- 如何利用大数据与AI技术革新相亲交友体验
h17711347205
回归算法安全系统架构交友小程序
在数字化时代,大数据和人工智能(AI)技术正逐渐革新相亲交友体验,为寻找爱情的过程带来前所未有的变革(编辑h17711347205)。通过精准分析和智能匹配,这些技术能够极大地提高相亲交友系统的效率和用户体验。大数据的力量大数据技术能够收集和分析用户的行为模式、偏好和互动数据,为相亲交友系统提供丰富的信息资源。通过分析用户的搜索历史、浏览记录和点击行为,系统能够深入了解用户的兴趣和需求,从而提供更
- 未来软件市场是怎么样的?做开发的生存空间如何?
cesske
软件需求
目录前言一、未来软件市场的发展趋势二、软件开发人员的生存空间前言未来软件市场是怎么样的?做开发的生存空间如何?一、未来软件市场的发展趋势技术趋势:人工智能与机器学习:随着技术的不断成熟,人工智能将在更多领域得到应用,如智能客服、自动驾驶、智能制造等,这将极大地推动软件市场的增长。云计算与大数据:云计算服务将继续普及,大数据技术的应用也将更加广泛。企业将更加依赖云计算和大数据来优化运营、提升效率,并
- 架构评审的自动化与人工智能: 如何提高效率
光剑书架上的书
架构自动化人工智能运维
1.背景介绍架构评审是软件开发过程中的一个关键环节,它旨在确保软件架构的质量、可维护性和可扩展性。传统的架构评审通常是由人工进行,需要大量的时间和精力。随着大数据技术和人工智能的发展,自动化和人工智能技术已经开始应用于架构评审,从而提高评审的效率和准确性。在本文中,我们将讨论如何通过自动化和人工智能技术来提高架构评审的效率。我们将从以下几个方面进行讨论:背景介绍核心概念与联系核心算法原理和具体操作
- 使用python实现微信小程序自动签到
光头哥不光头
python
学校:重庆财经职业学院学院:应用技术学院专业班级:大数据技术与应用05班名字:吴雨璇指导老师:张彤老师一:使用python实现微信小程序自动签到意义1.首先对于咱们的APP有很大的作用,那就是当用户点击签到以后,平台就有那么多用户在使用,签到的人越多,产品的活跃度就越高。2.还有一点就是大家应该能够想到,那就是用户点击签到是在首页,有些点开就需要进行签到,点击较多,对于产品销售是非常重要的。3.微
- starrocks和clickhouse数据库比较
CodeMaster_37714848
clickhouse数据库
Starrocks和ClickHouse都是用于数据分析的数据库,但它们的设计理念和用途有所不同。下面是这两者的一些主要比较点:1.基础架构与设计目标Starrocks:Starrocks是一个专注于实时数据分析的平台,常用于大数据处理和商业智能应用。它设计用于高效处理大规模数据集,并且支持复杂查询和数据处理。支持多种数据源的集成,并且可以与其他大数据技术(如Hadoop、Spark)协同工作。C
- 大数据技术之Hadoop(一)
pauls
Hadoop概述1.1Hadoop是什么Hadoop是什么1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。2)主要解决,海量数据的存储和海量数据的分析计算问题。3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。Hadoop生态1.2Hadoop发展历史(了解)Hadoop发展历史1)Hadoop创始人DougCutting,为了实现与Google类似
- Hive 的 SerDe 是什么?
