Spark Streaming 2.2.1 处理Kafka数据源的实战准备
Spark Streaming 2.2.1 处理Kafka数据源的实战准备
Kafka是一种高吞吐量的分布式发布订阅消息系统,Spark Streaming读取Kafka数据支持二种方式:Receiver方式和No Receivers方式。
(1)Receiver方式:Spark Streaming kafkautil使用createStream方法。
(2)No Receivers方式:Spark Streaming kafkautil使用createDirectStream方法。
目前No Receivers方式在企业中使用的越来越多,No Receivers方式具有更强的自由度控制、语义一致性。No Receivers方式更符合数据读取和数据操作,在生产环境中建议采用NoReceivers direct的方式。
(一) Kafka基础知识的准备。
发布消息通常有两种模式:队列模式(Queuing)和发布-订阅模式(Publish-Subscribe)。队列模式中,Consumers可以同时从服务端读取消息,每个消息只被其中一个Consumer读到;发布-订阅模式中消息被广播到所有的Consumer中。
Kafka的Topic的分区数,是Consumer可以读取的并行数的最高限制值,这里对应Spark Streaming并行读取(Read Parallelisms)的最大值。
当Consumer使用相同的GroupId去读取同一个Topic数据时,该Topic会将分区数据分发到各个Consumer,即队列模式的消息发布模式;如果Consumer使用不同的GroupID去读取同一个Topic数据时,该Topic的分区数据会广播到各个Consumer上,即使用广播的消息发布模式。
(二) Kafka集群的准备
ApacheKafka是一个发布-订阅消息分布式消息系统,提供分布式、分区、可复制的提交日志服务。Kafka项目提供新的消费者API接口Kafka 0.8版本、Kafka 0.10版本。对应Kafka的不同版本,SparkStreaming分别提供了2个对应的包,在分布式节点中需选择正确的包和所需的功能。注意:Kafka 0.8版本集成与0.9版本和0.10版本兼容,但Kafka 0.10版本与早期的节点不兼容。
Spark 系统中spark-streaming-kafka-0-8、spark-streaming-kafka-0-10两个不同包的比较,如表4-1所示。
兼容比较 |
spark-streaming-kafka-0-8 |
spark-streaming-kafka-0-10 |
Broker 版本 |
0.8.2.1 或更高 |
0.10.0 或更高 |
API的稳定性 |
稳定 |
试验性 |
语言支持 |
Scala, Java, Python |
Scala, Java |
Receiver Dstream |
是 |
否 |
Direct DStream |
是 |
是 |
SSL / TLS 支持 |
否 |
是 |
Offset 提交API |
否 |
是 |
动态主题订阅 |
否 |
是 |
表 4 - 1 Spark Kafka版本比较
Spark Streaming 2.2.1与 Kafka 0.8.2.1或更高版本兼容。
Scala有不同的发行版本(Scala 2.9.1 、Scala 2.9.2、Scala 2.10、Scala 2.11等),Kafka 0.8.2.1为Scala的多个版本构建了不同的Jar包,需选择对应的Jar包进行下载部署。如表 4-2所示。
序号 |
Kafka 0.8.2.1的Jar包 |
1 |
Scala 2.9.1 - kafka_2.9.1-0.8.2.1.tgz (asc, md5) |
2 |
Scala 2.9.2 - kafka_2.9.2-0.8.2.1.tgz (asc, md5) |
3 |
Scala 2.10 - kafka_2.10-0.8.2.1.tgz (asc, md5) |
4 |
Scala 2.11 - kafka_2.11-0.8.2.1.tgz (asc, md5) |
表 4 - 2 Kafka 0.8.2.1的Jar包
为了简化Kafka集群的搭建,集中针对Spark Streaming对Kafka流数据处理的实战上,这里以尽可能简单地方式构建Kafka集群。本节案例Scala使用2.11.12版本,SparkStreaming 使用2.2.1版本,这里Kafka使用kafka_2.11-0.8.2.1版本。
本案例构建Kafka集群,如表4-3所示。
IP地址 |
Hostname |
部署 |
192.168.189.1 |
Master |
kafka_2.11-0.8.2.1、zookeeper-3.4.6 |
192.168.189.2 |
Worker1 |
kafka_2.11-0.8.2.1、zookeeper-3.4.6 |
192.168.189.3 |
Worker2 |
kafka_2.11-0.8.2.1、zookeeper-3.4.6 |
Kafka简单搭建步骤如下:
1) 获取Kafka部署包,并解压到指定目录。
可以到Kafka的官方网站http://kafka.apache.org/downloads,下载部署包kafka_2.11-0.8.2.1.tgz到本地,然后通过WinScp工具将上Jar包上传到虚拟机Liunx系统的目录:
root@master:/usr/local/setup_tools#ls -ltr | grep kafka_2.11-0.8.2.1
-rw-r--r-- 1 rootroot 15771850 Feb 24 09:25kafka_2.11-0.8.2.1.tgz
root@master:/usr/local/setup_tools#
解压缩Jar包,复制到/usr/local/目录:
root@master:/usr/local/setup_tools#tar -zxvf kafka_2.11-0.8.2.1.tgz
……..
