【HDFS篇】搭建hadoop伪分布式集群
所谓伪分布式,就是单机模拟多台服务器搭建的过程。只是每个角色都是以进程的方式启动。
基本流程如下:
一,操作系统环境
依赖软件ssh,jdk
环境的配置
java_home
免密钥
时间同步
hosts,hostname
二,hadoop部署
/opt/jw/ 新建目录
profile的修改
java_home 的二次配置
hadoop配置文件修改
角色在哪里启动
备注:检查Java有没有装不要用Java -version 。用jps。【ps看进程,jps=javaps】可第一验证已装jdk。第二说明其etc/profile 文件已经配置了。如果一台服务器用rpm安装后没有配JAVA_HOME 用java-version 也是可以执行的。
安装过程:
1.jdk环境
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH= PATH: P A T H : JAVA_HOME/bin
2.加载配置文件
两种方式,一种source 一种 . /
3.ssh免密钥
ssh-keygen -t dsa -P ’ ’ -f ~/.ssh/id_dsa
解释:-t :type dsa 具体的类型名 -P:密码 -f:文件 .ssh 隐藏目录
id_dsa id_dsa.pub 生成的这两个文件,pub是发给别人的。
先对自己免密钥,同时把密钥文件放在authorized_keys密钥文件里。
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
【使用“>>” 追加的方式,别直接使用“>”这样就把其他的密钥覆盖了。】
4.hadoop解压并配置porfile
export JAVA_HOME=/usr/java/jdk1.7.0_79
export HADOOP_PREFIX=/opt/jw/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin5.hadoop里的Java_home 的二次配置【ssh远程调用不会加载profile文件,所以需要二次配置】
vi hadoop-env.sh 下
export JAVA_HOME=${JAVA_HOME}此处改为 绝对路径
vi mapred-env.sh
vi yarn-env.sh
同样的操作。
6.hadoop自己的配置
参见hadoop官网
Configuration
Use the following:
6.1 etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value> 【备:将localhost改为主机名】
property>
configuration>此次配置一语双关。第一,如果是管理脚本想启动角色的时候读取配置文件,就会知道应该去哪个机器上哪个端口号启动NN。
第二,如果是分布式开发需要写客户端,如果客户端读取到配置文件的时候,就会知道NN在哪里。就可以建立socket连接。
6.2 vi /etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>【配置副本数,伪分布式只可以配成一个】slaves 指定DN在哪里。
将里面的localhost改成主机名,我的是:node01
如果 后续搭建 完全分布式,就需要根据实际的DN的位置配置相应的主机名。
修改默认配置,这里有可选择性修改,如果只修改core.xml里的hadoop.tmp.dir 就可以同时修改hdfs.xml里的2出配置,dfs.namenode.name.dir 和 dfs.datanode.data.dir
6.3 修改default配置
因为这里都是存放对的路径是tmp目录,此目录是操作系统内核直接操作的,不用和用户打招呼的。临时目录是会被清空的。可以删除,但是hdfs的配置里的NN存元数据在磁盘位置也在此tmp目录下。DN也存tmp。所以存在安全隐患。直接修改core的配置多处生效。
修改core的配置信息,重新定义hadoop.tmp.dir的位置覆盖原有路径。
<property>
<name>hadoop.tmp.dirname>
<value>/var/jw/hadoop/localvalue> linux目录下var 目录是存数据的新建此】
property> 6.4 增加secondarynamenode配置信息
有关secondarynamenode的配置信息在hdfs的配置文件中。 配置dfs.namenode.secondary.http-address即可,参见官网
<property>
<name>dfs.namenode.secondary.http-address<name>
<value>node01:50090value>
property>7.执行过程
7.1 初始化fomat 参见官网说明 中的Execution
Format the filesystem:
$ bin/hdfs namenode -format
当发现有如下字样的提示信息时说明成功: has been successfully formatted.
