Python —— 文件处理
1. 打开文件
open(filename, mode, buffering)mode=‘r’:以只读模式打开文件。若此文件不存在,报错
mode=‘w’:以写模式打开。若此文件不存在,则创建一个;若此文件已存在,则先清空
mode=‘a’:以追加模式打开。若此文件存在,则在文件尾部追加内容
mode=‘r+’或者‘w+’或者a+:以读写模式打开
mode=b:以二进制只读模式打开
buffering:设置缓存区,可以缺省,一般用-1表示系统默认缓冲区域。
2. 读文件
(1)file.read( n ):表示读文件的前n个字符
(2)file.readline( n ):表示读文件的前n**行**
(3)file.readlines( ):表示把文件从头到尾读出来,并保存为一个列表
3. 写文件
(1)file.write( ):表示把字符串写入
(2)file.writelines( ):表示把一个列表写入
4. 关闭文件
(1)普通方法:
file.open(r'abc.txt')
file.readline
file.close() # 只要文件被open过,就必须close(2)with方法——自动关闭,懒人专用
with open(r'abc.txt') as f:
f.readline() # 此方法会自动关闭被打开的文档5. 文件指针
文件指针是指文件在读写过程中的位置问题。如:从某文件的第n个字符开始插入一段话
如下图:
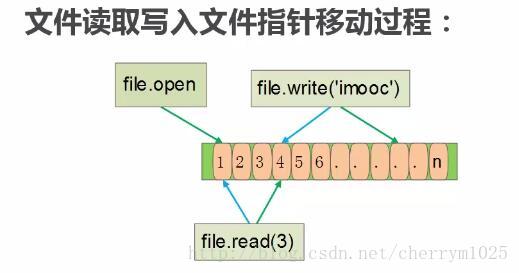
文件打开后,读取时指针先指向头部,从第一个字节再向后读取了3个字节后(第四个字节),再写入内容时指针默认指向第四个字节
(1)file.seek( ): 定位到文件某个位置
file.seek(offset, whence) #将文件指针从某指定的位置向左/向右移动多少位字节offset:指针偏移量
whence:指定指针位置,0表示文件头,1表示当前位置,2表示文件尾
# 'abc.txt'文件内容如下:123456789
# 从头读3个字符
f = open(r'abc.txt')
f.seek(2,0) # 从文件头后移2个字符
f.read(3)
>>>345
# 从文件尾读取3个字符
f = open(r'abc.txt')
f.seek(-3,2) # 从文件尾部前移3个字符
f.read(3)
>>>789 (2)file.tell( ):指针当前位置
file.tell( ) #表示当前指针位置举个栗子:加入现有文件abc.txt,文件内容是”0123456789”
f = open(abc.txt, 'r+') #以读写方式打开abc.txt
import os # 记得在用文件指针方法时必须导入OS模块
f.tell()
>>>0 # 指针位置在文件头部
f.read(3) # 读取文件abc.txt的前三个字节
>>>012
f.tell()
>>>3 # 此时指针在文件的第3个字节处
f.seek(0, os.SEEK_SET) # 使指针回到文章起始位置
f.tell()
>>>0 # 指针又回到起始位置
f.seek(-2, os.SEEK_END) # 使指针指向文件结束位置然后向前移动2个字节
f.tell()
>>>7 # 文章结束位置时9,-2表示指针前移2个字节,即指向76. 文件的处理 —— os模块
(1)重命名文件rename
os.rename(原文件名,目标文件名)(2)删除文件remove
os.remove('abc.txt')(3)提取文件路径dirname
p = 'C:/study/abc.txt'
os.path.dirname(p)
>>>'C:/study'(4)提取文件名basename
p = 'C:/study/abc.txt'
os.path.basename(p)
>>>abc.txt(5)分割文件后缀split
p = 'C:/study/abc.txt'
os.path.split(p)
>>>('C:/study','abc.txt')(6)创建目录mkdir
if not os.path.exists('abc.txt'): # 先判断此目录是否存在
os.mkdir('abc.txt') # 若不存在,则创建(7)列出当前目录下所有文件listdir&walk
假设当前目录下有abc.txt、demo.py、test01、234.txt。
其中:test01是文件夹,其余是文件
# 列出当前目录所有内容
print os.path.listdir('.')
>>>['abc.txt','demo.py','test01','234.txt']# 列出当前目录所有内容,且分别显示文件和文件夹
print list(os.walk('.')) # walk()会生成当前目录下所有文件+文件夹
[('.', [abc.txt,demo.py,234.txt],[test01]), ('.\\test01',[],[])](8)返回当前目录getcwd
os.getcwd()
>>>6. 栗子
假设有一个较Test的目录,包含2个文件:文件1是abc.txt,文件2是新建的空文件demo.py。
abc.txt内容如下:
Google
Baidu
Wangyi
Facebook题目1:把abc.txt的内容读出了,按照下面的格式写到一个新文件abc_new.txt中:
1.Google
2.Baidu
3.Wangyi
4.Facebook答题:
粗糙写法:
f1 = open(r'abc.txt')
contents = f1.readlines() # 读取abc.txt所有内容,保存为列表contents
f1.close()
for i in range(0,len(contents)):
content[i] = str(i+1) + ':' +content[i] # 在每一行之前加'序号:'
f2 = open(r'abc_new',w) # 以写模式打开abc_new.txt,若没有则创建
f2.writelines(contents) # 把加了序号后的内容写进去
f2.close()整理&改进
def read_file(): # 把读文件抽象成一个函数
with open(r'abc.txt') as f1:
content = f1.readlines()
return content
def write_file(cont): # 把写文件抽象成一个函数
with open(r'abc_new',w) as f2:
f2.writelines(cont)
contList = [] # 定义一个列表,用来获取文件内容
for i,j in enumerate(read_file): # 修改内容
contList.append(str(i+1) + ':' +j)
write_file(conList) # 调用写函数 题目2:此时Test目录下有三个文件:abc123.txt、abc_new123.txt、demo.py
要求给所有.txt文件重命名,变成如下文件名:
abc.txt
abc_new.txt
demo.py答题:
inport os
def rename_file():
f.list = os.listdir('.') # 列出Test目录下的所有文件
for file_name in f.list:
if file_name.endswith('txt'): # 过滤出.txt文件
# 修改文件名:去掉文件名中的数字
new_name = file_name.transtrate(None,'0123456789')
print new_name
os.rename(file_name, new_name) # 重命名
rename_file()