root@master:/usr/local/setup_tools# mvkafka_2.11-0.8.2.1 /usr/local/2) 配置Linux kafka_2.11-0.8.2.1的全局环境变量。
输入名称# vi /etc/profile打开profile文件,按i可以进入文本输入模式,在profile文件的最后增加KAFKA_HOME及修改PATH的环境变量,输入:wq!保存退出。
export KAFKA_HOME=/usr/local/kafka_2.11-0.8.2.1
exportPATH=.:$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:
$SPARK_HOME/bin:$HIVE_HOME/bin:$FLUME_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin
3) 环境变量配置生效。
在命令行中输入source /etc/profile,使刚才修改的KAFKA_HOME及PATH配置文件生效。
[root@master ~]#source /etc/profile
4) 修改Kafka集群中Master节点的配置文件server.properties。
root@master:/usr/local/kafka_2.11-0.8.2.1/config# viserver.properties
…..
# The id of the broker. This must be set to a uniqueinteger for each broker.
broker.id=0
……
# The port the socket server listens on
port=9092
……
# Hostname the broker will bind to. If not set, theserver will bind to all interfaces
host.name=master
……
# A comma seperated list of directories under which tostore log files
log.dirs=/tmp/kafka-logs
……
# Zookeeper connection string (see zookeeper docs fordetails).
zookeeper.connect=192.168.189.1:2181,192.168.189.2:2181,192.168.189.3:2181
修改相关的属性,当前可以只修改host.name、zookeeper.connect两个属性。
在server.properties配置文件中:
- broker.id属性:配置信息是服务的全局唯一标识,当前为第一个服务,因此直接使用,不做修改,整个Kafka中服务的broker.id值必须唯一不能重复;
- port属性:服务使用的端口号,如果是在单台机器上启动多个Broker服务,那么需要使用不同的端口号;
- log.dir属性:用于Kafka记录日志文件的目录,如果在单台机器上启动多个Broker服务的话,应该设置成不同目录,避免多个Broker服务在相同目录下生成目录文件。
5) 编写脚本将Kafka的Jar包及配置文件分发到Worker1、Worker2节点,并进行配置。
root@master:/usr/local/setup_scripts#vi kafka_2.11-0.8.2.1_distribute.sh
#!/bin/sh
for i in 2 3
do
scp -rq/usr/local/kafka_2.11-0.8.2.1 [email protected].$i:/usr/local/kafka_2.11-0.8.2.1
scp -rq/etc/profile [email protected].$i:/etc/profile
ssh [email protected].$i source /etc/profile
done
赋予kafka_2.11-0.8.2.1_distribute.sh执行权限,执行脚本文件。
root@master:/usr/local/setup_scripts# chmod u+x kafka_2.11-0.8.2.1_distribute.sh
root@master:/usr/local/setup_scripts#./kafka_2.11-0.8.2.1_distribute.sh
修改Worker1节点Kafka的配置文件server.properties的broker.id及host.name。
root@worker1:/usr/local/kafka_2.11-0.8.2.1/config#vi server.properties
……
# The id of the broker. This must be set to a uniqueinteger for each broker.
broker.id=1
……..
# Hostname the broker will bind to. If not set, theserver will bind to all interfaces
host.name=worker1
…….
修改Worker2节点Kafka的配置文件server.properties的broker.id及host.name。
root@worker2:/usr/local/kafka_2.11-0.8.2.1/config#vi server.properties
…….
# The id of the broker. This must be set to a uniqueinteger for each broker.
broker.id=2
…….
# Hostname the broker will bind to. If not set, theserver will bind to all interfaces
host.name=worker2
…….
