- 在虚拟机上安装Hadoop
杜清卿
hadoop
基本步骤与安装java一致:先用finalshell将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面,然后解压,最后配置环境变量。1.使用finalshell上传。这里直接鼠标拖动操作即可。2.解压。进入到Hadoop安装包路径下,cd/opt/software/,再解压安装文件到/opt/module下,对应的命令是:tar-zxvfhadoop-.1.3
- hadoop集群配置-scp拓展使用
杜清卿
hadoop服务器大数据
任务1:在hadoop102上,将hadoop101中/opt/module/hadoop-3.1.3目录拷贝到hadoop102上。分析:使用scp进行拉取操作:先登录到hadoop2使用命令:scp-rroot@hadoop101:/opt/module/hadoop-3.1.3/opt/module/任务2:在hadoop101上操作,将hadoop100中/opt/module目录下所有目
- 大数据学习(75)-大数据组件总结
viperrrrrrr
大数据impalayarnhdfshiveCDHmapreduce
大数据学习系列专栏:哲学语录:用力所能及,改变世界。如果觉得博主的文章还不错的话,请点赞+收藏⭐️+留言支持一下博主哦一、CDHCDH(ClouderaDistributionIncludingApacheHadoop)是由Cloudera公司提供的一个集成了ApacheHadoop以及相关生态系统的发行版本。CDH是一个大数据平台,简化和加速了大数据处理分析的部署和管理。CDH提供Hadoop的
- Sqoop安装部署
愿与狸花过一生
大数据sqoophadoophive
ApacheSqoop简介Sqoop(SQL-to-Hadoop)是Apache开源项目,主要用于:将关系型数据库中的数据导入Hadoop分布式文件系统(HDFS)或相关组件(如Hive、HBase)。将Hadoop处理后的数据导出回关系型数据库。核心特性批量数据传输支持从数据库表到HDFS/Hive的全量或增量数据迁移。并行化处理基于MapReduce实现并行导入导出,提升大数据量场景的效率。自
- ssh命令
满分对我强制爱
linux服务器运维spark
ssh命令无需密码也可登录要先关闭防火墙,命令如下:systemctlstopfirewalldsystemctldisablefirewalldsystemctlstatusfirewalldeg:目标:hadoop100通过ssh访问hadoop101,hadoop102时不需要密码,其他两台设备也类似。具体操作如下:1.在hadoop100中生成公钥和密码。ssh-keygen-trsa三次
- Hive面试题
御风行云天
面试题大全hivehadoop数据仓库面试
Hive面试题1Hive基础概念1.1解释Hive是什么以及它的用途Hive的主要用途:1.2描述Hive架构和组件1.HiveCLI/Beeline和WebUI2.HiveQL3.HiveDriver(驱动)4.Metastore5.Compiler(编译器)6.Optimizer(优化器)7.Executor(执行器)8.HadoopCoreComponents(核心组件)9.HiveUDFs
- #Hadoop全分布式安装 #mysql安装 #hive安装
砸吧砸吧
hadoophiveyarnmysql
分布式(多台机器部署不同组件)与集群(多台机器部署相同组件)概念。Linux基础命令linux具有文件数:目录、文件,从根目录开始,路径具有唯一性。pwd:显示当前路径特殊符号:/:根目录.:隐藏文件,如果路径以.开始,表示当前目录下..:当前目录下的上一级~:当前目录的home目录--help:帮助命令使用linux常用操作命令tab键:自动补全ls:显示指定目录内容默认:当前路径-a:显示所有
- Hadoop(在Linux中安装jdk)
錠诗味
linuxhadoop运维
安装之前需准备:1.需要远程连接软件2.需要jdk3.需要准备两个文件夹01/export/software安装包02/export/servers解压文件夹现在正式开始安装1.将压缩包存放在/export/software目录下2.进入到software目录进行解压cd/export/software(切换目录)tar-zxvfjdk-8u202-linux-x64.tar.gz-C/expor
- 数据仓库和非结构化数据。
weixin_30631587
数据库
数据仓库包含标准化数据。还包含外部数据/非结构化数据如果外部数据量小可以保持数据库内部或者专用服务器。如果量大只能记住地址,在etl加载当然也有需求是实时数据比如股票汇率拿只能etl过程处理非结构化数据包含图片,视频音频如果是传统数据库db2oracle存在里面是不合适的。存储影响性能如果是hadoop无所谓影响不大,但是从使用者的角度非结构化数据只能转换关系使用建一张元数据表存储非结构化存储位置
- CentOS 7系统中hadoop的安装和环境配置
代码小张z
centoshadooplinux
1.创建Hadoop安装解压路径:mkdir-p/usr/hadoop2.进入路径:cd/usr/hadoop3.下载安装包(我这里用的是阿里云镜像压缩包):wgethttps://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz4.解压安装包到hadoop文件路径:tar-zxvf/usr/hadoo
- 尚硅谷电商数仓6.0,hive on spark,spark启动不了
新时代赚钱战士
hivesparkhadoop
在datagrip执行分区插入语句时报错[42000][40000]Errorwhilecompilingstatement:FAILED:SemanticExceptionFailedtogetasparksession:org.apache.hadoop.hive.ql.metadata.HiveException:FailedtocreateSparkclientforSparksessio
- Hadoop相关面试题
努力的搬砖人.
