机器人领域顶级会议 ICRA 2019 正在加拿大蒙特利尔举行(当地时间 5 月 20 日-24 日),刚刚大会公布了最佳论文奖项,来自斯坦福大学李飞飞组的研究《Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks》获得了最佳论文。

图源:https://twitter.com/animesh_garg/status/1131263955622604801
ICRA 最佳论文奖项设立于 1993 年,旨在表彰最优秀的论文。据了解,今年一共有三篇论文入围最佳论文奖项:
- 论文 1:Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks
- 作者:Michelle A. Lee, Yuke Zhu, Krishnan Srinivasan, Parth Shah, Silvio Savarese, Li Fei-Fei, Animesh Garg, Jeannette Bohg(斯坦福大学)
- 论文链接:https://arxiv.org/abs/1810.10191
- 论文 2:Deep Visuo-Tactile Learning: Estimation of Tactile Properties from Images
- 作者:Kuniyuki Takahashi, Jethro Tan(Preferred Networks 公司)
- 论文链接:https://arxiv.org/abs/1803.03435
- 论文 3:Variational End-to-End Navigation and Localization
- 作者:Alexander Amini, Guy Rosman, Sertac Karaman, Daniela Rus(MIT、丰田研究院)
- 论文链接:https://arxiv.org/abs/1811.10119
ICRA 最佳论文
其中,斯坦福大学 Michelle A. Lee、Yuke Zhu、李飞飞等人的论文《Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks》荣获最佳论文奖项。

摘要:在非结构化环境中执行需要大量接触的操纵任务通常需要触觉和视觉反馈。但是,手动设计机器人控制器使其结合具备不同特征的模态并不容易。尽管深度强化学习在学习高维输入的控制策略时获得了很大成功,但由于样本复杂度,这些算法通常很难在真实机器人上面部署。
该研究使用自监督学习感知输入的紧凑、多模态表征,然后使用这些表征提升策略学习的样本效率。研究者在植入任务上评估了该方法,结果表明该方法对于外部扰动具备稳健性,同时可以泛化至不同的几何、配置和间隙(clearances)。研究者展示了在模拟环境中和真实机器人上的结果。
该研究提出的多模态表征学习模型架构如下图所示:

图 2:利用自监督进行多模态表征学习的神经网络架构。该网络使用来自三个不同传感器的数据作为模型输入:RGB 图像、力矩传感器在 32ms 窗口上读取的力矩数据、末端执行器的位置和速度。该模型将这些数据编码并融合为多模态表征,基于这些多模态数据可学习用控制器执行需要大量接触的操纵。这一表征学习网络是通过自监督端到端训练得到的。
控制器设计
下图展示了该研究的控制器架构,该架构可分为三部分:轨迹生成、阻抗控制和操作空间控制。
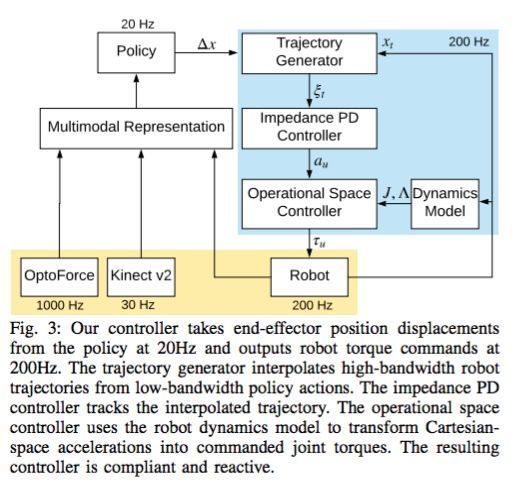
实验
下图展示了该模型在模拟环境中的训练。图 a 展示了 TRPO 智能体的训练曲线:

图 4:模拟植入任务:对基于不同感知模态数据训练得到的表征进行模型简化测试。研究者将使用结合了视觉、触觉和本体感觉的多模态表征训练得到的完整模型和未使用这些感知训练的基线模型进行了对比。b 图展示了使用不同反馈模态的部分任务完成率,其中视觉和触觉模态在接触丰富的任务中发挥不可或缺的作用。
下图展示了在真实环境中的模型评估。