Shockang
大数据技术体系大数据hive
前言本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系正文hive的SerDe是什么SerDe是Serializer/Deserializer的简写。hive使用SerDe进行行对象的序列与反序列化。最后实现把文件内容映射到hive表中的字段数据类型。为了更好的阐
- 【大数据Big DATA】大数据解决方案,提供完整的大数据采集,大数据存储,大数据处理,具体业务应用解决方案
_晓夏_
JAVA大数据大数据解决方案大数据BIGDATA大数据采集大数据存储大数据处理大数据分析
大数据解决方案是指利用大数据技术,结合企业实际业务需求,为企业提供数据采集、存储、处理、分析和报告等一站式服务,以帮助企业更好地利用大数据提高运营效率、优化决策制定。以下是一些常见的大数据解决方案:一、数据采集数据采集是大数据解决方案的起点,涉及从各种数据源中抓取和收集数据。常见的大数据采集工具包括Flume、Scribd等,这些工具可以帮助企业快速、高效地采集各类数据。二、数据存储大数据存储解决
- Spark一些个人总结
易逑实战数据
大数据sparkbigdatascala
文章目录前言一、Spark是什么二、Spark用来做什么三、Spark的优势是什么四、为什么用Spark五、Spark解决了什么问题总结前言随着大数据技术的发展,一些更加优秀的组件被提了出来,比如现在最常用的Spark组件,基于RDD原理在大数据处理中占据了越来越重要的作用。在此我们探索了Spark的原理,以及其在大数据开发中的重要作用。一、Spark是什么Spark是一个用来实现快速,通用的集群
- 系统架构师考试学习笔记第三篇——架构设计高级知识(13)未来信息综合技术
SheldonK
软件架构师学习分享学习笔记
本课时考点:第13课时主要学习信息物理系统技术、人工智能技术、机器人技术、边缘计算、数字孪生体技术以及云计算和大数据技术等内容。根据考试大纲,本课时知识点会涉及单项选择题(约占3~5分)和下午案例题(25分),论文也会有覆盖。本课时知识架构如图13.1所示。一、信息物理系统技术概述1.信息物理系统的概念信息物理系统(Cyber-PhysicalSystem,CPS),最早由美国国家航空航天局于19
- Mac 安装Hadoop教程(HomeBrew安装)
追光天使
macoshadoop大数据
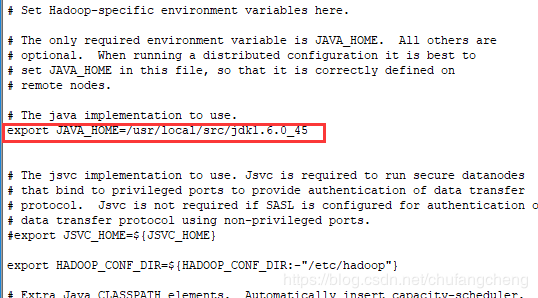
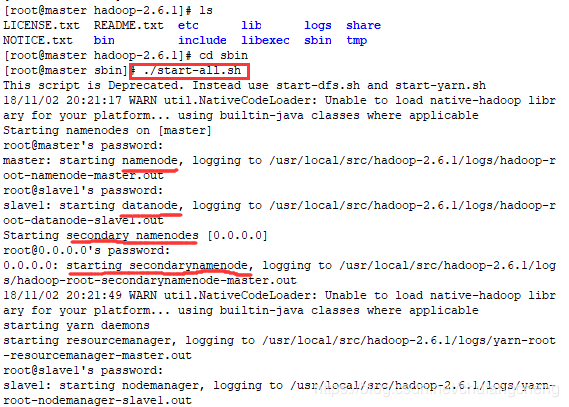
1.引言本教程旨在介绍在Mac电脑上安装Hadoop,便于编程开发人员对大数据技术的熟悉和掌握。2.前提条件2.1安装JDK想要在你的Mac电脑上安装Hadoop,你必须首先安装JDK。具体安装步骤这里就不详细描述了。你可参考Mac安装JDK8。2.2配置ssh环境在Mac下配置ssh环境,防止后面启动hadoop时出现Connectionrefused连接被拒绝的错误。sshlocalhost执
- 2024年(第7届)“泰迪杯”数据分析技能赛通知
泰迪智能科技01
泰迪杯大数据人工智能
由泰迪杯数据分析技能赛组织委员会、广东泰迪智能科技股份有限公司主办,广东省工业与应用数学学会、人民邮电出版社和北京泰迪云智信息技术研究院协办的“泰迪杯”数据分析技能赛(以下简称竞赛)即将开展。竞赛目的在于以赛促学、以赛促教、以赛促改、以赛促创,实现大数据技术技能人才培养的“岗课赛证”融通,深化教学标准与岗位标准、教学过程与生产过程的对接,培养更多升级版的高层次高素质技术技能人才。竞赛时间安排报名起