java面试hadoop
以下是150道Hadoop面试题及其详细回答,涵盖了Hadoop的基础知识、HDFS、MapReduce、YARN、HBase、Hive、Sqoop、Flume、ZooKeeper等多个方面,每道题目都尽量详细且简单易懂:Hadoop基础概念类1.什么是Hadoop?Hadoop是一个由Apache基金会开发的开源分布式计算框架,主要用于处理和存储大规模数据集。它提供了高容错性和高扩展性的分布式存
- Flink读取kafka数据并写入HDFS
王知无(import_bigdata)
Flink系统性学习专栏hdfskafkaflink
硬刚大数据系列文章链接:2021年从零到大数据专家的学习指南(全面升级版)2021年从零到大数据专家面试篇之Hadoop/HDFS/Yarn篇2021年从零到大数据专家面试篇之SparkSQL篇2021年从零到大数据专家面试篇之消息队列篇2021年从零到大数据专家面试篇之Spark篇2021年从零到大数据专家面试篇之Hbase篇
- Apache storm
赵世炎
stormhadoop
Apachestorm是一个分布式的实时大数据处理系统。用于在容错和水平可拓展方法中处理大量数据。它是一个流数据框架,具有很高的摄取率,无状态。通过zk管理分布式环境和集群状态,并行地对实时数据执行各种操作。storm易于设置和操作,并且它保证每个消息将通过拓扑至少处理一次。基本上Hadoop和Storm框架用于分析大数据。两者互补,在某些方面有所不同。ApacheStorm执行除持久性之外的所有
- 什么是Apache Avro?
maozexijr
apache
什么是ApacheAvro?ApacheAvro是一个开源的数据序列化框架,主要用于高效的数据交换和存储。它由ApacheHadoop项目开发,广泛应用于大数据生态系统中(如Hadoop、Kafka等)。Avro提供了一种紧凑、快速的二进制数据格式,同时支持丰富的数据结构和模式演化。核心特性跨语言支持Avro支持多种编程语言(如Java、Python、C++、Go等),使得不同语言之间的数据交换变
- 计算机毕业设计之基于Hadoop的热点新闻分析系统的设计与实现
微信bishe69
课程设计pythondjangomysql
近些年来,随着科技的飞速发展,互联网的普及逐渐延伸到各行各业中,给人们生活带来了十分的便利,热点新闻分析系统利用计算机网络实现信息化管理,使整个热点新闻分析的发展和服务水平有显著提升。本文拟采用PyCharm开发工具,django框架、Python语言、Hadoop大数据处理技术进行开发,后台使用MySQL数据库进行信息管理,设计开发的热点新闻分析系统。通过调研和分析,系统拥有管理员和用户两个模块
- Hadoop 实战笔记(二)-- HDFS 常用 shell 命令总结
dazhong2012
Hadoophdfshadoop
一、HDFS命令显示当前目录结构#显示当前目录结构hadoopfs-ls#递归显示当前目录结构hadoopfs-ls-R#显示根目录下内容hadoopfs-ls/创建目录#创建目录hadoopfs-mkdir#递归创建目录hadoopfs-mkdir-p删除操作#删除文件hadoopfs-rm#递归删除目录和文件hadoopfs-rm-R从本地加载文件到HDFS#二选一执行即可hadoopfs-p
- How Spark Read Sftp Files from Hadoop SFTP FileSystem
IT•轩辕
CloudyComputationsparkhadoop大数据
GradleDependenciesimplementation('org.apache.spark:spark-sql_2.13:3.5.3'){excludegroup:"org.apache.logging.log4j",module:"log4j-slf4j2-impl"}implementation('org.apache.hadoop:hadoop-common:3.3.4'){exc
- 中电金信25/3/18面前笔试(需求分析岗+数据开发岗)
苍曦
需求分析前端javascript
部分相同题目在第二次数据开发岗中不做解析,本次解析来源于豆包AI,正确与否有待商榷,本文只提供一个速查与知识点的补充。一、需求分析第1题,单选题,Hadoop的核心组件包括HDFS和以下哪个?MapReduceSparkStormFlink解析:Hadoop的核心组件是HDFS(分布式文件系统)和MapReduce(分布式计算框架)。Spark、Storm、Flink虽然也是大数据处理相关技术,但
- Spark集群启动与关闭
陈沐
sparksparkhadoopbigdata
Hadoop集群和Spark的启动与关闭Hadoop集群开启三台虚拟机均启动ZookeeperzkServer.shstartMaster1上面执行启动HDFSstart-dfs.shslave1上面执行开启YARNstart-yarn.shslave2上面执行开启YARN的资源管理器yarn-daemon.shstartresourcemanager(如果nodeManager没有启动(正常情况
