Fast R-CNN & Faster R-CNN 论文阅读
为了以后的学习方便,把几篇计算机视觉的论文放上来,仅为自己的学习方便。期间有参考了很多博客和文献,但是我写的仍然很粗糙,存在很多的疑问,这篇文章近期打算研究代码,待更。
在Mask-RCNN的论文阅读中,发现自己差的还很多。这两篇论文作为基于推荐的分割方法的基础之作,开始来打打基础。不过阅读的过程中,还是遇到了很多的问题,参考了很多大佬的讲解,先把自己的简单理解放上来。排版对手机端不友好。
Fast R-CNN论文地址:Fast R-CNN
Faster R-CNN论文地址:Faster r-cnn: Towards real-time object detection with region proposal networks.
大佬写的Fast R-CNN的讲解:Fast R-CNN 论文讲解
大佬的Faster R-CNN的讲解:Faster R-CNN论文讲解
研究问题的背景
近来,深度卷积网络极大地提高了图像分类和物体检测的准确率。相对于物体分类,物体检测是一个需要复杂方法解决的一个难题。复杂性的原因主要有两个:一、多个候选的目标位置需要处理;二、候选的目标的粗略位置需要被重新定义到精确的位置。
基于区域的深度卷积网络R-CNN[1]通过使用深度卷积网络,在物体分类上达到了出色的检测效果。但同时其也存在明显的缺点:
1. 多阶段流水线训练。在R-CNN网络中,首先使用log损失函数针对推荐物体进行微调卷积网络。然后,SVMs适应卷机网络的特征,它取代了通过调优学到的softmax分类器,成为物体检测器。在第三阶段,进行边界框回归。
2. 训练的时间复杂度和空间复杂度高。对于SVM和边界框回归的训练,从每张图片的每个推荐物体中抽取出来特征,再写到硬盘当中。对于非常深的网络,如VGG16,对VOC07训练验证集这个过程需要消耗2.5天。同时这些特征需要数百G的存储空间。
3. 物体检测慢。在测试阶段,每张测试图像的每个推荐物体都要进行特征抽取,在VGG16网络上检测每张图像需要在GPU上耗费47s。
论文的研究内容
先来概述一下 Fast-RCNN[2]的几个优势:
⑴ 比R-CNN和SPPnet更高的检测质量(mAP);
⑵ 训练是单阶段,使用多任务损失函数;
⑶ 训练可以更新所有的网络层;
⑷ 不需要硬盘存储特征缓存;
Faster R-CNN[3]主要改进的是卷积神经网络开始往后面的计算,该部分的计算速度大幅的提升,Selective Search成为了限制计算效率的瓶颈。所以Ross B. Girshick联合Kaiming He一起提出了Faster R-CNN,用Region Proposal Networks (RPN)替代Selective Search。这样做的一个重要意义是算法的所有步骤都包含到一个完整的框架中,实现了端到端的训练。
A、SPP
SPP网络结构和ROI池化图如图1所示:
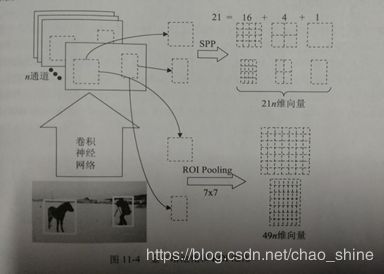
图1 金字塔池化结构
如图1所示,假设输入图片中框柱小马和摄影师的两个框是Selective Search 选出来的框,经没有全连接层的卷积神经网络,到了最后一层输出的n个通道的响应图时,原图像上的两个框也会对应两个感兴趣区域(ROI)。一般常用的分类器,无论是SVM还是浅层神经网络,都需要输入固定的维度。SPP是一种把ROI的信息都转化成固定维度的向量,把每个ROI都给分类器去计算获得结果,并且在进入分类器之前,只需要运行一次卷积神经网络的前向计算,所有的ROI都共享同样的响应图。
SPP把任意大小的向量转化成固定大小的向量的方法还有另一个意义,就是让输入神经网络的图像大小不再固定,在执行分类任务的时候,这种做法的优点是不需要再对图像进行裁剪或者缩放。
SPP[4]用于物体检测相比R-CNN[5]获得了速度上的巨大提升,但仍然继承了一些R-CNN的缺点。最明显的是分阶段训练,不仅麻烦,而且物体框回归训练过程和卷积神经网络的训练过程是割裂,整个参数优化的过程不是一体的,限制了达到更高精度的可能性。
B、Fast R-CNN