- 大数据技术之Flume 企业开发案例——自定义 Interceptor(8)
大数据深度洞察
Flumeflume大数据
目录自定义Interceptor1)案例需求2)需求分析3)实现步骤创建一个Maven项目,并引入以下依赖。定义CustomInterceptor类并实现Interceptor接口。编辑flume配置文件分别在hadoop12,hadoop13,hadoop14上启动flume进程,注意先后顺序。在hadoop12使用netcat向localhost:44444发送字母和数字。观察hadoop13
- 大数据技术之HBase 与 Hive 集成(7)
大数据深度洞察
Hbase大数据hbasehive
目录使用场景HBase与Hive集成使用1)案例一2)案例二使用场景如果大量的数据已经存放在HBase上面,并且需要对已经存在的数据进行数据分析处理,那么Phoenix并不适合做特别复杂的SQL处理。此时,可以使用Hive映射HBase的表格,之后通过编写HQL进行分析处理。HBase与Hive集成使用Hive安装https://blog.csdn.net/qq_45115959/article/
- 大数据技术之Flume 数据流监控——Ganglia 的安装与部署(11)
大数据深度洞察
Flume大数据flume
目录Flume数据流监控Ganglia的安装与部署Ganglia组件介绍1)安装Ganglia2)在hadoop12修改配置文件/etc/httpd/conf.d/ganglia.conf3)在hadoop12修改配置文件/etc/ganglia/gmetad.conf4)在hadoop12,hadoop13,hadoop14修改配置文件/etc/ganglia/gmond.conf5)在hado
- Hadoop 中的大数据技术:调优篇(3)
大数据深度洞察
大数据hadoop分布式
HDFS—故障排除NameNode故障处理需求NameNode进程崩溃且存储的数据丢失,如何恢复NameNode?故障模拟终止NameNode进程[lzl@hadoop12current]$kill-919886删除NameNode存储的数据[
[email protected]]$rm-rf/opt/module/hadoop-3.1.3/data/dfs/name/*问题解决从Se
- 大数据技术之Flume
okbin1991
大数据flumejavahadoop开发语言
第1章Flume概述1.1Flume定义Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。1.2Flume基础架构Flume组成架构如下图所示。1.2.1AgentAgent是一个JVM进程,它以事件的形式将数据从源头送至目的。Agent主要有3个部分组成,Source、Channel、Sink。1.2.2Sourc
- 大数据技术之HBase API(3)
大数据深度洞察
Hbase大数据hbase数据库
目录HBaseAPI环境准备创建连接单线程创建连接多线程创建连接DDLDMLHBaseAPI环境准备新建项目后,在pom.xml中添加如下依赖:org.apache.hbasehbase-server2.4.11org.glassfishjavax.elorg.glassfishjavax.el3.0.1-b06注意:javax.el包虽然会报错不存在,但这仅是一个测试用的依赖,不会影响实际使用。
- 大数据技术之HBase整合 Phoenix(6)
大数据深度洞察
Hbase大数据hbase数据库