- Hive函数大全:从核心内置函数到自定义UDF实战指南(附详细案例与总结)
一个天蝎座 白勺 程序猿
大数据开发从入门到实战合集hivehadoop数据仓库
目录背景一、Hive函数分类与核心函数表1.内置函数分类2.用户自定义函数(UDF)分类二、常用函数详解与实战案例1.数学函数2.字符串函数3.窗口函数4.自定义UDF实战三、总结与优化建议1.核心总结2.性能优化建议3.常问问题背景Hive作为Hadoop生态中最常用的数据仓库工具,其强大的函数库是高效处理和分析海量数据的核心能力之一。Hive函数分为内置函数和用户自
- Hadoop MapReduce 词频统计(WordCount)代码解析教程
我不是少爷.
Java基础hadoopmapreduce大数据
一、概述这是一个基于HadoopMapReduce框架实现的经典词频统计程序。程序会统计输入文本中每个单词出现的次数,并将结果输出到HDFS文件系统。二、代码结构packagecom.bigdata.wc;//Hadoop核心类库导入importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;//数据类型定义
- 从“笨重大象”到“敏捷火花”:Hadoop与Spark的大数据技术进化之路
Echo_Wish
大数据大数据hadoopspark
从“笨重大象”到“敏捷火花”:Hadoop与Spark的大数据技术进化之路说起大数据技术,Hadoop和Spark可以说是这个领域的两座里程碑。Hadoop曾是大数据的开山之作,而Spark则带领我们迈入了一个高效、灵活的大数据处理新时代。那么,它们的演变过程到底有何深意?背后技术上的取舍和选择,又意味着什么?一、Hadoop:分布式存储与计算的奠基者Hadoop诞生于互联网流量爆发式增长的时代,
- hadoop集群关闭命令顺序_启动和关闭Hadoop集群命令步骤
氪老师
hadoop集群关闭命令顺序
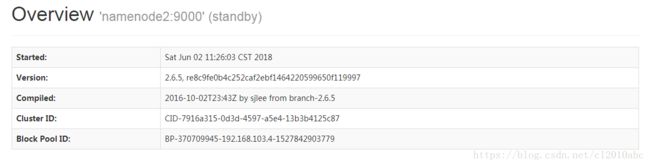
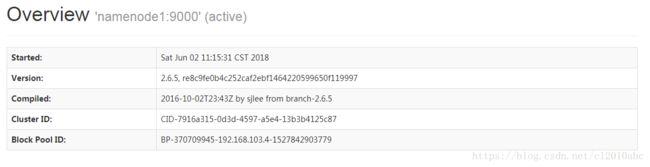
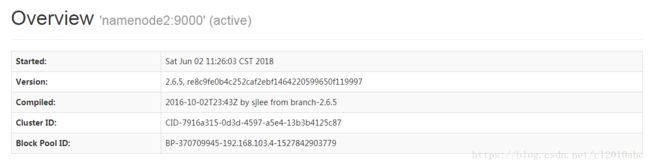
启动和关闭Hadoop集群命令步骤总结:1.在master上启动hadoop-daemon.shstartnamenode.2.在slave上启动hadoop-daemon.shstartdatanode.3.用jps指令观察执行结果.4.用hdfsdfsadmin-report观察集群配置情况.5.通过http://npfdev1:50070界面观察集群运行情况.(如果遇到问题看https://
- 在kali linux中配置hadoop伪分布式
we19a0sen
三数据分析分布式linuxhadoop
目录一.配置静态网络二.配置主机名与IP地址映射三.配置SSH免密登录四.配置Java和Hadoop环境五.配置Hadoop伪分布式六.启动与验证一.配置静态网络原因:Hadoop集群依赖稳定的网络通信,动态IP可能导致节点失联。静态IP确保节点始终通过固定地址通信。操作步骤:#修改网络配置文件sudovim/etc/network/interfaces#添加内容(根据实际网络修改):autoet
- Spark任务读取hive表数据导入es
小小小小小小小小小小码农
hiveelasticsearchsparkjava
使用elasticsearch-hadoop将hive表数据导入es,超级简单1.引入pomorg.elasticsearchelasticsearch-hadoop9.0.0-SNAPSHOT2.创建sparkconf//spark参数设置SparkConfsparkConf=newSparkConf();//要写入的索引sparkConf.set("es.resource","");//es集
- hive-进阶版-1
数据牧马人
hivehadoop数据仓库
第6章hive内部表与外部表的区别Hive是一个基于Hadoop的数据仓库工具,用于对大规模数据集进行数据存储、查询和分析。Hive支持内部表(ManagedTable)和外部表(ExternalTable)两种表类型,它们在数据存储、管理方式和生命周期等方面存在显著区别。以下是内部表和外部表的主要区别:1.数据存储位置内部表:数据存储在Hive的默认存储目录下,通常位于HDFS(HadoopDi
- 大数据手册(Spark)--Spark安装配置
WilenWu
数据分析(DataAnalysis)大数据spark分布式
本文默认在zsh终端安装配置,若使用bash终端,环境变量的配置文件相应变化。若安装包下载缓慢,可复制链接到迅雷下载,亲测极速~准备工作Spark的安装过程较为简单,在已安装好Hadoop的前提下,经过简单配置即可使用。假设已经安装好了hadoop(伪分布式)和hive,环境变量如下JAVA_HOME=/usr/opt/jdkHADOOP_HOME=/usr/local/hadoopHIVE_HO