6) 分别在Master、Worker1、Worker2节点,启用已部署的Zookeeper集群服务(Zookeeper部署不再赘述)。
root@master:~# zkServer.sh start
JMX enabled by default
Using config:/usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@master:~# zkServer.sh status
JMX enabled by default
Using config:/usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
……
root@worker1:~# zkServer.sh start
JMX enabled by default
Using config:/usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@worker1:~# zkServer.sh status
JMX enabled by default
Using config:/usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
……
root@worker2:~# zkServer.sh start
JMX enabled by default
Using config:/usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@worker2:~# zkServer.sh status
JMX enabled by default
Using config:/usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
启动后,Jps查看下进程,会出现Zookeeper的进程。
root@master:~# jps
3280 QuorumPeerMain
3344 Jps
其中,QuorumPeerMain对应启动的Zookeeper服务。
7) 分别在Master、Worker1、Worker2节点启动Kafka集群。
root@master:~# nohup/usr/local/kafka_2.11-0.8.2.1/bin/kafka-server-start.sh /usr/local/kafka_2.11-
0.8.2.1/config/server.properties &
[1] 3359
root@worker1:~# nohup/usr/local/kafka_2.11-0.8.2.1/bin/kafka-server-start.sh/usr/local/kafka_2.11-0.8.2.1/config/server.properties &
[2] 2861
root@worker2:~# nohup/usr/local/kafka_2.11-0.8.2.1/bin/kafka-server-start.sh/usr/local/kafka_2.11-0.8.2.1/config/server.properties &
[1] 2820
使用Jps命令查看。
root@master:~# jps
3280 QuorumPeerMain
3412 Jps
3359 Kafka
root@worker1:~# jps
2861 Kafka
2910 Jps
2799 QuorumPeerMain
root@worker2:~# jps
2757 QuorumPeerMain
2853 Jps其中,Kafka就是启动的broker服务的进程。
如果停止服务可以启动bin/kafka-server-stop.sh或直接kill -9 pid方式,但是,脚本方式会kill掉当前所有的Kafka服务(具体可以查看脚本命令)。因此,如果在单机上启动了多个服务(假设在Master节点需启动第二个新的Broker,可拷贝config/server.properties为config/server_1.properties,修改其中关键的三个属性(broker.id、port、log.dir),然后启动Broker服务),而只需要停止其中某一个时,应该选用Kill命令。
8) Kafka集群测试。创建Kafka的Topic,为了简化,这里使用一个Topic,输入创建命令。
root@master:/usr/local/kafka_2.11-0.8.2.1/bin#kafka-topics.sh --create --zookeeper
192.168.189.1:2181,192.168.189.2:2181,192.168.189.3:2181 --replication-factor 2 --partitions 4 --topickafka_test
Created topic "kafka_test".
root@master:/usr/local/kafka_2.11-0.8.2.1/bin#
创建名为kafka_test 的Topic,复制因子设为2,同时分区数为4,注意,分区数是read parallelisms的最大值。
查询Kafka当前的Topic信息,输入命令:
root@master:/usr/local/kafka_2.11-0.8.2.1/bin#kafka-topics.sh --list --zookeeper
192.168.189.1:2181,192.168.189.2:2181,192.168.189.3:2181--topic kafka_test
kafka_test
指定--zookeeper选项的值为192.168.189.1:2181,192.168.189.2:2181,192.168.189.3:2181,对应的Topic,即刚创建的kafka_test。
接下来使用spark-examples_2.11-2.2.1.jar自带的KafkaWordCount Examples例子测试Kafka消息的生产和消费。
9) 创建Kafka生产者Producer的提交脚本start-producer.sh:
#!/usr/bin/env bash
/usr/local/spark-2.2.1-bin-hadoop2.6/bin/spark-submit --master spark://192.168.189.1:7077 \
--deploy-mode client \
--driver-memory 1g \
--driver-cores 1 \
--total-executor-cores 3 \
--executor-memory 1g \
--jars /usr/local/kafka_2.11-0.8.2.1/libs/kafka-clients-0.8.2.1.jar \
--class org.apache.spark.examples.streaming.KafkaWordCountProducer \
/usr/local/streaming-examples-test/spark-examples_2.11-2.2.1.jar192.168.189.1:9092,192.168.189.2:9092,192.168.189.3:9092 \
kafka_test 20 10
在脚本start-producer.sh中需加上kafka-clients-0.8.2.1.jar的Jar包,否则会提示以下异常,找不到类KafkaProducer。
