Redis从入门到放弃系列(三) List
本文例子基于:5.0.4 List是Redis中一种比较常见的数据结构,其实现为quicklist,quicklist是一个ziplist的双向链表
Redis从入门到放弃系列(一) String
Redis从入门到放弃系列(二) Hash
首先让我们来看一下该如何在redis里面使用List类型
//设置key的列表为value
lpush key value [value...]
代码示例:
//栈的用法,rpush rpop一样~ 通过rpush,lpop相当于堆的用法
> lpush books java python c
(integer) 3
> lpop books
"c"
> lpop books
"python"
> lpop books
"java"
----------------------------------
//返回列表key指定区间的元素,区间偏移量start跟stop指定
//start跟stop的下表都是以0为底
> lrange books 0 2
1) "c"
2) "python"
3) "java"
----------------------------------
//ltrim可以作为一个定长的list,每次都可以获取到最新的2条数据
> lpush books java python c c++
(integer) 4
> ltrim books 0 1
OK
> lrange books 0 -1
1) "c++"
2) "c"
----------------------------------
//当给定列表内没有任何元素可供弹出的时候,连接将被blpop ,brpop命令阻塞,直到等待超时或发现可弹出元素为止。
//设置超时 1秒
> BLPOP books 1
1) "books"
2) "c++"
> BLPOP books 1
1) "books"
2) "c"
> BLPOP books 1
(nil)
(1.05s)
----------------------------------
至此,redis list的用法先告一段落.
源码解析
本文开头的时候讲list实现为quicklist,quicklist是一个ziplist的双向链表,那么其内部结构是怎样的呢?
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
从上面我们可以知道,quicklist是一个的双向链表,所以当我们使用lpush,rpop等操作是O(1)了。
ziplist本身也是一个能够维持数据先后顺序的列表(按照插入位置),而且是一个内存紧凑的列表。 当我们要表示list拥有12个数据项,这时候就会有可能有多种选择了,例如3个节点的quicklist,每个节点ziplist又包含4个数据项.或者2个节点的quicklist,每个节点ziplist又包含6个数据项 那么redis是如何选择的呢?我们可以再redis.conf找到蛛丝马迹~
# Lists are also encoded in a special way to save a lot of space.
# The number of entries allowed per internal list node can be specified
# as a fixed maximum size or a maximum number of elements.
# For a fixed maximum size, use -5 through -1, meaning:
# -5: max size: 64 Kb <-- not recommended for normal workloads
# -4: max size: 32 Kb <-- not recommended
# -3: max size: 16 Kb <-- probably not recommended
# -2: max size: 8 Kb <-- good
# -1: max size: 4 Kb <-- good
# Positive numbers mean store up to _exactly_ that number of elements
# per list node.
# The highest performing option is usually -2 (8 Kb size) or -1 (4 Kb size),
# but if your use case is unique, adjust the settings as necessary.
list-max-ziplist-size -2
# Lists may also be compressed.
# Compress depth is the number of quicklist ziplist nodes from *each* side of
# the list to *exclude* from compression. The head and tail of the list
# are always uncompressed for fast push/pop operations. Settings are:
# 0: disable all list compression
# 1: depth 1 means "don't start compressing until after 1 node into the list,
# going from either the head or tail"
# So: [head]->node->node->...->node->[tail]
# [head], [tail] will always be uncompressed; inner nodes will compress.
# 2: [head]->[next]->node->node->...->node->[prev]->[tail]
# 2 here means: don't compress head or head->next or tail->prev or tail,
# but compress all nodes between them.
# 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->[tail]
# etc.
list-compress-depth 0
list-max-ziplist-size
当设置为正数意味着最多只能储存该数量的元素,redis的作者建议设置为-1 or -2,设置每个quicklist节点上的ziplist能储存元素的大小~ 当列表很长的时候,中间的数据被访问的频率就有可能很低,那么在这种情况下,list提供了一个参数能够将中间的数据压缩~
list-compress-depth 0
这个参数表示quicklist两端不被压缩的节点数.head节点跟tail节点总是不压缩的,方便在list的两端进行快速存取
- 0: 是个特殊值,表示都不压缩。这是Redis的默认值。
- 1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
- 2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
- 3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
- 依此类推…
quickList结构图如下图所示: 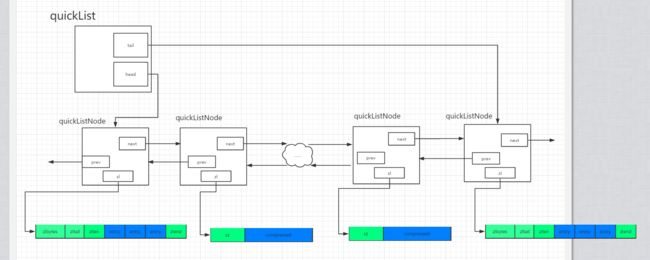
图中对应的ziplist的配置大小和节点压缩深度配置如下:
list-max-ziplist-size 3
list-compress-depth 1
在这里例子中我们可以看到,quickList两端各有一个节点没有被压缩,它们的数据指针指向真正的ziplist(即zl的指向).中间的其他节点是被压缩过的,它们的数据指针指向quicklistLZF
应用场景
1.消息队列(无ack机制)
//生产者使用lpush将消息放入list中,消费者就可以通过rpop取出该消息,并且可以保证消息的有序性。
>lpush message "ces"
(integer) 1
>rpop message
"ces"
2.时间轴
//一种场景就是当用户发送一条微博,通过lpush将它存放到list中,然后通过lrange就可以取出最近的最新的微博信息了
> lpush weibo "xiaoxi1"
(integer) 1
> lpush weibo "xiaoxi2"
(integer) 2
> lpush weibo "xiaoxi3"
(integer) 3
> lrange weibo 0 9
1) "xiaoxi3"
2) "xiaoxi2"
3) "xiaoxi1"
