随着 d 的增加而减少时,可以认为混沌吸引子已经完全打开,此时的 d 就是嵌入维数。在相空间重构方面,虚假最临近点法(FNN)被认为是计算嵌入维数很有效的方法之一。
(2.3) 虚假最临近点法的改进-Cao方法:
虚假最临近点法对数据的噪声比较敏感,而且实际操作中需要选择阀值 Rτ, 具有很强的主观性。此时Cao Liangyue教授提出了改进的FNN方法,此方法计算时只需要延迟时间 τ 一个参数,用较小的数据量就可以求的嵌入维数 d.
假设我们有时间序列 x(1),⋅⋅⋅,x(n). 那么基于延迟时间 τ 所构造的向量空间就是: yi(d)=(x(i),⋅⋅⋅x(i+(d−1)τ)),i=1,2,⋅⋅⋅,n−(d−1)τ, 这里的 d 是作为嵌入维数, τ 是作为嵌入时间。 yi(d) 则表示第 i 个 d 维重构向量。与虚假最临近点法类似,定义变量
a(i,d)=||yi(d+1)−yn(i,d)(d+1)||∞/||yi(d)−yn(i,d)(d)||∞,i=1,2,⋅⋅⋅n−dτ,
这里的 ||⋅||∞ 是最大模范数。其中 yi(d+1) 是第 i 个 d+1 维的重构向量,i.e. yi(d+1)=(x(i),⋅⋅⋅,x(i+dτ)). n(i,d)∈{1,⋅⋅⋅,n−dτ} 是使得 yn(i,d)(d) 在 d 维相空间里面,在最大模范数下与 yi(d) 最近的向量,并且 n(i,d)≠i ,显然 n(i,d) 由 i 和 d 所决定。
定义
E(d)=(n−dτ)−1⋅∑n−dτi=1a(i,d).
E(d) 与延迟时间 τ 和嵌入维数 d 有关。为了发现从 d 到 d+1 ,该函数变化了多少,可以考虑 E1(d)=E(d+1)/E(d). 当 d 大于某个值 d0 时, E1(d) 不再变化,那么 d0+1 则是我们所寻找的最小嵌入维数。除了 E1(d), 还可以定义一个变量 E2(d) 如下。令
E∗(d)=(n−dτ)−1⋅∑n−dτi=1|x(i+dτ)−x(n(i,d)+dτ)|,
这里的 n(i,d) 和上面的定义一样,也就是使得 yn(i,d)(d) 与 yi(d) 最近的整数,并且 n(i,d)≠i. 定义 E2(d)=E∗(d+1)/E∗(d). 对于随机序列,数据之间没有相关性, E2(d)≡1. 对于确定性的序列,数据点之间的关系依赖于嵌入维数 d 的变化,总存在一些值使得 E2(d)≠1.
2. 相空间的预测
通过前面的相空间重构过程,一个混沌时间序列 x(1),⋅⋅⋅,x(n) 可以确定其延迟时间 τ 和嵌入维数 d, 形成 n−(d−1)τ 个 d 维向量:
y⃗ 1=y1(d)=(x(1),⋅⋅⋅,x(1+(d−1)τ)),
y⃗ 2=y2(d)=(x(2),⋅⋅⋅,x(2+(d−1)τ)),
⋅⋅⋅
y⃗ i=yi(d)=(x(i),⋅⋅⋅,x(i+(d−1)τ)),
⋅⋅⋅
y⃗ n−(d−1)τ=yn−(d−1)τ(d)=(x(n−(d−1)τ),⋅⋅⋅,x(n)).
这样我们就可以在 d 维欧式空间 Rd 建立一个动力系统的模型如下:
y⃗ i+1=F(y⃗ i), 其中 F 是一个连续函数。
(1) 局部预测法:
假设 N=n−(d−1)τ, 根据连续函数的性质可以知道:如果 y⃗ N 与 y⃗ j 非常接近,那么 y⃗ N+1 与 y⃗ j+1 也是非常接近的,可以用 x(j+1+(d−1)τ) 作为 x(N+1+(d−1)τ)=x(n+1) 的近似值。
(1.1) 局部平均预测法:
考虑向量 y⃗ N 的 k 个最临近向量 y⃗ t1,⋅⋅⋅,y⃗ tk. i.e. 也就是从其他的 N−1 个向量中选取前 k 个与 y⃗ N 最临近的向量,此处用欧几里德范数 ||⋅||2 或者最大模范数 ||⋅||∞. 根据局部预测法的观点,可以得到 x(n+1) 的近似值:
x(n+1)≈k−1⋅∑kj=1x(tj+1+(d−1)τ).
也可以引入权重的概念来计算近似值:
x(n+1)≈∑kj=1x(tj+1+(d−1)τ)⋅ω(y⃗ tj,y⃗ N).
其中 ω(y⃗ tj,y⃗ N)=Kh(||y⃗ tj−y⃗ N||)/∑kj=1Kh(||y⃗ tj−y⃗ N||),1≤j≤k,
K(x)=exp(−x2/2),
Kh(x)=h−1K(h−1x)=h−1exp(−x2/(2∗h2)).
(1.2) 局部线性预测法:
假设 N=n−(d−1)τ, 则有 yN(d)=(x(N),⋅⋅⋅,x(n)).
局部线性预测模型为
x^(n+1)=c0x(N)+c1x(N+τ)+⋅⋅⋅+cd−1x(N+(d−1)τ)+cd,
其中 ci,0≤i≤d 是待定系数。假设向量 y⃗ N 的 k 个最临近向量是 y⃗ t1,⋅⋅⋅,y⃗ tk. 此处可以用欧几里德范数 ||⋅||2 或者最大模范数 ||⋅||∞. 这里使用最小二乘法来求出 ci,0≤i≤d 的值。也就是求 ci 使得
||Ab−Y||22=∑kj=1(x^(tj+1+(d−1)τ)−x(tj+1+(d−1)τ))2
=∑kj=1(c0x(tj)+c1x(tj+τ)+⋅⋅⋅+cd−1x(tj+(d−1)τ)+cd−x(tj+1+(d−1)τ))2
取得最小值,其中 Y=(x(t1+1+(d−1)τ),x(t2+1+(d−1)τ),⋅⋅⋅x(tk+1+(d−1)τ))T, b=(c0,c1,⋅⋅⋅,cd)T, 矩阵 A 的第 j 行是 d+1 维向量 (x(tj),⋅⋅⋅,x(tj+(d−1)τ),1),1≤j≤k. 根据最小二乘法可以得到待定系数向量 b=(ATA)−1ATY 是最小二乘解。
(1.3) 局部多项式预测法:
(2) 全局预测法:
(2.1) 神经网络
(2.2) 小波网络
(2.3) 遗传算法
3. 实验数据
这里使用Lorenz模型来作为测试数据,
dx/dt=σ(y−x),
dy/dt=x(ρ−z)−y,
dz/dt=xy−βz,
其中 x,y,z 是系统的三个坐标, σ,ρ,β 是三个系数。在这里,我们取 ρ=28,σ=10,β=8/3. 在解这个常微分方程的时候,使用了经典的Runge-Kutta数值方法。
测试数据1:
使用1300个点,预测未来100个点,绿色曲线表示Lorenz模型在z坐标上的实际数据,红线右侧表示开始预测,蓝色曲线表示使用相空间重构模型所预测的数据。根据统计学分析可以得到:在红色线条的右侧,蓝色曲线的点和绿色曲线的点的Normalized Root Mean Square Error<8%, Mean Absolute Percentage Error<5.3%, 相关系数>97%.

