2.2 Hadoop3.1.0完全分布式集群配置与部署
2.2 Hadoop3.1.0完全分布式集群配置与部署
开源地址 https://github.com/wangxiaoleiAI/big-data
卜算子·大数据 目录
开源“卜算子·大数据”系列文章、源码,面向大数据(分布式计算)的编程、应用、架构——每周更新!Linux、Java、Hadoop、Spark、Sqoop、hive、pig、hbase、zookeeper、Oozie、flink…etc
本节主要内容:
- 前提
- 你已经拥有了三台linux版大数据集群服务器
- 请看如何构建三台大数据集群服务器1.3.virtualbox高级应用构建本地大数据集群服务器
- Hadoop3.1.0最新版本完全分布式集群服务器的配置与部署
- 配置Java环境
- 配置免登陆
- 配置hadoop核心文件
- 格式化集群
- 开启集群
- 关闭集群

2.2.1 Java环境配置、安装
通过wget下载linux版jdk
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u172-b11/a58eab1ec242421181065cdc37240b08/jdk-8u172-linux-x64.tar.gzJava解压缩、移动到/opt/java/路径下
#解压
tar -zxf
# 移动至/opt/java 下
tar -zxf jdk-8u172-linux-x64.tar.gz
sudo mkdir -p /opt/java
sudo mv jdk1.8.0_172/ /opt/java/添加java环境变量
sudo vim /etc/profile.d/jdk-1.8.sh添加如下内容
#!/bin/sh
# Author:wangxiaolei 王小雷
# Github: https://github.com/wangxiaoleiai
export JAVA_HOME=/opt/java/jdk1.8.0_172
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATHJava环境变量生效
source /etc/profile查看Java
java -version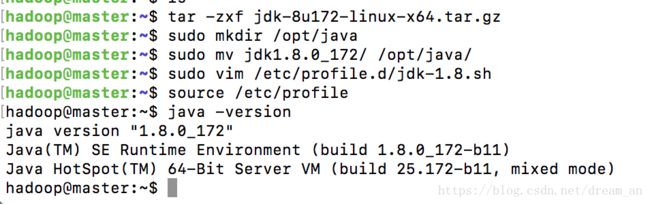
Java配置过程结束,按此依次配置其他服务器
2.2.2 免登陆配置
- 三台服务器操作
安装必要依赖
sudo apt install ssh
sudo apt install pdsh配置Keygen
# 输入以下命令,一路回车完成
ssh-keygen -t rsa修改hosts配置文件
sudo vim /etc/hosts
- Master主机服务器操作
master免密登录到worker中
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub worker1
ssh-copy-id -i ~/.ssh/id_rsa.pub worker2查看登录情况,此时不需要输入密码,就可以从Master登录到worker
ssh worker12.2.3 Hadoop核心文件配置
- 可以在本地修改好配置文件后,然后将Hadoop复制到集群服务器中。
- 也可以直接在服务器中修改,完成后然后复制到其他集群中。
- 核心文件共6个文件需要修改,分别是 hadoop-env.sh,core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml和workers。
下载hadoop3.1.0压缩包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.0/hadoop-3.1.0.tar.gztar -zxf hadoop-3.1.0.tar.gz
cd hadoop-3.1.0/etc/hadoop- 1.etc/hadoop/hadoop-env.sh
修改hadoop-env.sh文件
vim hadoop-env.sh添加如下内容
export JAVA_HOME=/opt/java/jdk1.8.0_172/- 2.etc/hadoop/core-site.xml
vim core-site.xml<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
configuration>- 3.etc/hadoop/hdfs-site.xml
vim hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>/var/lib/hadoop/hdfs/name/value>
property>
<property>
<name>dfs.blocksizename>
<value>268435456value>
property>
<property>
<name>dfs.namenode.handler.count name>
<value>100value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/var/lib/hadoop/hdfs/data/value>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>- 4.etc/hadoop/yarn-site.xml
vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>- 5.etc/hadoop/mapred-site.xml
vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.application.classpathname>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*value>
property>
configuration>- 6.etc/hadoop/workers
修改workers文件
vim workers删除原本的localhost,新增集群worker
worker1
worker22.2.4 将配置好的Hadoop文件发送到每一个集群
在master操作,master发送至worker1,worker2
scp -r hadoop-3.1.0 worker1:/home/hadoop/
scp -r hadoop-3.1.0 worker2:/home/hadoop/在三台主机中操作
sudo mkdir -p /opt/hadoop
sudo mv hadoop-3.1.0 /opt/hadoop/# 新建rcmd_default文件
# 设置rcmd_default入口,避免出现 master: rcmd: socket: Permission denied
sudo sh -c "echo "ssh" > /etc/pdsh/rcmd_default"2.2.5 Hadoop环境变量配置
在 三台 服务器上操作如下
- 设置环境的编码
sudo vim /etc/environment增加如下内容,解决Tab报错
LANG=en_US.utf-8
LC_ALL=en_US.utf-8- 设置Hadoop环境变量
sudo vim /etc/profile.d/hadoop-3.1.0.sh#!/bin/sh
# Author:wangxiaolei 王小雷
# Github: https://github.com/wangxiaoleiai
export HADOOP_HOME="/opt/hadoop/hadoop-3.1.0"
export PATH="$HADOOP_HOME/bin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoopsource /etc/profile2.2.6 Hadoop完全分布式集群格式化
在 三台 主机上操作:在hdfs-site.xml中指定的hdfs文件路径,先创建出来,并把root改为hadoop,使得hadoop有读写权限
sudo mkdir /var/lib/hadoop
sudo chown hadoop:hadoop /var/lib/hadoop/只在master上操作
cd /opt/hadoop/hadoop-3.1.0/
# 开始格式化
bin/hdfs namenode -format busuanzi
2.2.7 Hadoop完全分布式集群开启
开启所有HDFS进程
sbin/start-dfs.sh
# 查看
jps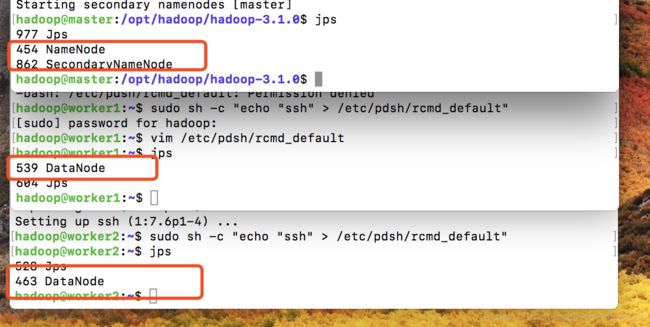
开启所有yarn进程
sbin/start-yarn.sh
# 查看
jps
开启
bin/mapred --daemon start historyserver
# 查看
jps最终集群如下图
2.2.8 通过web端查看
此处的web端集群情况查看的ip,为master的服务器ip。
1.ResourceManager http://192.168.56.106:8088/
2.NameNode http://192.168.56.106:9870/

3.MapReduce JobHistory Server http://192.168.56.106:19888/

2.2.9 Hadoop完全分布式集群关闭
在Master上操作
关闭HDFS进程
sbin/stop-dfs.sh关闭YARN
sbin/stop-yarn.sh关闭MapReduce JobHistory 服务
bin/mapred --daemon stop historyserver2.2.10 完全、干净、彻底删除集群【谨慎操作】
# 删除HDFS文件
sudo rm -rf /var/lib/hadoop
# 删除日志文件
sudo rm -rf /opt/hadoop/hadoop-3.1.0/logs/
# 删除hadoop文件
sudo rm -rf /opt/hadoop/hadoop-3.1.0/
# 删除hadoop环境变量
sudo rm -rf /etc/profile.d/hadoop-3.1.0.sh恭喜,至此,已经拥有了标准的完全分布式大数据集群环境了,你已经走进了大数据。开始探索大数据生态的奇妙之旅。一步一步来,大数据真没那么难。
开源地址:https://github.com/wangxiaoleiAI/big-data
大数据完整知识体系原创,请长按关注微信公众号【从入门到精通】,进群交流、获取一手更新资讯。
