密度聚类
引言
其实对于所有的聚类问题,都有一个核心点,那就是以什么样的规则来划分两个点是不是同一类。密度聚类,本质上就是基于一种密度的概念来进行聚类。而密度的定义本质上也是来自于两点的距离,所以其实对于聚类的算法来看,大家本质上都差不多,谁也别笑话谁。下面我们来总结介绍一种叫做DBSCAN的密度算法。
DBSCAN
DBSCAN 的全称是 Density-Based Spatial Clustering of Applications with Noise
单词里面有个noise,这就说明我们的算法是能抗噪声的,并且我们的算法是可以在空间中聚类为任意形状的聚类的,这点是一些其他的聚类算法不具备的性质,如下所示:
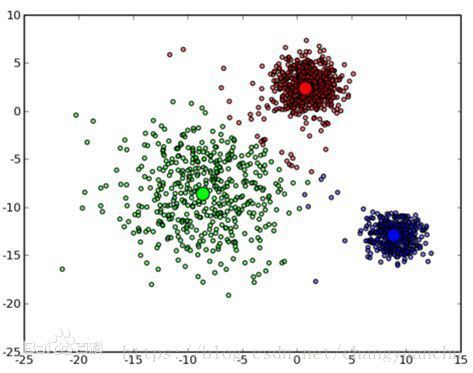
具有这样的性能,就是因为我们的算法引入了“邻域”(其参数为 (ε,MinPts) ( ε , M i n P t s ) )的概念来刻画样本的紧密程度的算法。
下面我们来介绍一下这个算法,在具体算法之前,我们先看几个定义,非常简单,但是可能比较绕,懂了这几个定义,下面的算法就是小菜一碟了。
基于密度的几个概念
ε− ε − 邻域:
对 xj∈D x j ∈ D ,其 ε− ε − 邻域是指样本集 D D 中与 xj x j 距离不大于 ε ε 的样本,即 Nε(xj)={xj∈D|dist(xi,xj)≤ε} N ε ( x j ) = { x j ∈ D | d i s t ( x i , x j ) ≤ ε }
核心对象:
对象 xj x j 的 ε− ε − 邻域中至少包含 MinPts M i n P t s 个样本,即 Nε(xj)≥MinPts N ε ( x j ) ≥ M i n P t s ,则称 xj x j 为核心对象。
密度直达:
若 xj x j 位于 xi x i 的 ε− ε − 邻域中,且 xi x i 是核心对象,则称 xj x j 由 xi x i 密度直达。
密度可达:
对 xj x j 与 xi x i ,存在样本序列 p1,p2,...,pn p 1 , p 2 , . . . , p n 且 p1=xj,pn=xi p 1 = x j , p n = x i 且 pi+1 p i + 1 由 pi p i 密度直达,则称 xj x j 由 xi x i 密度可达。
其实这个概念本质上要求 p2,...,pn p 2 , . . . , p n 都是核心对象
密度相连:
对 xj x j 与 xi x i ,若存在 xk x k 使得 xj x j 与 xi x i 均由 xk x k 密度可达,则称 xj x j 由 xi x i 密度相连。
下图直观的表示了这几个概念

基于上面的概念,可以定义DBSCAN算法里面的簇的定义
簇: 由密度可达关系导出的最大的密度相连的样本集合。
因此实际上簇 C⊆D C ⊆ D 满足下面的两个条件:
连接性: xi∈C,xj∈C⇒ x i ∈ C , x j ∈ C ⇒ xi x i 与 xj x j 密度相连
最大性: xi∈C x i ∈ C 且 xj x j 由 xi x i 密度可达 ⇒xj∈C ⇒ x j ∈ C
实际上就是核心对象以及与其密度可达的所有的点的集合
本质上相当于一些核心对象以及边界点组成了簇,簇中核心的点就是核心对象。
具体算法描述
实际上就是核心对象以及与其密度可达的所有的点的集合
输入
- 样本集 D={x1,...,xN} D = { x 1 , . . . , x N }
- 邻域参数 (ε,MinPts) ( ε , M i n P t s )
算法流程
- 找出所有的核心对象,放入集合中 Ω Ω
- 初始化未访问的样本集合: Γ=D Γ = D
- while(Ω≠∅) w h i l e ( Ω ≠ ∅ )
- Γold=D Γ o l d = D
- 随机选取一个核心对象 o∈Ω o ∈ Ω ,初始化 Q=<o> Q =< o >
- Γ=Γ∖{o} Γ = Γ ∖ { o }
- while(Q≠∅) w h i l e ( Q ≠ ∅ )
- 从 Q Q 中取出样本 q q
- if(q i f ( q 是核心对象 ) )
- 另 Δ=Nε(q)∩Γ Δ = N ε ( q ) ∩ Γ , 即获取核心对象 q q 邻域内的点
- 将 Δ Δ 内的点加入到 Q Q 中
- Γ=Γ∖Δ Γ = Γ ∖ Δ
- endif e n d i f
- endwhile e n d w h i l e
- k=k+1 k = k + 1 ,并且生成聚类簇 Ck=Γold∖Γ C k = Γ o l d ∖ Γ
- Ω=Ω∖Ck Ω = Ω ∖ C k
- endwhile e n d w h i l e
输出
簇划分 C={C1,...,CK} C = { C 1 , . . . , C K }
算法的优缺点
优点:
- 算法不需要指定聚类的数目,但是算法实际上需要另外两个参数 (ε,MinPts) ( ε , M i n P t s ) ,所以这个优点也是勉强。
- 可以聚成任意形状的类,就像开始的图所示
- 能够识别出噪声点
缺点:
- 对高维数据效果不算好
- 如果样本的密度不均, 效果会不理想