最近接到一个系统全面优化的工作,此系统从开发到运维到管理(服务器配置/架构/索引设计/日常维护)等等方面均非常优秀,在之前的一些文章中很少涉及深层次语句调优的方法和思路,那么今天补充一篇。
废话不多说 直接上思路步骤。
步骤一: 确定重点语句
此部分详细说明,请参见:Expert 诊断优化系列-------------针对重点语句调索引
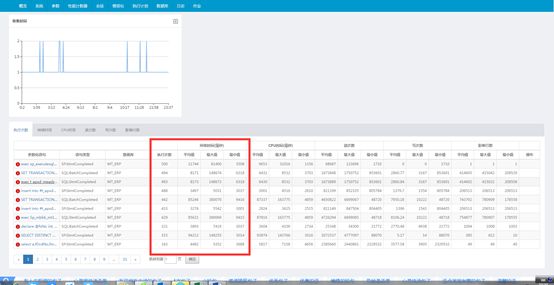
- l 在SQL专家云[全面诊断] –[慢语句]-[汇总视图](默认页) 中找到执行次数多的语句
- l 结合业务找出重点功能,针对性梳理调优
步骤二 : 重点语句调整思路(以下方法为递进方式)
注:以下思路适用于语句深度调优(已经规避低级设计或写法问题,具体内容请参见 :SQL SERVER全面优化-------写出好语句是习惯)
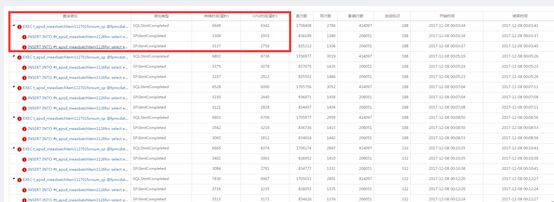
- l 在复杂存储过程中找出慢的部分(如图:存储过程整体执行6秒,主要消耗在2个高消耗子语句)
- l 观察语句基本运行情况是否索引缺失(针对重点语句调索引,请参见: Expert 诊断优化系列-------------针对重点语句调索引)
- l 定位语句运行中的阻塞与等待
在SQL专家云语句执行中观察所产生的等待,消除语句等待(此部分涉及的点较多,请参见 全面调优系列 SQL SERVER全面优化-------Expert for SQL Server 诊断系列)

- l 定位高开销
- n Set statistics io on 定位高逻辑读部分
- n 执行计划中高开销百分比
- n Hash join/merage join/nested join 表扫描/索引扫描次数
- l 没有明显缺失索引或以添加索引后,详细分析执行计划
- n 继续分析索引(消除key lookup,index/table spool 等)
- n 分析查询计划尝试使用查询提示(option 并行/并行度/连接方式/连接顺序等)
- l 分析语句复杂度及写法
- n 尽量较少表关联数量(1.执行计划稳定性 2.预估数量准确性 3.嵌套导致的多次扫描)
- n 视图/表值函数筛选条件应用(较少视图查询数据量)
- n 降低视图复杂度(多层视图嵌套且涉及数量量大无法根据条件筛选),降低由于复杂度导致的视图内表多次嵌套(hash join/ nested join)扫描
- 考虑使用高成本多字段覆盖索引
- 当语句复杂度高且受业务限制无法修改,则尝试使用多列覆盖索引来降低内层多次循环中的每次开销
- l 降低数据量与读写分离
- n 当语句复杂度高且受业务限制无法修改,可以考虑降低表数据量来减少每次扫描/嵌套开销等等
- n 读写分离,报表类大查询降低语句阻塞影响,非核心类查询分离等
步骤三 :保证执行计划稳定性
当上述优化都进行以后,要确保运行运行稳定,包含如下因素:
- l 统计信息
- l 索引碎片
- l 参数嗅探
- l 执行计划重编译
- l 2014以上版本的新参数估计
- l 其他多种因素
步骤四 :复杂过程中其他部分调优
- l 复杂过程的优化可能涉及集中情况
- n 过程中大量时间和消耗集中在1-2条语句,则针对性调优
- n 时间及消耗分布在多条语句,每条语句时间都不是很长,但整体步骤多,此时一般重点业务逐条优化,非重点业务优化循环类操作
- n 非逐条分析,整体环境提升如参数配置、索引全面解析
注 :此部分根据自身业务情况而定,无法给出标准套路
另附几篇较好的优化思路文章,供大家参考:
数据库优化案例——————某市中心医院HIS系统
30分钟带你熟练性能优化的那点儿事儿(案例说明)
SQL SERVER全面优化-------Expert for SQL Server 诊断系列
--------------博客地址---------------------------------------------------------------------------
诊断优化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
总结 : 语句的调优方法很多,内容很复杂,涉及到的点也很多,无法全部涉及,本文也许只是提供一个简单的思路供大家参考。
各有各的套路和方法,不喜勿喷!
优化无止境,且行且珍惜!
-----------------------------------------------------------------------------------------------------
注:此文章为原创,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,非常感谢!