目录HBase整合PhoenixPhoenix简介Phoenix定义为什么使用PhoenixPhoenix快速入门安装1)官网地址2)Phoenix部署PhoenixShell操作Table表的映射数字类型说明PhoenixJDBC操作Phoenix二级索引二级索引配置文件全局索引(globalindex)包含索引(coveredindex)本地索引(localindex)HBase整合Phoen
- 大数据技术之Zookeeper概述(1)
大数据深度洞察
Zookeeper大数据zookeeper分布式云原生
目录Zookeeper入门概述Zookeeper的主要特点包括:Zookeeper的应用场景:Zookeeper的基本概念:架构:Zookeeper工作机制Zookeeper数据结构Znode(ZookeeperNode)Znode的类型Znode路径Znode属性Watcher监听器使用示例总结Zookeeper入门概述Zookeeper是一个分布式的、开放源码的协调服务,用于大型应用中管理和协
- 综合治税的发展前景
alankuo
人工智能人工智能
综合治税的发展前景较为广阔,主要体现在以下几个方面:-技术应用持续深化:-大数据与人工智能助力精准治税:随着大数据技术的不断发展,税务部门能够整合来自多部门、多渠道的海量数据,包括企业的财务数据、交易数据、银行流水等,通过对这些数据的深度分析和挖掘,可以精准识别税收风险点和潜在的偷逃税行为。例如,利用大数据分析企业的销售数据与申报纳税数据的匹配度,发现异常及时预警和查处。人工智能技术则可以辅助税务
- Kylin的工作原理及使用分享操作指南
vvvae1234
kylin
ApacheKylin是一个分布式的分析引擎,专为大数据环境中的快速分析和查询而设计。它通过构建OLAP(联机分析处理)立方体,使得对海量数据的实时分析成为可能,极大地提升了数据查询的效率。本文将详细介绍Kylin的工作原理,结合实际操作案例,分享如何有效使用Kylin进行大数据分析。1.Kylin概述Kylin是一个开源项目,支持SQL查询,兼容与Hive和MapReduce等大数据技术的集成。
- 《未来二十年,AI、区块链、云与大数据技术引领全球变革》
久绊A
文献/论文人工智能区块链云计算大数据
摘要在未来二十年,全球社会与经济将深刻受到人工智能(AI)、区块链(Blockchain)、云计算(Cloud)和大数据(Data)四大核心技术的驱动。这些技术不仅从宏观上重塑产业结构,更在微观层面显著提升生活品质与效率。本文通过详尽的案例分析,结合国内外最新研究成果,深入剖析这四大技术如何在教育、智能家居、农业、金融等多个关键领域产生深远影响。关键字人工智能(AI)、区块链(Blockchain
- 向量数据库 Faiss 的搭建与使用
eqa11
数据库
向量数据库Faiss的搭建与使用一、引言在人工智能和大数据技术飞速发展的今天,向量数据库作为处理高维数据检索的关键技术,越来越受到重视。Faiss,作为由MetaAI(原FacebookAIResearch)开源的高效相似性搜索库,以其卓越的性能和灵活性,成为众多技术选型中的佼佼者。本文将深入探讨Faiss的搭建和使用,旨在为读者提供一个全面而详细的指南。二、Faiss简介与环境搭建1、Faiss
- 知识分享系列三:大数据技术(上)
jinruimeng
知识分享大数据
本文系统地介绍了大数据技术的相关知识,由于篇幅比较长,分为上下两部分,其中上半部分先介绍基本概念、核心领域,下半部分介绍主要技术、平台架构,以及相关企业案例。目录一、基本概念1.1从数据资源到大数据1.2从大数据到数据要素二、核心领域2.1概述2.2数据存储与计算2.2.1发展历程2.2.2发展特点2.2.2.1云化改造全面加速2.2.2.2融合一体化持续加深2.2.2.3安全能力快速补强2.2.
