“知物由学”是网易云易盾打造的一个品牌栏目,词语出自汉·王充《论衡·实知》。人,能力有高下之分,学习才知道事物的道理,而后才有智慧,不去求问就不会知道。“知物由学”希望通过一篇篇技术干货、趋势解读、人物思考和沉淀给你带来收获的同时,也希望打开你的眼界,成就不一样的你。当然,如果你有不错的认知或分享,也欢迎通过邮件投稿 :[email protected]
导读:Facebook在过去一年面临了一系列令人眼花缭乱的指控和丑闻。Facebook CEO Mark Zuckerberg表示人工智能将帮助解决该公司平台上存在的问题,那么依靠人工智能真的能“治好”Facebook上的内容问题吗?
本文作者:Tom Simonitez;译者:陆小凤
2017年8月25日凌晨,缅甸罗兴亚穆斯林少数民族一个衣衫褴褛的叛乱组织袭击了该国西北部的军事哨所,造成12人死亡。安全部队迅速采取报复行动,焚烧村庄并进行了持续数周的大规模屠杀。随着罗兴亚有数千人死亡,缅甸军方领导人开始在Facebook上发帖。
这位总司令在一篇帖子中承诺要解决“孟加拉问题”,而这是对缅甸罗兴亚人的蔑称。另一位将军写了赞扬的话“为恢复地区和平所作的杰出努力”,并指出“种族不能被土地吞没,只能被另一个种族吞没。”同时联合国一份有关暴力事件的调查报告后来指出,总司令的帖子暗示了种族灭绝,并指出Facebook上的帖子在缅甸激起了对罗兴亚人的仇恨。代表团的主席告诉记者,该网站在这次危机中发挥了“决定性作用”。今年4月在美国国会,参议员Jeff Flake问Facebook首席执行官Mark Zuckerberg,他的公司如何才能避免扮演这一角色。这位33岁态度冷淡的亿万富翁指出,他雇佣了更多会说缅甸语的人。然后他阐述了他最喜欢的话题——人工智能。他表示:“从长期来看,构建人工智能工具将是一种可扩展的方式,能够识别并根除大部分此类有害内容。”在两天的国会听证会上,扎克伯格30多次提到人工智能。他对议员们说,人工智能将打击虚假新闻,防止具有种族或性别歧视的广告,并阻碍恐怖主义宣传。过去一年里,Facebook面临了一系列令人眼花缭乱的指控和丑闻。其中包括俄罗斯的选举干预、就业歧视,以及缅甸种族灭绝的“帮凶”。周一,参议院的一份报告称,俄罗斯在Facebook上的活动远远超过此前所知,并暗示该公司淡化了有关俄罗斯黑客利用其产品在2016年总统大选期间压低投票率的误导国会的说法。
Facebook的许多道歉表达了一个共同的主题:人工智能将帮助解决该公司平台上存在的问题。该公司首席技术官Mike Schroepfer表示,这项技术是防止坏人利用该产品的唯一途径。因为拥有23亿的常规用户,让所有的东西都由人工来审核将是一件恐怖而且代价很大的事情。Schroepfer说:“在我看来,人工智能是实现这一想法的最佳工具——我实际上不知道还有什么别的选择。”
依靠人工智能是一场赌博。事实证明,算法能够帮助监管Facebook,但它们远不是包治百病的灵丹妙药,或许永远也不是。该公司在检测和屏蔽色情和裸体方面取得了巨大成功,但是训练软件对文本进行可靠的解码比对图像进行分类要困难得多。为了在其庞大的平台上压制骚扰、仇恨言论和危险的阴谋论,Facebook需要能够理解100多种不同语言的细微差别的人工智能系统。任何不足之处都必须由Facebook约1.5万名人工评审员来审核,但就该社交网络的规模而言,尚不清楚他们的工作量将如何管理。正如缅甸发生的事件所显示的那样,对于那些正被Facebook塑造的世界的人来说, Menlo Park执法网络中看似微小的事情,对于那些正沉浸在Facebook塑造的世界的人来说,可能会感觉到极大的危险。
肉体探测器
