spark python安装配置 (初学)
参考博客 https://blog.csdn.net/tyhj_sf/article/details/81907051
需要:jdk10.0、spark2.3.1、Hadoop2.7.7(与spark对应的版本)
JDK下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk10-downloads-4416644.html
spark下载地址:https://www.apache.org/dyn/closer.lua/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
Hadoop下载地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
1、首先安装pyspark包:
pip install py4j
pip install pyspark
2、安装JDK,并配置环境,我的安装位置为D:\Program Files\Java,接下来是环境配置:
(1)在系统变量中新建变量名JAVA_HOME,对应的是java的安装位置(我的是:D:\Program Files\Java\jdk-10.0.2),

(2)继续新建一个CLASSPATH变量,值为:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
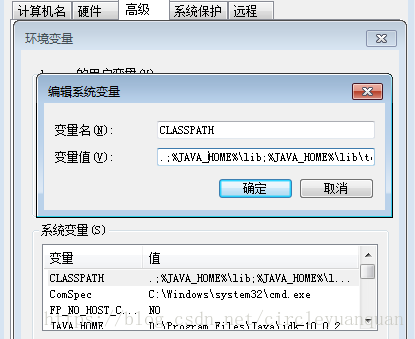
(3)在系统变量中找一个变量名为PATH的变量,在后面加:%JAVA_HOME%\bin;%JAVA_HOME%\jre-10.0.2\bin;
安装完毕,运行-》cmd-》分别输入java -version 与javac,如下所示,安装配置JDK成功。

3、安装spark
上述连接中spark2.3.1、Hadoop2.7.7均为免安装版,直接解压至安装目录即可。
(1)spark配置环境变量,在path中添加:D:\Program Files\spark-2.3.1-bin-hadoop2.7\bin;
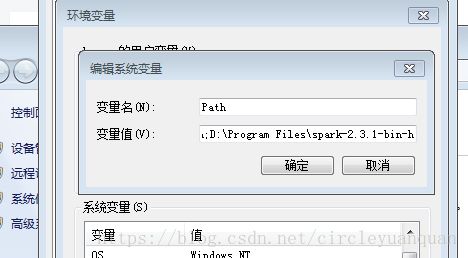
(2)Hadoop配置环境变量
新建HADOOP_HOME变量,值为:D:\Program Files\hadoop-2.7.7
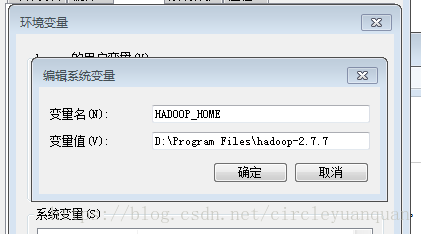
并在path中添加:%HADOOP_HOME%\bin;
同样在开始->运行->cmd->输入pyspark
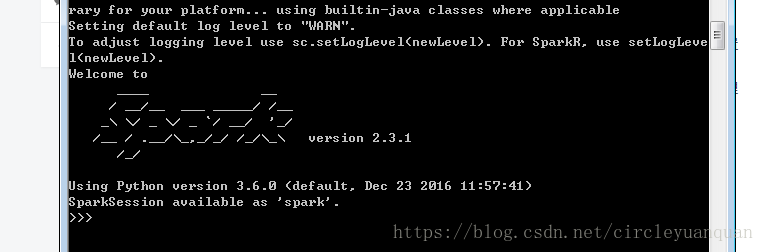
安装配置成功。
打开pycharm配置环境
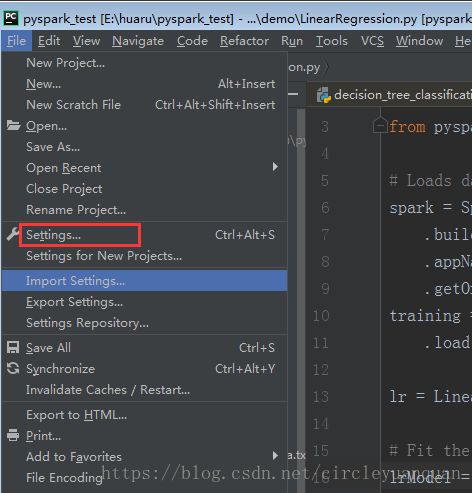

将pyspar和pyj4加包加载进去就好了。
这样就可以直接用了,千万不要作死用pip安装pyspark和pyj4,还有就是我的python的版本是3.5 ,不知道为什么3.6版本一直装不好。
安装完之后运行一个小小的程序测试一下:
from pyspark.ml.clustering import KMeans
from pyspark.sql import SparkSession
# Loads data.
spark = SparkSession \
.builder \
.appName("KMeansExample") \
.getOrCreate()
dataset = spark.read.format("libsvm").load("E:\pyspark_test\data\sample_kmeans_data.txt")
# Trains a k-means model.
kmeans = KMeans(featuresCol="features", k=2, maxIter=20, seed=None)
model = kmeans.fit(dataset)
# Evaluate clustering by computing Within Set Sum of Squared Errors.
wssse = model.computeCost(dataset)
print("Within Set Sum of Squared Errors = " + str(wssse))
# Shows the result.
centers = model.clusterCenters()
print("Cluster Centers: ")
for center in centers:
print(center)
最简单的聚类程序,数据集是自带的,在spark安装包里面的data文件夹中。
运行结果:

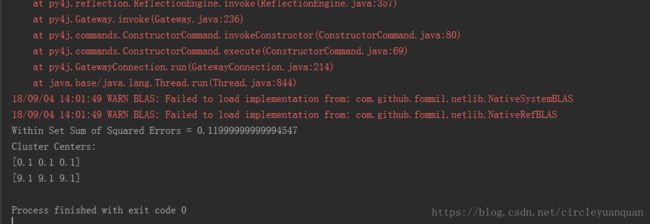
运行成功,中间的一大片红色的可以忽略不计,是因为没有安装Hadoop相关的包,因为本地开发也用不到。