- Distrii办伴:空间+科技+服务 解决企业办公全生命周期需求
娱扒小公主
ToC市场风口之后,ToB的春天眼看来临。在消费级市场,中国BAT力抗欧美的谷歌、脸书、亚马逊。然而拥有相当体量企业市场的中国,却没有一个知名的企业服务巨头。随着人工智能、大数据技术的应用场景逐步扩大,更丰富、更落地的企业服务场景将在不远的未来不断涌现。作为一家自创立之初就专注于提供智慧办公解决方案的科技公司,Distrii办伴始终坚持以科技为内核,为企业带来更便捷高效的服务。三年来,办伴率旗下三
- 大数据技术之Flume 企业开发案例——负载均衡和故障转移(6)
大数据深度洞察
Flume大数据flume负载均衡
目录负载均衡和故障转移1)案例需求2)需求分析3)实现步骤负载均衡和故障转移1)案例需求使用Flume1监控一个端口,其sink组中的sink分别对接Flume2和Flume3,采用FailoverSinkProcessor,实现故障转移的功能。2)需求分析故障转移案例3)实现步骤准备工作在/opt/module/flume/job目录下创建group2文件夹[lzl@hadoop12job]$c
- Spring Boot实战:使用Spring Cloud Stream处理实时交易数据
潘多编程
springboot后端java
随着金融市场的快速发展以及大数据技术的广泛应用,实时处理交易数据变得越来越重要。SpringBoot和SpringCloudStream为开发者提供了一个强大的工具组合来构建这样的系统。本文将介绍如何使用这些工具来创建一个能够接收、处理并转发实时交易数据的应用程序。1.引言在金融市场中,交易数据通常需要快速地被采集、处理和分析。例如,股票价格的变动、订单的执行情况等都需要及时地被记录下来,并且根据
- 大数据技术之Zookeeper安装 (2)
大数据深度洞察
Zookeeper大数据hadoopzookeeper
目录下载地址本地模式安装1)安装前准备2)配置修改3)操作Zookeeper配置参数解读Zookeeper集群操作集群规划解压安装配置服务器编号配置zoo.cfg文件集群操作Zookeeper集群启动停止脚本创建脚本增加脚本执行权限Zookeeper集群启动脚本Zookeeper集群停止脚本Zookeeper选举机制(面试重点)首次启动选举非首次启动选举关键术语解释下载地址官网首页:ApacheZ
- 大数据技术之Flume事务及内部原理(3)
大数据深度洞察
Flumeflume大数据
目录FlumeAgent架构概述FlumeAgent内部工作流程FlumeAgent的配置FlumeAgent内部重要组件ChannelSelectorSinkProcessorApacheFlume是一个分布式的、可靠的、可用的服务,用于有效地收集、聚合和移动大量日志数据。它具有简单灵活的架构,基于流式数据流动模型。Flume主要由三个核心组件组成:Source(源)、Channel(通道)和S
- java线程Thread和Runnable区别和联系
zx_code
javajvmthread多线程Runnable
我们都晓得java实现线程2种方式,一个是继承Thread,另一个是实现Runnable。
模拟窗口买票,第一例子继承thread,代码如下
package thread;
public class ThreadTest {
public static void main(String[] args) {
Thread1 t1 = new Thread1(
- 【转】JSON与XML的区别比较
丁_新
jsonxml
1.定义介绍
(1).XML定义
扩展标记语言 (Extensible Markup Language, XML) ,用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XML使用DTD(document type definition)文档类型定义来组织数据;格式统一,跨平台和语言,早已成为业界公认的标准。
XML是标
- c++ 实现五种基础的排序算法
CrazyMizzz
C++c算法
#include<iostream>
using namespace std;
//辅助函数,交换两数之值
template<class T>
void mySwap(T &x, T &y){
T temp = x;
x = y;
y = temp;
}
const int size = 10;
//一、用直接插入排
- 我的软件
麦田的设计者
我的软件音乐类娱乐放松
这是我写的一款app软件,耗时三个月,是一个根据央视节目开门大吉改变的,提供音调,猜歌曲名。1、手机拥有者在android手机市场下载本APP,同意权限,安装到手机上。2、游客初次进入时会有引导页面提醒用户注册。(同时软件自动播放背景音乐)。3、用户登录到主页后,会有五个模块。a、点击不胫而走,用户得到开门大吉首页部分新闻,点击进入有新闻详情。b、
- linux awk命令详解
被触发
linux awk
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
awk处理过程: 依次对每一行进行处理,然后输出
awk命令形式:
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v]大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=val
- 各种语言比较
_wy_
编程语言
Java Ruby PHP 擅长领域