- 虚拟机中Hadoop集群NameNode进程缺失问题解析与解决
申朝先生
hadoop大数据分布式linux
目录问题概述问题分析解决办法总结问题概述在虚拟机中运行Hadoop集群时,通过执行jps命令检查进程时,发现NameNode进程缺失。这通常会导致Hadoop集群无法正常运行,影响数据的存储和访问。问题分析导致NameNode进程缺失的原因可能有以下几点:集群未正确停止:在关闭虚拟机或重启Hadoop集群之前,未执行stop-all.sh命令正确停止集群,导致Hadoop服务异常退出,留下残留数据
- 大数据学习(67)- Flume、Sqoop、Kafka、DataX对比
viperrrrrrr
大数据学习flumekafkasqoopdatax
大数据学习系列专栏:哲学语录:用力所能及,改变世界。如果觉得博主的文章还不错的话,请点赞+收藏⭐️+留言支持一下博主哦工具主要作用数据流向实时性数据源/目标应用场景Flume实时日志采集与传输从数据源到存储系统实时日志文件、网络流量等→HDFS、HBase、Kafka等日志收集、实时监控、实时分析Sqoop关系型数据库与Hadoop间数据同步关系型数据库→Hadoop生态系统(HDFS、Hive、
- java数字签名三种方式
知了ing
javajdk
以下3钟数字签名都是基于jdk7的
1,RSA
String password="test";
// 1.初始化密钥
KeyPairGenerator keyPairGenerator = KeyPairGenerator.getInstance("RSA");
keyPairGenerator.initialize(51
- Hibernate学习笔记
caoyong
Hibernate
1>、Hibernate是数据访问层框架,是一个ORM(Object Relation Mapping)框架,作者为:Gavin King
2>、搭建Hibernate的开发环境
a>、添加jar包:
aa>、hibernatte开发包中/lib/required/所
- 设计模式之装饰器模式Decorator(结构型)
漂泊一剑客
Decorator
1. 概述
若你从事过面向对象开发,实现给一个类或对象增加行为,使用继承机制,这是所有面向对象语言的一个基本特性。如果已经存在的一个类缺少某些方法,或者须要给方法添加更多的功能(魅力),你也许会仅仅继承这个类来产生一个新类—这建立在额外的代码上。
- 读取磁盘文件txt,并输入String
一炮送你回车库
String
public static void main(String[] args) throws IOException {
String fileContent = readFileContent("d:/aaa.txt");
System.out.println(fileContent);
- js三级联动下拉框
3213213333332132
三级联动
//三级联动
省/直辖市<select id="province"></select>
市/省直辖<select id="city"></select>
县/区 <select id="area"></select>
- erlang之parse_transform编译选项的应用
616050468
parse_transform游戏服务器属性同步abstract_code
最近使用erlang重构了游戏服务器的所有代码,之前看过C++/lua写的服务器引擎代码,引擎实现了玩家属性自动同步给前端和增量更新玩家数据到数据库的功能,这也是现在很多游戏服务器的优化方向,在引擎层面去解决数据同步和数据持久化,数据发生变化了业务层不需要关心怎么去同步给前端。由于游戏过程中玩家每个业务中玩家数据更改的量其实是很少
- JAVA JSON的解析
darkranger
java
// {
// “Total”:“条数”,
// Code: 1,
//
// “PaymentItems”:[
// {
// “PaymentItemID”:”支款单ID”,
// “PaymentCode”:”支款单编号”,
// “PaymentTime”:”支款日期”,
// ”ContractNo”:”合同号”,
//
- POJ-1273-Drainage Ditches
aijuans
ACM_POJ
POJ-1273-Drainage Ditches
http://poj.org/problem?id=1273
基本的最大流,按LRJ的白书写的
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
#define INF 0x7fffffff
int ma
- 工作流Activiti5表的命名及含义
atongyeye
工作流Activiti
activiti5 - http://activiti.org/designer/update在线插件安装
