Hadoop 二次排序
Hadoop 二次排序 八股文的样本例子
1、数据文本
[root@master IMFdatatest]#cat SecondarySort.txt
12 8
32 21
54 32
65 21
501 12
81 2
81 6
81 9
81 7
81 1
100 100
2、上传hdfs
[root@master IMFdatatest]#hadoop dfs -put SecondarySort.txt /libaray
3、编码
自定义IntPair ,放入两列值 重写比较
八股文定义好 SecondarySortGroupComparator MyPartitioner
4、hadoop 框架 自动排序key value
5、输出值,按字符串格式
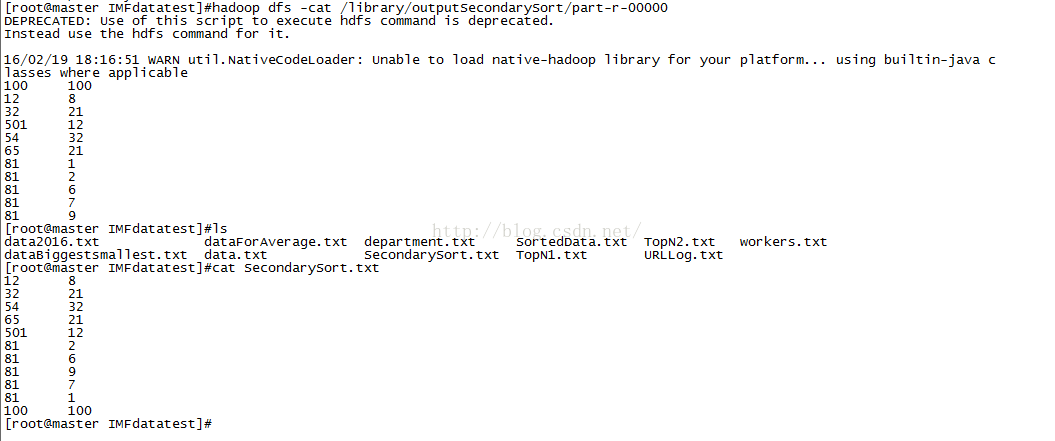
[root@master IMFdatatest]#hadoop dfs -cat /library/outputSecondarySort/part-r-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
16/02/19 18:16:51 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
100 100
12 8
32 21
501 12
54 32
65 21
81 1
81 2
81 6
81 7
81 9
6/原代码
package com.dtspark.hadoop.hellomapreduce;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class SecondarySort {
public static class DataMapper
extends Mapper
public void map(LongWritable key, Text value, Context context
) throws IOException, InterruptedException {
System.out.println("Map Methond Invoked!!!");
String line = value.toString();
String[] splited =line.split("\t");
IntPair item =new IntPair(splited[0],splited[1]);
context.write(item, value);
}
}
public static class DataReducer
extends Reducer
public void reduce(IntPair key, Iterable
Context context
) throws IOException, InterruptedException {
System.out.println("Reduce Methond Invoked!!!" );
for(Text item:values){
context.write(NullWritable.get(), item);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: SecondarySort
System.exit(2);
}
Job job = Job.getInstance(conf, "SecondarySort");
job.setJarByClass(SecondarySort.class);
job.setMapperClass(DataMapper.class);
job.setMapOutputKeyClass(IntPair.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(DataReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setPartitionerClass(MyPartitioner.class);
job.setGroupingComparatorClass(SecondarySortGroupComparator.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class SecondarySortGroupComparator extends WritableComparator {
public SecondarySortGroupComparator(){
super(IntPair.class,true);
}
}
class MyPartitioner extends Partitioner
@Override
public int getPartition(IntPair key, Text value, int numPartitioneS) {
// TODO Auto-generated method stub
return (key.hashCode() & Integer.MAX_VALUE) % numPartitioneS;
}
}
class IntPair implements WritableComparable
private String first;
private String Second;
public IntPair(){ }
public IntPair(String first, String second) {
this.first = first;
Second = second;
}
@Override
public void readFields(DataInput input) throws IOException {
// TODO Auto-generated method stub
this.first=input.readUTF();
this.Second=input.readUTF();
}
@Override
public void write(DataOutput output) throws IOException {
// TODO Auto-generated method stub
output.writeUTF(this.first);
output.writeUTF(this.Second);
}
@Override
public int compareTo(IntPair o) {
// TODO Auto-generated method stub
if (!this.first.equals(o.getFirst())){
return this.first.compareTo(o.first);
} else {
if (!this.Second.equals(o.Second)) {
return this.Second.compareTo(o.Second);
} else {
return 0;
}
}
}
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
public String getSecond() {
return Second;
}
public void setSecond(String second) {
Second = second;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((Second == null) ? 0 : Second.hashCode());
result = prime * result + ((first == null) ? 0 : first.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
IntPair other = (IntPair) obj;
if (Second == null) {
if (other.Second != null)
return false;
} else if (!Second.equals(other.Second))
return false;
if (first == null) {
if (other.first != null)
return false;
} else if (!first.equals(other.first))
return false;
return true;
}
}
图片