- oracle 中数据类型为clob的编辑
知了ing
oracle clob
public void updateKpiStatus(String kpiStatus,String taskId){
Connection dbc=null;
Statement stmt=null;
PreparedStatement ps=null;
try {
dbc = new DBConn().getNewConnection();
//stmt = db
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
矮蛋蛋
zookeeper
原文地址:
http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
安装和配置详解
本文介绍的 Zookeeper 是以 3.2.2 这个稳定版本为基础,最新的版本可以通过官网 http://hadoop.apache.org/zookeeper/来获取,Zookeeper 的安装非常简单,下面将从单机模式和集群模式两
- tomcat数据源
alafqq
tomcat
数据库
JNDI(Java Naming and Directory Interface,Java命名和目录接口)是一组在Java应用中访问命名和目录服务的API。
没有使用JNDI时我用要这样连接数据库:
03. Class.forName("com.mysql.jdbc.Driver");
04. conn
- 遍历的方法
百合不是茶
遍历
遍历
在java的泛
- linux查看硬件信息的命令
bijian1013
linux
linux查看硬件信息的命令
一.查看CPU:
cat /proc/cpuinfo
二.查看内存:
free
三.查看硬盘:
df
linux下查看硬件信息
1、lspci 列出所有PCI 设备;
lspci - list all PCI devices:列出机器中的PCI设备(声卡、显卡、Modem、网卡、USB、主板集成设备也能
- java常见的ClassNotFoundException
bijian1013
java
1.java.lang.ClassNotFoundException: org.apache.commons.logging.LogFactory 添加包common-logging.jar2.java.lang.ClassNotFoundException: javax.transaction.Synchronization
- 【Gson五】日期对象的序列化和反序列化
bit1129
反序列化
对日期类型的数据进行序列化和反序列化时,需要考虑如下问题:
1. 序列化时,Date对象序列化的字符串日期格式如何
2. 反序列化时,把日期字符串序列化为Date对象,也需要考虑日期格式问题
3. Date A -> str -> Date B,A和B对象是否equals
默认序列化和反序列化
import com
- 【Spark八十六】Spark Streaming之DStream vs. InputDStream
bit1129
Stream
1. DStream的类说明文档:
/**
* A Discretized Stream (DStream), the basic abstraction in Spark Streaming, is a continuous
* sequence of RDDs (of the same type) representing a continuous st
- 通过nginx获取header信息
ronin47
nginx header
1. 提取整个的Cookies内容到一个变量,然后可以在需要时引用,比如记录到日志里面,
if ( $http_cookie ~* "(.*)$") {
set $all_cookie $1;
}
变量$all_cookie就获得了cookie的值,可以用于运算了
- java-65.输入数字n,按顺序输出从1最大的n位10进制数。比如输入3,则输出1、2、3一直到最大的3位数即999
bylijinnan
java
参考了网上的http://blog.csdn.net/peasking_dd/article/details/6342984
写了个java版的:
public class Print_1_To_NDigit {
/**
* Q65.输入数字n,按顺序输出从1最大的n位10进制数。比如输入3,则输出1、2、3一直到最大的3位数即999
* 1.使用字符串
- Netty源码学习-ReplayingDecoder
bylijinnan
javanetty
ReplayingDecoder是FrameDecoder的子类,不熟悉FrameDecoder的,可以先看看
http://bylijinnan.iteye.com/blog/1982618
API说,ReplayingDecoder简化了操作,比如:
FrameDecoder在decode时,需要判断数据是否接收完全:
public class IntegerH
- js特殊字符过滤
cngolon
js特殊字符js特殊字符过滤
1.js中用正则表达式 过滤特殊字符, 校验所有输入域是否含有特殊符号function stripscript(s) { var pattern = new RegExp("[`~!@#$^&*()=|{}':;',\\[\\].<>/?~!@#¥……&*()——|{}【】‘;:”“'。,、?]"