针对SPP的缺点,R-CNN的作者在SPP检测的基础上提出了两个主要的改进:第一点是ROI提取特征后,把物体框的回归和分类这两个任务的loss函数融合在一起训练,相当于端到端的多任务训练(end-to-end with a multi-task loss)。这个训练过程不再是多个步骤分别进行,训练效率也更高;第二点是把SPP换成了ROI Pooling。
在计算预测的框和标注框的loss时,采用了一种叫做![]() 的loss计算方法:
的loss计算方法:
![]()
其中,
![]()
其实就是把![]() 和
和![]() 拼一块了,其中小的偏差利用
拼一块了,其中小的偏差利用![]() 计算,大的偏差利用
计算,大的偏差利用![]() 计算。
计算。![]() 对偏差很大的值不是很敏感,但提高了loss计算的稳定性。
对偏差很大的值不是很敏感,但提高了loss计算的稳定性。
(这部分属于摘抄)在这种框架下,因为卷积神经网络计算对每张图像只进行了一次,所以重复计算大都在ROI Pooling之后,于是作者提出用SVD分解忽略次要成分,把全连接层的计算量减小,达到精度损失极其微小的情况下,获得较大幅度的计算速度提高,这也是该论文中的一个小优点。对应的各个网络层的消耗时间如图2所示:
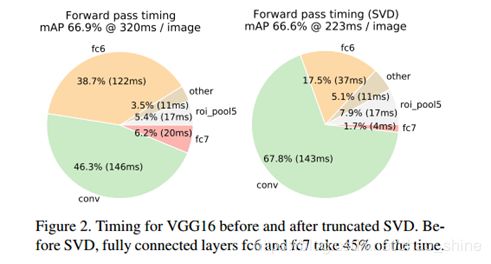
图2 SVD操作后的各个层消耗的时间和占比
Fast R-CNN的网络架构如图3所示:
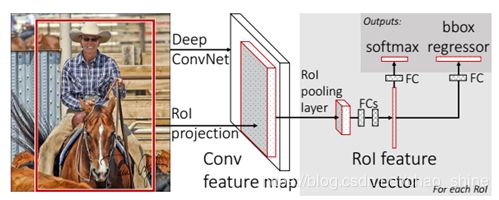
图3 Fast R-CNN网络结构图
C、Faster R-CNN
在本论文中,提出的RPN结构如图4所示:

图4 RPN结构和实例
RPN首先对基础网络的最后一层卷积响应图,按照执行一次![]() 卷积,输出指定通道数(原文中为256,github代码中为512)的响应图。这步相当于用划窗法对响应图进行特征提取,在论文中n的大小为3.也就是
卷积,输出指定通道数(原文中为256,github代码中为512)的响应图。这步相当于用划窗法对响应图进行特征提取,在论文中n的大小为3.也就是![]() 的窗口大小。然后对得到的响应图的每个像素分别进入两个全连接层:一个计算该像素的对应的位置是否头物体的分数,输出是或否的分数;另一个是计算物体框的二维坐标大小,所以有4个输出。其中对于,每一个
的窗口大小。然后对得到的响应图的每个像素分别进入两个全连接层:一个计算该像素的对应的位置是否头物体的分数,输出是或否的分数;另一个是计算物体框的二维坐标大小,所以有4个输出。其中对于,每一个![]() 卷积输出的响应图像素,都尝试用中心在该像素位置,不同大小和不同长宽比的窗口作为anchor box,回归物体框坐标和大小的网络是在anchor box的基础上做偏置。所以假设有k个anchor box,则计算是否有物体分数的输出实际有2k个,计算物体框坐标和大小的实际输出有4k个。
卷积输出的响应图像素,都尝试用中心在该像素位置,不同大小和不同长宽比的窗口作为anchor box,回归物体框坐标和大小的网络是在anchor box的基础上做偏置。所以假设有k个anchor box,则计算是否有物体分数的输出实际有2k个,计算物体框坐标和大小的实际输出有4k个。
基于RPN的物体分数和物体框得到可能的物体框之后,训练时经过NMS和分数从大到小排序筛选出有效的物体框,从中随机选取作为一个batch。然后通过ROI Pooling 进行分类的同时,会进一步对物体框的位置及大小进行回归,ROI Pooling之后的这两个任务对应两个loss,再和RPN的两个loss放一起 就实现了端到端的训练。Faster R-CNN无论是训练以及测试的速度,还是物体检测精度都超过了Fast R-CNN。
可以将Faster R-CNN网络结构看作RPN网络和Fast R-CNN网络结合体,如图5所示:
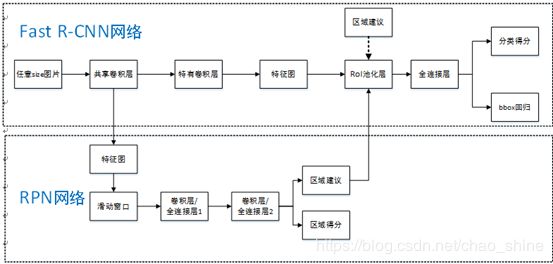
图5 Faster R-CNN网络结构
论文的效果
研究的效果主要通过对比试验体现出来。
⑴ Fast R-CNN:

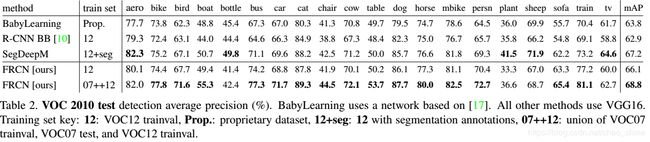