activiti5一共23张表
Activiti的表都以ACT_开头。 第二部分是表示表的用途的两个字母标识。 用途也和服务的API对应。
ACT_RE_*: 'RE'表示repository。 这个前缀的表包含了流程定义和流程静态资源 (图片,规则,等等)。
A
- android的广播机制和广播的简单使用
百合不是茶
android广播机制广播的注册
Android广播机制简介 在Android中,有一些操作完成以后,会发送广播,比如说发出一条短信,或打出一个电话,如果某个程序接收了这个广播,就会做相应的处理。这个广播跟我们传统意义中的电台广播有些相似之处。之所以叫做广播,就是因为它只负责“说”而不管你“听不听”,也就是不管你接收方如何处理。另外,广播可以被不只一个应用程序所接收,当然也可能不被任何应
- Spring事务传播行为详解
bijian1013
javaspring事务传播行为
在service类前加上@Transactional,声明这个service所有方法需要事务管理。每一个业务方法开始时都会打开一个事务。
Spring默认情况下会对运行期例外(RunTimeException)进行事务回滚。这
- eidtplus operate
征客丶
eidtplus
开启列模式: Alt+C 鼠标选择 OR Alt+鼠标左键拖动
列模式替换或复制内容(多行):
右键-->格式-->填充所选内容-->选择相应操作
OR
Ctrl+Shift+V(复制多行数据,必须行数一致)
-------------------------------------------------------
- 【Kafka一】Kafka入门
bit1129
kafka
这篇文章来自Spark集成Kafka(http://bit1129.iteye.com/blog/2174765),这里把它单独取出来,作为Kafka的入门吧
下载Kafka
http://mirror.bit.edu.cn/apache/kafka/0.8.1.1/kafka_2.10-0.8.1.1.tgz
2.10表示Scala的版本,而0.8.1.1表示Kafka
- Spring 事务实现机制
BlueSkator
spring代理事务
Spring是以代理的方式实现对事务的管理。我们在Action中所使用的Service对象,其实是代理对象的实例,并不是我们所写的Service对象实例。既然是两个不同的对象,那为什么我们在Action中可以象使用Service对象一样的使用代理对象呢?为了说明问题,假设有个Service类叫AService,它的Spring事务代理类为AProxyService,AService实现了一个接口
- bootstrap源码学习与示例:bootstrap-dropdown(转帖)
BreakingBad
bootstrapdropdown
bootstrap-dropdown组件是个烂东西,我读后的整体感觉。
一个下拉开菜单的设计:
<ul class="nav pull-right">
<li id="fat-menu" class="dropdown">
- 读《研磨设计模式》-代码笔记-中介者模式-Mediator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/*
* 中介者模式(Mediator):用一个中介对象来封装一系列的对象交互。
* 中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
*
* 在我看来,Mediator模式是把多个对象(
- 常用代码记录
chenjunt3
UIExcelJ#
1、单据设置某行或某字段不能修改
//i是行号,"cash"是字段名称
getBillCardPanelWrapper().getBillCardPanel().getBillModel().setCellEditable(i, "cash", false);
//取得单据表体所有项用以上语句做循环就能设置整行了
getBillC
- 搜索引擎与工作流引擎
comsci
算法工作搜索引擎网络应用
最近在公司做和搜索有关的工作,(只是简单的应用开源工具集成到自己的产品中)工作流系统的进一步设计暂时放在一边了,偶然看到谷歌的研究员吴军写的数学之美系列中的搜索引擎与图论这篇文章中的介绍,我发现这样一个关系(仅仅是猜想)
-----搜索引擎和流程引擎的基础--都是图论,至少像在我在JWFD中引擎算法中用到的是自定义的广度优先
- oracle Health Monitor
daizj
oracleHealth Monitor
About Health Monitor
Beginning with Release 11g, Oracle Database includes a framework called Health Monitor for running diagnostic checks on the database.