root@master:/usr/local/streaming-examples-test# start-producer.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/alluxio-1.7.0-hadoop-2.6/client/alluxio-1.7.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/spark-2.2.1-bin-hadoop2.6/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/kafka/clients/producer/KafkaProducer
at org.apache.spark.examples.streaming.KafkaWordCountProducer$.main(KafkaWordCount.scala:88)
at org.apache.spark.examples.streaming.KafkaWordCountProducer.main(KafkaWordCount.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:775)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:119)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.kafka.clients.producer.KafkaProducer
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 11 more
赋予start-producer.sh脚本执行权限。
root@master:/usr/local/streaming-examples-test#chmod u+x start-producer.sh
start-producer.sh脚本对应的KafkaWordCountProducer类的使用方法:
"Usage: KafkaWordCountProducer " + "
"
其中,参数metadataBrokerList的值为192.168.189.1:9092,192.168.189.2:9092,192.168.189.3:9092,即当前启动的Kafka服务(Broker列表,逗号分隔);参数Topic的值是刚才创建的Topic的名字kafka_test;参数messagesPerSec的值为20,即每个间隔时间发送的消息条数;参数wordsPerMessage的值为10,即每条消息中的单词个数。
启动start-producer.sh脚本,生产者向Kafka集群发送消息:
root@master:/usr/local/streaming-examples-test#start-producer.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in[jar:file:/usr/local/alluxio-1.7.0-hadoop-2.6/client/alluxio-1.7.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/spark-2.2.1-bin-hadoop2.6/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Seehttp://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.slf4j.impl.Log4jLoggerFactory]
18/02/24 14:33:07 INFO producer.ProducerConfig:ProducerConfig values:
compression.type = none
metric.reporters = []
metadata.max.age.ms = 300000
metadata.fetch.timeout.ms = 60000
acks = 1
batch.size= 16384
reconnect.backoff.ms = 10
bootstrap.servers = [192.168.189.1:9092, 192.168.189.2:9092,192.168.189.3:9092]
receive.buffer.bytes = 32768
retry.backoff.ms = 100
buffer.memory = 33554432
timeout.ms = 30000
key.serializer = classorg.apache.kafka.common.serialization.StringSerializer
retries = 0
max.request.size = 1048576
block.on.buffer.full = true
value.serializer = class org.apache.kafka.common.serialization.StringSerializer
metrics.sample.window.ms = 30000
send.buffer.bytes = 131072
max.in.flight.requests.per.connection = 5
metrics.num.samples = 2
linger.ms =0
client.id =
10) 创建Kafka消费者Consumer的提交脚本start-consumer.sh。
#!/usr/bin/env bash
/usr/local/spark-2.2.1-bin-hadoop2.6/bin/spark-submit --master spark://192.168.189.1:7077 \
--deploy-mode client \
--driver-memory 512m \
--driver-cores 1 \
--total-executor-cores 3 \
--executor-memory 512m \
--jars /usr/local/streaming-examples-test/spark-streaming-kafka-0-8-assembly_2.11-2.2.1.jar \
--class org.apache.spark.examples.streaming.KafkaWordCount \
/usr/local/streaming-examples-test/spark-examples_2.11-2.2.1.jar192.168.189.1:2181,192.168.189.2:2181,192.168.189.3:2181 \
group1 kafka_test 4
在脚本start-consumer.sh中需加上spark-streaming-kafka-0-8-assembly_2.11-2.2.1.jar的Jar包,否则会提示以下异常,找不到类KafkaUtils。
18/02/24 14:13:52INFO cluster.StandaloneSchedulerBackend: SchedulerBackend is ready for
scheduling beginning after reachedminRegisteredResourcesRatio: 0.0
Exception in thread "main"java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils$
…….