- hibernate使用sql查询
ctrain
Hibernate
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.hibernate.Hibernate;
import org.hibernate.SQLQuery;
import org.hibernate.Session;
import org.hibernate.Transa
- linux shell脚本中切换用户执行命令方法
daizj
linuxshell命令切换用户
经常在写shell脚本时,会碰到要以另外一个用户来执行相关命令,其方法简单记下:
1、执行单个命令:su - user -c "command"
如:下面命令是以test用户在/data目录下创建test123目录
[root@slave19 /data]# su - test -c "mkdir /data/test123"
- 好的代码里只要一个 return 语句
dcj3sjt126com
return
别再这样写了:public boolean foo() { if (true) { return true; } else { return false;
- Android动画效果学习
dcj3sjt126com
android
1、透明动画效果
方法一:代码实现
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState)
{
View rootView = inflater.inflate(R.layout.fragment_main, container, fals
- linux复习笔记之bash shell (4)管道命令
eksliang
linux管道命令汇总linux管道命令linux常用管道命令
转载请出自出处:
http://eksliang.iteye.com/blog/2105461
bash命令执行的完毕以后,通常这个命令都会有返回结果,怎么对这个返回的结果做一些操作呢?那就得用管道命令‘|’。
上面那段话,简单说了下管道命令的作用,那什么事管道命令呢?
答:非常的经典的一句话,记住了,何为管
- Android系统中自定义按键的短按、双击、长按事件
gqdy365
android
在项目中碰到这样的问题:
由于系统中的按键在底层做了重新定义或者新增了按键,此时需要在APP层对按键事件(keyevent)做分解处理,模拟Android系统做法,把keyevent分解成:
1、单击事件:就是普通key的单击;
2、双击事件:500ms内同一按键单击两次;
3、长按事件:同一按键长按超过1000ms(系统中长按事件为500ms);
4、组合按键:两个以上按键同时按住;
- asp.net获取站点根目录下子目录的名称
hvt
.netC#asp.nethovertreeWeb Forms
使用Visual Studio建立一个.aspx文件(Web Forms),例如hovertree.aspx,在页面上加入一个ListBox代码如下:
<asp:ListBox runat="server" ID="lbKeleyiFolder" />
那么在页面上显示根目录子文件夹的代码如下:
string[] m_sub
- Eclipse程序员要掌握的常用快捷键
justjavac
javaeclipse快捷键ide
判断一个人的编程水平,就看他用键盘多,还是鼠标多。用键盘一是为了输入代码(当然了,也包括注释),再有就是熟练使用快捷键。 曾有人在豆瓣评
《卓有成效的程序员》:“人有多大懒,才有多大闲”。之前我整理了一个
程序员图书列表,目的也就是通过读书,让程序员变懒。 写道 程序员作为特殊的群体,有的人可以这么懒,懒到事情都交给机器去做,而有的人又可
- c++编程随记
lx.asymmetric
C++笔记
为了字体更好看,改变了格式……
&&运算符:
#include<iostream>
using namespace std;
int main(){
int a=-1,b=4,k;
k=(++a<0)&&!(b--
- linux标准IO缓冲机制研究
音频数据
linux
一、什么是缓存I/O(Buffered I/O)缓存I/O又被称作标准I/O,大多数文件系统默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,操作系统会将I/O的数据缓存在文件系统的页缓存(page cache)中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。1.缓存I/O有以下优点:A.缓存I/O使用了操作系统内核缓冲区,
- 随想 生活
暗黑小菠萝
生活
其实账户之前就申请了,但是决定要自己更新一些东西看也是最近。从毕业到现在已经一年了。没有进步是假的,但是有多大的进步可能只有我自己知道。
毕业的时候班里12个女生,真正最后做到软件开发的只要两个包括我,PS:我不是说测试不好。当时因为考研完全放弃找工作,考研失败,我想这只是我的借口。那个时候才想到为什么大学的时候不能好好的学习技术,增强自己的实战能力,以至于后来找工作比较费劲。我
- 我认为POJO是一个错误的概念
windshome
javaPOJO编程J2EE设计
这篇内容其实没有经过太多的深思熟虑,只是个人一时的感觉。从个人风格上来讲,我倾向简单质朴的设计开发理念;从方法论上,我更加倾向自顶向下的设计;从做事情的目标上来看,我追求质量优先,更愿意使用较为保守和稳妥的理念和方法。
&