论文中还讨论是否还有其他更高效的方法并进行了对比,例如是否有更好的分类器:

得到的结论是也许会有未发现的密集框技术可以和稀疏推荐效果一样好,但是在论文中未体现。
⑵ Faster R-CNN:
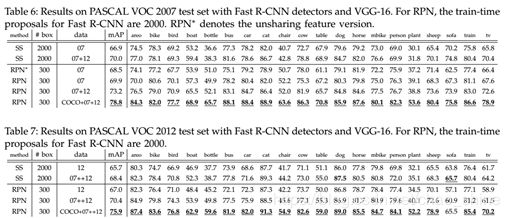
现有的创新
Faster R-CNN 主要由三个部分组成:(1)基础特征提取网络(2)RPN (Region Proposal Network) (3)Fast-RCNN 。其中RPN和Fast-RCNN共享特征提取卷积层,思路上依旧延续提取proposal + 分类的思想。后人在此框架上,推出了一些更新,也主要是针对以上三点。(借鉴博客:Faster R-CNN 深入理解 && 改进方法汇总)
⑴ 更好的特征网络
ResNet;PVANet;
⑵ 更精准更精细的RPN
FPN;more anchors;
⑶ ROI分类方法
R-FCN[7];Mask R-CNN[6] ;
自己产生的问题
由博客Faster R-CNN论文详解和Faster R-CNN论文及源码解读的讲解解决。
参考文献
- Girshick R B, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. computer vision and pattern recognition, 2014: 580-587.
- Girshick R B. Fast R-CNN[J]. international conference on computer vision, 2015: 1440-1448.
- Ren S, He K, Girshick R B, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
- He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
- Girshick R B, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. computer vision and pattern recognition, 2014: 580-587.
- He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. international conference on computer vision, 2017: 2980-2988.
- Dai J, Li Y, He K, et al. R-FCN: Object Detection via Region-based Fully Convolutional Networks[J]. neural information processing systems, 2016: 379-387
附录
附录一:
表1 术语对照表
| 英语表达 |
中文翻译 |
| Object Proposal |
目标推荐 |
| Intersection Over Union (IoU) |
交并比 |
| Regions with CNN features (R-CNN) |
基于区域的卷积神经网络 |
| Region Proposal Networks (RPN) |
区域推荐网络 |
| Singular Value Decomposition (SVD) |
奇异值分解 |
| Non-Maximum Suppression(NMS) |
非极大值抑制 |
| Spatial pyramid pooling networks (SPPnets) |
空间金字塔网络 |
| Pattern Analysis Statistical Modeling and Computational Learning, Visual Object Classes (PASCAL VOC) |
模式识别统计建模和计算学习,视觉目标集 (国际计算机视觉算法竞赛) |
| Mean average precision (mAP) |
平均精度均值 |