把红线附近的图像放大可以看的更加清楚:
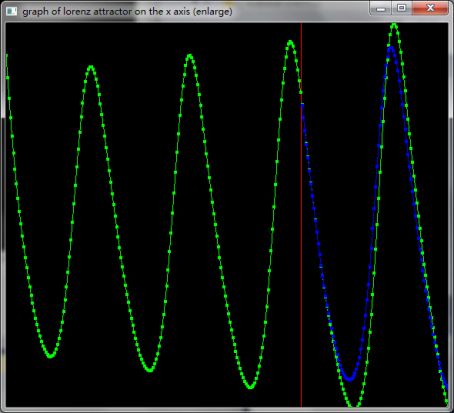
测试数据2:
使用1800个点,预测未来100个点,绿色曲线表示Lorenz模型在x坐标上的实际数据,红线右侧表示开始预测,蓝色曲线表示使用相空间重构模型所预测的数据。根据统计学分析可以得到:在红色线条的右侧,蓝色曲线的点和绿色曲线的点的Normalized Root Mean Square Error<1%, Mean Absolute Percentage Error<2%, 相关系数>99%.
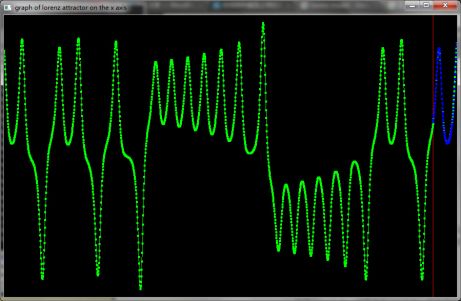
把红线附近的图像放大:

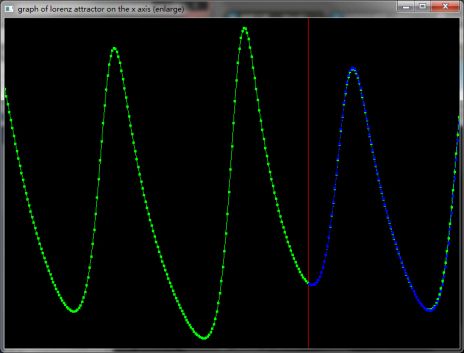
使用同样的数据量,也就是n=1800,预测未来100个点,绿色曲线表示Lorenz模型在z坐标上的实际数据,红线右侧表示开始预测,蓝色曲线表示使用相空间重构模型所预测的数据。根据统计学分析可以得到:在红色线条的右侧,蓝色曲线的点和绿色曲线的点的Normalized Root Mean Square Error<1%, Mean Absolute Percentage Error<1%, 相关系数>99%.

把红线附近的图像放大:
参考文献:
- https://en.wikipedia.org/wiki/Lorenz_system
- https://en.wikipedia.org/wiki/Root-mean-square_deviation
- https://en.wikipedia.org/wiki/Mean_absolute_percentage_error
- Practical method for determining the minimum embedding dimension of a scalar time series
- 基于混沌理论的往复式压缩机故障诊断
- determining embedding dimension for phase-space reconstruction using a geometric construction
- Time Series Prediction by Chaotic Modeling of Nonlinear Dynamical Systems
- nonlinear dynamics delay times and embedding windows