图 5:a)在真实机器人实验及其间隙上使用 3D 打印 peg。b)定性预测:研究者对来自其表征模型的光流预测示例进行可视化。
下图展示了在真实机器人上对该模型的评估,同时展示了该模型在不同任务设置上的泛化效果。

最佳论文入围论文简介
另外两篇入围最佳论文的研究分别是来自日本 Preferred Networks 公司的《Deep Visuo-Tactile Learning: Estimation of Tactile Properties from Images》,以及来自 MIT 和丰田研究院的《Variational End-to-End Navigation and Localization》。
论文:Deep Visuo-Tactile Learning: Estimation of Tactile Properties from Images
摘要:基于视觉估计触觉特性(如光滑或粗糙)对与环境进行高效互动非常重要。这些触觉特性可以帮助我们决定下一步动作及其执行方式。例如,当我们发现牵引力不足时可以降低驾驶速度,或者如果某物看起来很光滑我们可以抓得更紧一些。
研究者认为这种能力也会帮助机器人增强对环境的理解,从而面对具体环境时选择恰当的行为。因此他们提出了一种模型,仅基于视觉感知估计触觉特性。该方法扩展了编码器-解码器网络,其中潜变量是视觉和触觉特征。
与之前的研究不同,该方法不需要手动标注,仅需要 RGB 图像及对应的触觉感知数据。所有数据都是通过安装在 Sawyer 机器人末端执行器上的网络摄像头和 uSkin 触觉感知器收集的,涉及 25 种不同材料的表面。研究者展示了该模型可以通过评估特征空间,泛化至未包含在训练数据中的材料,这表明该模型学会了将图像和重要的触觉特性关联起来。

该研究提出的网络架构图示。
论文:Variational End-to-End Navigation and Localization
摘要:深度学习彻底变革了直接从原始感知数据学习「端到端」自动车辆控制的能力。虽然最近在处理导航指令形式的扩展方面取得了一些进步,但这些研究还无法捕捉机器人所有可能动作的完整分布,也无法推断出机器人在环境中的定位。
在本文中,研究者扩展了能够理解地图的端到端驾驶网络。他们定义了一个新的变分网络,该网络能够根据环境的原始相机数据和更高级路线图进行学习,以预测可能的控制指令的完整概率分布,以及能够在地图内指定路线上导航的确定性控制指令。
此外,受人类驾驶员可以进行粗略定位的启发,研究者根据地图和观察到的视觉道路拓扑之间的对应关系,制定了如何使用其模型来定位机器人的方案。研究者在真实驾驶数据上评估了该算法,并推断了在不同类型的丰富驾驶场景下推断的转向命令的稳健性。另外,他们还在一组新的道路和交叉路口上评估了其定位算法,并展示了该模型在没有任何 GPS 先验的情况下也具备粗略定位的能力。

模型架构。
ICRA 其他奖项
除了最佳论文,ICRA 大会还设置了最佳学生论文,以及自动化、认知机器人、人机交互等分支的最佳论文。
其中获得最佳学生论文提名的研究有:
- 论文 1:Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience
- 作者:Yevgen Chebotar, Ankur Handa, Viktor Makoviichuk, Miles Macklin, Jan Isaac, Nathan Ratliff, Dieter Fox(英伟达、南加州大学、哥本哈根大学、华盛顿大学)
- 论文链接:https://arxiv.org/abs/1810.05687
- 论文 2:Online Multilayered Motion Planning with Dynamic Constraints for Autonomous Underwater Vehicles
- 作者:Eduard Vidal Garcia, Mark Moll, Narcis Palomeras, Juan David Hernández, Marc Carreras, Lydia Kavraki(西班牙赫罗纳大学水下机器人实验室、美国莱斯大学 Kavraki 实验室)
- 论文链接:http://www.kavrakilab.org/publications/vidal2019online-multilayered-motion-planning.pdf
- 论文 3:Drift-free Roll and Pitch Estimation for High-acceleration Hopping
- 作者:Justin K. Yim, Eric K. Wang, Ronald Fearing(加州大学伯克利分校)
- 论文链接:https://people.eecs.berkeley.edu/~ronf/PAPERS/jyim-icra2019.pdf