About Health Monitor Checks
Health M
- JSON字符串转换为对象
dieslrae
javajson
作为前言,首先是要吐槽一下公司的脑残编译部署方式,web和core分开部署本来没什么问题,但是这丫居然不把json的包作为基础包而作为web的包,导致了core端不能使用,而且我们的core是可以当web来用的(不要在意这些细节),所以在core中处理json串就是个问题.没办法,跟编译那帮人也扯不清楚,只有自己写json的解析了.
- C语言学习八结构体,综合应用,学生管理系统
dcj3sjt126com
C语言
实现功能的代码:
# include <stdio.h>
# include <malloc.h>
struct Student
{
int age;
float score;
char name[100];
};
int main(void)
{
int len;
struct Student * pArr;
int i,
- vagrant学习笔记
dcj3sjt126com
vagrant
想了解多主机是如何定义和使用的, 所以又学习了一遍vagrant
1. vagrant virtualbox 下载安装
https://www.vagrantup.com/downloads.html
https://www.virtualbox.org/wiki/Downloads
查看安装在命令行输入vagrant
2.
- 14.性能优化-优化-软件配置优化
frank1234
软件配置性能优化
1.Tomcat线程池
修改tomcat的server.xml文件:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" maxThreads="1200" m
- 一个不错的shell 脚本教程 入门级
HarborChung
linuxshell
一个不错的shell 脚本教程 入门级
建立一个脚本 Linux中有好多中不同的shell,但是通常我们使用bash (bourne again shell) 进行shell编程,因为bash是免费的并且很容易使用。所以在本文中笔者所提供的脚本都是使用bash(但是在大多数情况下,这些脚本同样可以在 bash的大姐,bourne shell中运行)。 如同其他语言一样
- Spring4新特性——核心容器的其他改进
jinnianshilongnian
spring动态代理spring4依赖注入
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- Linux设置tomcat开机启动
liuxingguome
tomcatlinux开机自启动
执行命令sudo gedit /etc/init.d/tomcat6
然后把以下英文部分复制过去。(注意第一句#!/bin/sh如果不写,就不是一个shell文件。然后将对应的jdk和tomcat换成你自己的目录就行了。
#!/bin/bash
#
# /etc/rc.d/init.d/tomcat
# init script for tomcat precesses
- 第13章 Ajax进阶(下)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- Troubleshooting Crystal Reports off BW
blueoxygen
BO
http://wiki.sdn.sap.com/wiki/display/BOBJ/Troubleshooting+Crystal+Reports+off+BW#TroubleshootingCrystalReportsoffBW-TracingBOE
Quite useful, especially this part:
SAP BW connectivity
For t
- Java开发熟手该当心的11个错误
tomcat_oracle
javajvm多线程单元测试
#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为
- 正则表达式大全
yang852220741
html编程正则表达式
今天向大家分享正则表达式大全,它可以大提高你的工作效率
正则表达式也可以被当作是一门语言,当你学习一门新的编程语言的时候,他们是一个小的子语言。初看时觉得它没有任何的意义,但是很多时候,你不得不阅读一些教程,或文章来理解这些简单的描述模式。
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$