Facebook对内容审核自动化的努力是由一位广告高管发起的,而不是网络言论方面的专家。2014年,Tanton Gibbs被聘为工程总监,从事广告技术方面的工作,此前他曾在微软和谷歌工作。在听到Facebook的审核挑战后,他建议采用一种更多算法优先的方法。Facebook采用了微软和达特茅斯学院开发的名为“PhotoDNA”的工具来屏蔽已知的儿童剥削图片,但没有在更广泛的范围内部署图像分析软件或人工智能。Tanton Gibbs说:“他们严格利用人类来审核诸如色情、仇恨言论或暴力图片之类的举报。我认为我们应该实现自动化。”于是Facebook任命Tanton Gibbs领导一个最初名为CareML的新团队,总部设在西雅图。
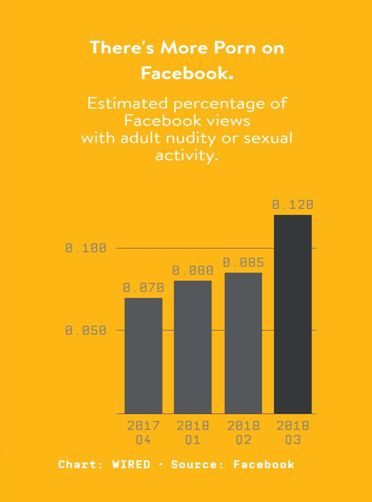
这个新团体很快证明了它的价值。Tanton Gibbs和他的工程师们采用了“深度学习”的技术,这是一种最近变得更加强大的用样本数据来训练算法的方法,谷歌在开发能够识别猫的软件时展示了这项技术的强大。Tanton Gibbs的小组则是安静的做着识别色情和裸体人类的深度学习算法。最初,该软件只是对Facebook用户举报的图片进行审核。一年半之后,Tanton Gibbs得到了允许,允许他的系统在任何人举报之前去审核新提交的内容。Facebook表示,96%的成人和裸照现在都是在任何人举报之前就被自动检测和删除的。
96%的数字看似很成功,但仍然有很多裸体图片和视频通过了Facebook的算法。2018年第三季度,他们删除了3080万张裸体或性行为的图片和视频:这意味着算法没有捕捉到130万张这样的图像。事实上,据Facebook估计,截止今年9月的12个月里,浏览裸体或色情内容的比例几乎翻了一番,达到每10000次浏览中约9次。Facebook在其最新的社区标准执行报告中表示:“Facebook上出现了更多的裸照,我们的系统未能及时捕捉到所有裸照去阻止浏览量的增长。”有很多信息被发现时可以看到的,但没有被发现或举报的信息量的大小是不可知的。
尽管如此,Tanton Gibbs在打击色情方面的成功,已经成为Facebook高管们最喜欢谈论的话题——人工智能在这方面很有潜力。这是一个有效的证据,证明了算法防御系统可以帮助Facebook用户免受有害内容的侵害,公司也可以免受托管内容的影响。Facebook表示,在最近三个月从该平台删除的仇恨言论中,略多于一半首先被算法标记出来,是今年早些时候比例的两倍多。大约15%因欺凌行为而被删除的帖子在没有人举报之前就被标记并删除了。不过,在另外的情况下算法不会直接删除帖子,它会标记出,由人工审核。
Facebook面临的挑战是如何让它的技术发挥足够好的作用,让大约15,000名内容审核人员可以在100多个国家/地区和服务使用的语言中轻松应对这一问题。
然而,Facebook人工智能内容审核技术在仇恨言论与欺凌上,无法达到像识别色情那样有效。深度学习算法很擅长将图像分类,如猫或汽车,色情或非色情。他们还使计算机在语言方面做得更好,使Alexa等虚拟助手成为可能,自动翻译的准确性也有了显著提高,但要像人类那样理解相对简单的文本还有很长的路要走。
解码语言
为了弄清楚一篇写着“我要打你”的帖子是威胁还是善意的玩笑,人工审核员可能会毫不费力地把它与附近篮球场的图像、或早期信息的措辞和语气联系起来。德克萨斯A&M大学教授黄瑞红表示:“目前一个模型如何能以这种方式利用上下文还不清楚。”今年秋天,在世界顶级语言处理研究会议上,她组织了一场学术研讨会,主题是利用算法对抗网络滥用。与2017年首次举办相比,出席人数和提交论文数量大约翻了一番,这并不是因为研究人员嗅到了胜利的气息。“许多公司和学术界人士都意识到这是一项重要的任务和问题,但到目前为止,进展并不令人满意,”黄瑞红说。“简而言之,目前的模型并不那么智能,这就是问题所在。”
Facebook应用机器学习小组的工程师Srinivas Narayanan对此表示赞同。他为他的团队在扫描色情和仇恨言论的系统上所做的工作感到骄傲,但是人类水平的准确性和细微差别仍然是一个遥远的目标。他表示:“我认为,我们仍远不能解决这一点。”“我认为机器最终能做到,但我们不知道如何做到。”