进入var目录下建奶茶是否有jw的文件夹,里面寻找hadoop的目录下有VERSION文件。里面存放的集群的id和block块的id等信息。注意format的过程是轻量级的。只是帮我们创建一些目录及文件。如果此集群不需要推到重来,只需要格式化一次就行了。因此再次格式化会重新生成新的id。是前置的过程,还没有启动。
7.2 正式启动Hadoop
start-dfs.sh
node01: Warning: Permanently added 'node01,192.168.159.36' (RSA) to the list of known hosts.
node01: starting namenode, logging to /opt/jw/hadoop-2.6.5/logs/hadoop-root-namenode-node01.out
node01: starting datanode, logging to /opt/jw/hadoop-2.6.5/logs/hadoop-root-datanode-node01.out
Starting secondary namenodes [node01]
node01: starting secondarynamenode, logging to /opt/jw/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-node01.out想查看日志信息,不要看上面的.out日志信息,看那个目录下的.log文件。
回到
dfs目录下发现多出有一个data和namescecondary目录。data存DN信息,name目录存NN元数据信息。data里面有同样的VERSION文件。说明format的过程产生的VERSION文件,会被其他的角色拷走。会又说回来如果再次格式化,生成的VERSION里的id会和原始的DN里的id不同。不会组成一个集群。DN一旦找不到NN会把自己下线。
通过jps检查是否全部启动。
2116 Jps
1984 SecondaryNameNode
1753 NameNode
1831 DataNode
可通过web页面访问。输入 ip:50070 注意NN 的端口号是:50070
可点击Live Nodes 来查看当前活跃的节点。
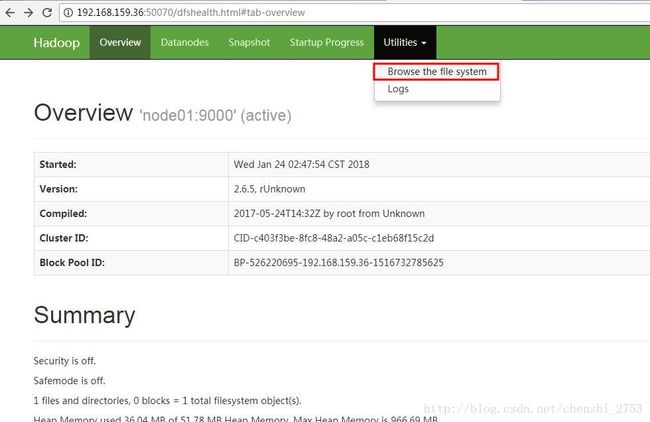
点击次数进入hdfs文件系统的浏览。
7.3 推送文件
第一次搭建文件系统是空的,我们可往上放文件,
此文件系统是NN内存中开辟的假的文件系统,不是本机的文件系统。
通过命令:hdfs 查看 然后再 hdfs dfs 查看。
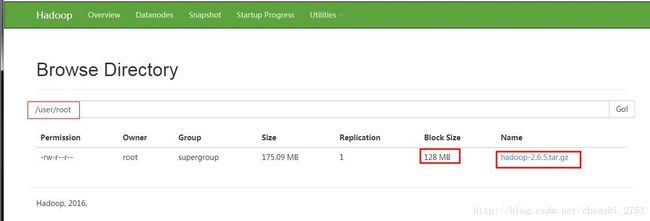
hdfs dfs -mkdir -p /user/root 创建目录。 其中 -p 是递归创建的意思。 user是其家目录。
推送文件:
hdfs dfs -put ./software/file/linux-basic/hadoop-2.6.5.tar.gz
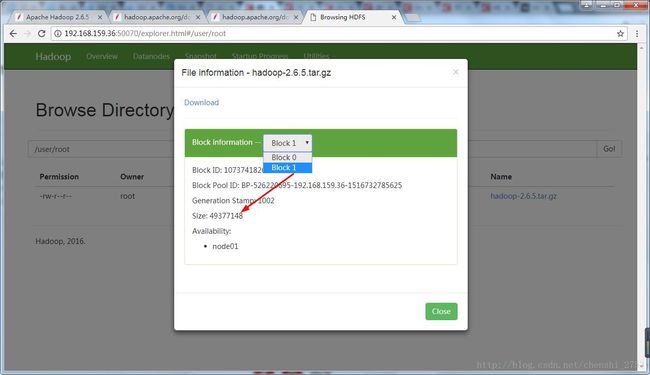
检查block块信息,在7.2下的data文件下存放。
cd /var/jw/hadoop/local/dfs/data/current/BP-526220695-192.168.159.36-1516732785625/current/finalized/subdir0/subdir0/

其中.meta 是对应的元数据信息。
此为存放的block块普通的文件。但计算程序不是直接访问此文件,是通过hdfs封装的IO流访问的。
7.4 自定义大小推送文件
for i in seq 100000;do echo “hello jw $i” >> jw.txt;done
【hdfs限制死块的大小不小于1M】
hdfs dfs -D dfs.blocksize=1048576 -put ./jw.txt /user/root
如果只是想放在家目录下,并且已经创建了目录,root目录,那么后面的家目录路径可不写。
至此伪分布式搭建完成。