Caused by: java.lang.ClassNotFoundException:org.apache.spark.streaming.kafka.KafkaUtils$
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
atjava.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
赋予start-consumer.sh脚本执行权限。
root@master:/usr/local/streaming-examples-test#chmod u+x start-consumer.sh
该脚本对应的KafkaWordCountProducer类的使用方法:
“Usage: KafkaWordCount ”
其中,参数zkQuorum的值为:192.168.189.1:2181,192.168.189.2:2181,192.168.189.3:2181,即当前启动的Zookeeper连接属性(Host:port列表,逗号分隔);参数group的值是指定当前Consumer的groupId,这里设置为group1;参数Topics的值是kafka_test,即刚才创建的Topic的名字kafka_test;参数numThreads的值是4,即读取Kafka流的线程数,当前设置成分区数的个数,对应的每个线程读取一个分区数据。
启动start-consumer.sh脚本,Spark Streaming 2.2.1消费Kafka集群的消息,打印单词的计数信息:
……
18/02/24 14:34:59 INFO scheduler.DAGScheduler:ResultStage 440 (print at
KafkaWordCount.scala:61) finished in 0.046 s
18/02/24 14:34:59 INFO scheduler.DAGScheduler: Job 117finished: print at KafkaWordCount.scala:61, took 0.067648 s
-------------------------------------------
Time: 1519454092000 ms
-------------------------------------------
(4,1352)
(8,1327)
(6,1461)
(0,1451)
(2,1493)
(7,1365)
(5,1405)
(9,1398)
(3,1428)
(1,1520)
18/02/24 14:34:59 INFO scheduler.JobScheduler: Finishedjob streaming job 1519454092000 ms.0 from job set of time 1519454092000 ms
18/02/24 14:34:59 INFOscheduler.JobScheduler: Total delay: 7.238 s for time 1519454092000 ms(execution: 0.290 s)
…….
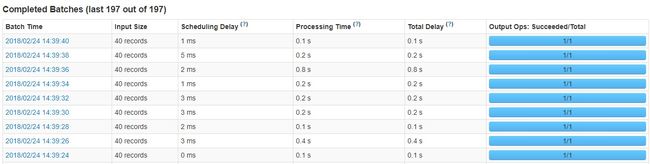
登陆SparkWeb UI页面(http://master:4040/streaming/),查看Spark Streaming 2.2.1 的运行情况,如图4-34,4-35所示。Spark Streaming 2.2.1处理的时间间隔为2秒,平均处理的Kafka消息条数为40条记录。这里在最初启动的时候有部分记录积压,之后消息消费平稳。
图 4 - 34 Spark Streaming消费kakfa消息图
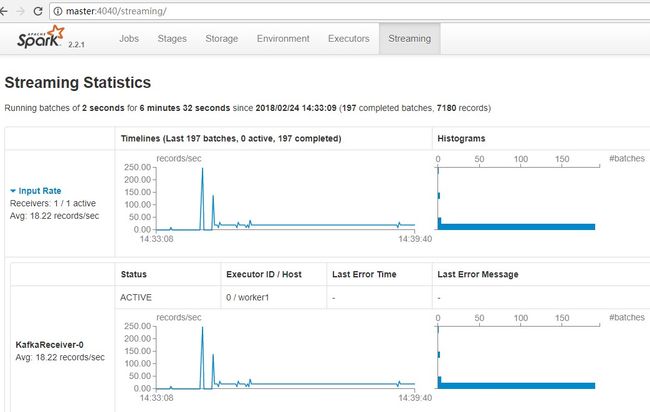
图 4 - 35 Spark Streaming消费kakfa消息记录情况
2018年新春报喜!热烈祝贺王家林大咖大数据经典传奇著作《SPARK大数据商业实战三部曲》畅销书籍 清华大学出版社发行上市!
本书基于Spark 2.2.0最新版本(2017年7月11日发布),以Spark商业案例实战和Spark在生产环境下几乎所有类型的性能调优为核心,以Spark内核解密为基石,分为上篇、中篇、下篇,对企业生产环境下的Spark商业案例与性能调优抽丝剥茧地进行剖析。上篇基于Spark源码,从一个动手实战案例入手,循序渐进地全面解析了Spark 2.2新特性及Spark内核源码;中篇选取Spark开发中最具有代表的经典学习案例,深入浅出地介绍,在案例中综合应用Spark的大数据技术;下篇性能调优内容基本完全覆盖了Spark在生产环境下的所有调优技术。
本书适合所有Spark学习者和从业人员使用。对于有分布式计算框架应用经验的人员,本书也可以作为Spark高手修炼的参考书籍。同时,本书也特别适合作为高等院校的大数据教材使用。
当当网、京东、淘宝、亚马逊等网店已可购买!欢迎大家购买学习!( Spark 内核部分透彻讲解Spark 2.2.0的源代码;Spark 案例部分详细讲解案例代码,新书案例部分每章都专门有1节列出案例全部的代码。如需代码拷贝复制,可加入家林大咖的QQ群 (418110145 DT大数据梦工厂),提供全部代码的下载。)
当当网址: http://product.dangdang.com/25230552.html