Facebook拥有一个大型跨国人工智能实验室,致力于长期的基础研究,或许有一天能帮助解开这个谜。现在也有记者、立法者、公民社会团体,甚至联合国,他们都期待能有所改善。Facebook的人工智能团队需要开发一些策略,以便在下一次丑闻爆发前取得有意义的进展。
推动实用新人工智能的产品包括今年发布的Rosetta系统,该系统可以读取嵌入图像和视频中的文本,并对其做仇恨言论检测(有证据表明,一些网络巨魔已经在测试欺骗它的方法)。另一个项目利用Instagram用户的数十亿个标签来改进Facebook的图像识别系统。该公司甚至利用Facebook上欺凌帖子的样本来训练一种人工智能网络欺凌,它生成文本生成器来推动其审核算法变得更好。
这些项目面临的一个重大挑战是,当今的机器学习算法必须经过狭隘而具体的数据训练。今年夏天,Facebook改变了一些内容审核员的工作方式,部分原因是为了产生更多仇恨言论有用训练数据。工作人员没有利用他们对Facebook规则的理解来直接决定是否删除一个标记为仇恨言论的帖子,而是回答一系列较为狭隘的问题。比如那篇文章有诽谤吗?它是否涉受保护的类别?这篇文章中是否有类别受到攻击了?Aashin Gautam领导了一个开发内容审核流程的团队,他说:“这种粒度标记让我们得到了非常令人兴奋的原始训练数据来构建分类器。”Facebook正在探索将这种新模式永久化,首先是针对仇恨言论,然后可能是针对其他类别的被禁内容。
在其他地方,Facebook正试图避免训练数据问题。负责全球运营的副总裁Justin Osofsky表示,缅甸发生的悲惨事件给我们上了一课,那就是该公司需要更好地利用人工和软件来理解不同市场的语言和文化。
对于Facebook来说,训练多种语言文本解码算法的传统方法极其昂贵。要发现英语中的生日祝福或仇恨言论,你需要千个样本,最好是数百万个样本。每次你想要扩展到一种新的语言,你都需要一组新的数据,这对Facebook这样规模的公司来说是一个重大挑战。
作为一种解决方案,Facebook正在调整为通用语言(如英语或西班牙语)构建的系统,以适用于较不常用的语言(如罗马尼亚语或马来语)。一种方法涉及使用自动翻译。Facebook已经能够通过将帖子转换成英语来抑制包括匈牙利语和希腊语中的clickbait(标题党),这样就可以将它们送入受过内容培训的clickbait探测器。它还可以通过翻译英语为不太常用的语言提供新的培训集。另一个项目涉及创建基于语言间深层相似性的多语言系统,这意味着一旦用英语训练任务,他们也可以立即用意大利语做同样的事情。Narayanan说:“这些多语言方法确实有助于我们加快将人工智能应用于跨语言完整性问题的能力。”
该项目还有助于说明Facebook面临挑战的规模。到目前为止,该公司的多语言变通方法还不能适用于公司拥有相对较小数据集(如缅甸语)的语言。豪萨语(Hausa)也面临着同样的挑战。豪萨语是西非一种用于反穆斯林仇恨言论的语言,当地警方上月告诉BBC,这种语言已导致十几起谋杀案。Facebook说,它正在扩大与尼日利亚事实核查组织和非政府组织的关系,并利用机器学习来标记仇恨言论和暴力图片。
被邀请展望未来时,Facebook首席技术官Mike Schroepfer承认,防止此类事件的发生是不可能的。他说:“我经常问自己的一个问题是,其他同样复杂的工作有100%的安全记录吗?”他说:“我想不出一个。飞机,汽车,太空旅行,执法。你知道有哪个城市的犯罪率是零吗?”
尽管如此,他对Facebook的发展道路仍持足够乐观的态度,想象有一天,它的算法会非常有效,欺凌和仇恨言论几乎消失了。
如果你是中小创业公司,在内容安全上觉得投入成本过高,无运营经验,也担心相关政策理解不到位,更担心投入了那么多没效果,那么你可以尝试用下易盾的内容安全业务。
点击一键接入专业的易盾内容安全解决方案。
相关文章:
【推荐】 [5.19 线下活动]Docker Meetup杭州站—拥抱Kubernetes,容器深度实践